Comparative Analysis of MLP, CNN, and RNN Models in Automatic Speech Recognition: Dissecting Performance Metric
DOI:
https://doi.org/10.12928/biste.v5i4.9668Keywords:
Machine Learning, Deep Learning, Speaker Identification, MLP, CNN, RNNAbstract
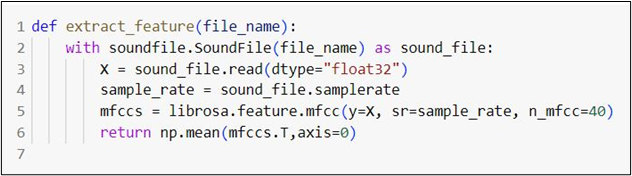
This study conducts a comparative analysis of three prominent machine learning models: Multi-Layer Perceptrons (MLP), Convolutional Neural Networks (CNN), and Recurrent Neural Networks (RNN) with Long Short-Term Memory (LSTM) in the field of automatic speech recognition (ASR). This research is distinct in its use of the LibriSpeech 'test-clean' dataset, selected for its diversity in speaker accents and varied recording conditions, establishing it as a robust benchmark for ASR performance evaluation. Our approach involved preprocessing the audio data to ensure consistency and extracting Mel-Frequency Cepstral Coefficients (MFCCs) as the primary features, crucial for capturing the nuances of human speech. The models were meticulously configured with specific architectural details and hyperparameters. The MLP and CNN models were designed to maximize their pattern recognition capabilities, while the RNN (LSTM) was optimized for processing temporal data. To assess their performance, we employed metrics such as precision, recall, and F1-score. The MLP and CNN models demonstrated exceptional accuracy, with scores of 0.98 across these metrics, indicating their effectiveness in feature extraction and pattern recognition. In contrast, the LSTM variant of RNN showed lower efficacy, with scores below 0.60, highlighting the challenges in handling sequential speech data. The results of this study shed light on the differing capabilities of these models in ASR. While the high accuracy of MLP and CNN suggests potential overfitting, the underperformance of LSTM underscores the necessity for further refinement in sequential data processing. This research contributes to the understanding of various machine learning approaches in ASR and paves the way for future investigations. We propose exploring hybrid model architectures and enhancing feature extraction methods to develop more sophisticated, real-world ASR systems. Additionally, our findings underscore the importance of considering model-specific strengths and limitations in ASR applications, guiding the direction of future research in this rapidly evolving field.
References
D. Sayers et al., “The Dawn of the Human-Machine Era: A forecast of new and emerging language technologies,” vol. 1, no. hal-03230287, 2021, https://doi.org/10.17011/jyx/reports/20210518/1.
Z. Lyu, “State-of-the-Art Human-Computer-Interaction in Metaverse,” Int. J. Human--Computer Interact., pp. 1–19, 2023, https://doi.org/10.1080/10447318.2023.2248833.
M. Schmitt and I. Flechais, “Digital Deception: Generative Artificial Intelligence in Social Engineering and Phishing,” arXiv Prepr. arXiv2310.13715, 2023, https://doi.org/10.2139/ssrn.4602790.
M. Sadaf et al., “Connected and Automated Vehicles: Infrastructure, Applications, Security, Critical Challenges, and Future Aspects,” Technologies, vol. 11, no. 5, p. 117, 2023, https://doi.org/10.3390/technologies11050117.
K. Ashok and S. Gopikrishnan, “Statistical Analysis of Remote Health Monitoring Based IoT Security Models & Deployments From a Pragmatic Perspective,” IEEE Access, vol. 11, pp. 2621–2651, 2023, https://doi.org/10.1109/ACCESS.2023.3234632.
A. A. F. Alshadidi et al., “Investigation on the Application of Artificial Intelligence in Prosthodontics,” Appl. Sci., vol. 13, no. 8, p. 5004, 2023, https://doi.org/10.3390/app13085004.
S. Ansari, K. A. Alnajjar, T. Khater, S. Mahmoud and A. Hussain, "A Robust Hybrid Neural Network Architecture for Blind Source Separation of Speech Signals Exploiting Deep Learning," in IEEE Access, vol. 11, pp. 100414-100437, 2023, https://doi.org/10.1109/ACCESS.2023.3313972.
Van Hedger, S. C., Nusbaum, H. C., Heald, S. L., Huang, A., Kotabe, H. P., & Berman, M. G. (2019). The aesthetic preference for nature sounds depends on sound object recognition. Cognitive science, 43(5), e12734, 2019, https://doi.org/10.1111/cogs.12734.
A. Giachanou, P. Rosso, and F. Crestani, F. (2021). The impact of emotional signals on credibility assessment. Journal of the Association for Information Science and Technology, 72(9), 1117-1132, 2021, https://doi.org/10.1002/asi.24480.
O. I. Abiodun et al., “Comprehensive review of artificial neural network applications to pattern recognition,” IEEE access, vol. 7, pp. 158820–158846, 2019, https://doi.org/10.1109/ACCESS.2019.2945545.
N. Singh and H. Sabrol, “Convolutional neural networks-an extensive arena of deep learning. A comprehensive study,” Arch. Comput. Methods Eng., vol. 28, no. 7, pp. 4755–4780, 2021, https://doi.org/10.1007/s11831-021-09551-4.
M. M. Rahman et al., “Prospective methodologies in hybrid renewable energy systems for energy prediction using artificial neural networks,” Sustainability, vol. 13, no. 4, p. 2393, 2021, https://doi.org/10.3390/su13042393.
S. Sun, Z. Cao, H. Zhu and J. Zhao, "A Survey of Optimization Methods From a Machine Learning Perspective," in IEEE Transactions on Cybernetics, vol. 50, no. 8, pp. 3668-3681, 2020, https://doi.org/10.1109/TCYB.2019.2950779.
J. Zhang, Z. Yin, P. Chen, and S. Nichele, “Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review,” Inf. Fusion, vol. 59, pp. 103–126, 2020, https://doi.org/10.1016/j.inffus.2020.01.011.
C. Hema and F. P. G. Marquez, “Emotional speech recognition using cnn and deep learning techniques,” Appl. Acoust., vol. 211, p. 109492, 2023, https://doi.org/10.1016/j.apacoust.2023.109492.
Y. Qian, R. Ubale, P. Lange, K. Evanini, V. Ramanarayanan, and F. K. Soong, “Spoken language understanding of human-machine conversations for language learning applications,” J. Signal Process. Syst., vol. 92, pp. 805–817, 2020, https://doi.org/10.1007/s11265-019-01484-3.
S. P. Yadav, S. Zaidi, A. Mishra, and V. Yadav, “Survey on machine learning in speech emotion recognition and vision systems using a recurrent neural network (RNN),” Arch. Comput. Methods Eng., vol. 29, no. 3, pp. 1753–1770, 2022, https://doi.org/10.1007/s11831-021-09647-x.
Y. Lin, D. Guo, J. Zhang, Z. Chen, and B. Yang, “A unified framework for multilingual speech recognition in air traffic control systems,” IEEE Trans. Neural Networks Learn. Syst., vol. 32, no. 8, pp. 3608–3620, 2020, https://doi.org/10.1109/TNNLS.2020.3015830.
A. Pervaiz et al., “Incorporating noise robustness in speech command recognition by noise augmentation of training data,” Sensors, vol. 20, no. 8, p. 2326, 2020, https://doi.org/10.3390/s20082326.
Z. Almutairi and H. Elgibreen, “A review of modern audio deepfake detection methods: challenges and future directions,” Algorithms, vol. 15, no. 5, p. 155, 2022, https://doi.org/10.3390/a15050155.
G. Dulac-Arnold, N. Levine, D. J. Mankowitz, J. Li, C. Paduraru, S. Gowal, and T. Hester, “Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,” Machine Learning, vol. 110, no. 9, pp. 2419-2468, 2021, https://doi.org/10.1007/s10994-021-05961-4.
Z. Xi et al., “The rise and potential of large language model based agents: A survey,” arXiv Prepr. arXiv2309.07864, 2023, https://doi.org/10.48550/arXiv.2309.07864.
H. Du et al., “Beyond deep reinforcement learning: A tutorial on generative diffusion models in network optimization,” arXiv Prepr. arXiv2308.05384, 2023, https://doi.org/10.48550/arXiv.2308.05384.
A. M. Deshmukh, “Comparison of hidden markov model and recurrent neural network in automatic speech recognition,” Eur. J. Eng. Technol. Res., vol. 5, no. 8, pp. 958–965, 2020, https://doi.org/10.24018/ejeng.2020.5.8.2077.
S. Mao, D. Tao, G. Zhang, P. C. Ching, and T. Lee, “Revisiting hidden Markov models for speech emotion recognition,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6715–6719, 2019, https://doi.org/10.1109/ICASSP.2019.8683172.
S. Adams and P. A. Beling, “A survey of feature selection methods for Gaussian mixture models and hidden Markov models,” Artif. Intell. Rev., vol. 52, pp. 1739–1779, 2019, https://doi.org/10.1007/s10462-017-9581-3.
Mustaqeem and S. Kwon, “A CNN-assisted enhanced audio signal processing for speech emotion recognition,” Sensors, vol. 20, no. 1, p. 183, 2019, https://doi.org/10.3390/s20010183.
Z. Tariq, S. K. Shah, and Y. Lee, “Feature-based fusion using CNN for lung and heart sound classification,” Sensors, vol. 22, no. 4, p. 1521, 2022, https://doi.org/10.3390/s22041521.
F. Demir, D. A. Abdullah, and A. Sengur, “A new deep CNN model for environmental sound classification,” IEEE Access, vol. 8, pp. 66529–66537, 2020, https://doi.org/10.1109/ACCESS.2020.2984903.
S. Das, A. Tariq, T. Santos, S. S. Kantareddy, and I. Banerjee, “Recurrent Neural Networks (RNNs): Architectures, Training Tricks, and Introduction to Influential Research,” Mach. Learn. Brain Disord., pp. 117–138, 2023, https://doi.org/10.1007/978-1-0716-3195-9_4.
A. Mehrish, N. Majumder, R. Bharadwaj, R. Mihalcea, and S. Poria, “A review of deep learning techniques for speech processing,” Inf. Fusion, p. 101869, 2023, https://doi.org/10.1016/j.inffus.2023.101869.
S. A. Syed, M. Rashid, S. Hussain, and H. Zahid, “Comparative analysis of CNN and RNN for voice pathology detection,” Biomed Res. Int., vol. 2021, pp. 1–8, 2021, https://doi.org/10.1155/2021/6635964.
I. A. Thukroo, R. Bashir, and K. J. Giri, “A review into deep learning techniques for spoken language identification,” Multimed. Tools Appl., vol. 81, no. 22, pp. 32593–32624, 2022, https://doi.org/10.1007/s11042-022-13054-0.
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Abraham K. S. Lenson, Gregorius Airlangga

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See The Effect of Open Access).

This journal is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

