Language as the Semantic Bridge in Audio, Music, and Multimodal Artificial Intelligence: A Systematic Review (2021-2025)
DOI:
https://doi.org/10.12928/biste.v8i2.15564Keywords:
Systematic Literature Review, PRISMA Framework, Audio and Music Artificial Intelligence, Natural Language Processing, Multimodal IntegrationAbstract
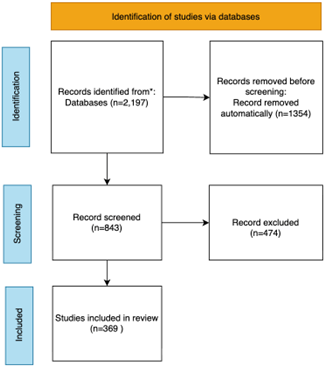
This study presents a systematic review of research in Audio, Music, and Multimodal Artificial Intelligence published between 2021 and 2025, investigating how language operates as a semantic mediation layer between acoustic signals and high-level meaning. The research addresses the fragmentation of existing surveys by introducing a Domain; Modality; Technique; Task (D-M-T-T) taxonomy that systematically differentiates domain focus, modality configuration, modeling techniques, and task objectives. The research contribution is a structured analytical framework that offers a more granular perspective than architecture-centered surveys of Multimodal Large Language Models. Following the PRISMA 2020 protocol, 2,197 Scopus-indexed publications were screened, yielding 369 eligible studies. Language is defined as a representational layer encompassing natural language and structured symbolic encodings that connect acoustic embeddings to semantic interpretation and generative reasoning. Multimodal systems aligning audio and vision without explicit textual grounding are included and analyzed as non-linguistic alignment architectures within the taxonomy. The findings reveal a shift from recognition-based models toward unified multimodal systems in which language conditions alignment, reasoning, and generative synthesis. For instance, text-conditioned music generation demonstrates how linguistic prompts guide compositional structure and emotional expression. These developments reflect an epistemic transition from signal recognition paradigms to language-mediated generative intelligence. Emerging gaps include limited explainability in generative audio systems and insufficient low-resource cross-modal semantic grounding.
References
K. Dabbabi and A. Mars, “Spoken Utterance Classification Task of Arabic Numerals and Selected Isolated Words,” Arab. J. Sci. Eng., vol. 47, no. 8, pp. 10731–10750, 2022, https://doi.org/10.1007/s13369-022-06649-0.
L. Betti, C. Abrate, and A. Kaltenbrunner, “Large scale analysis of gender bias and sexism in song lyrics,” EPJ Data Sci., vol. 12, no. 1, 2023, https://doi.org/10.1140/epjds/s13688-023-00384-8.
L. V Cuaya, R. Hernández-Pérez, M. Boros, A. Deme, and A. Andics, “Speech naturalness detection and language representation in the dog brain,” Neuroimage, vol. 248, 2022, https://doi.org/10.1016/j.neuroimage.2021.118811.
R. Gutierrez, J. C. Uhl, H. Schrom-Feiertag, and M. Tscheligi, “Integrating GPT-Based AI into Virtual Patients to Facilitate Communication Training Among Medical First Responders: Usability Study of Mixed Reality Simulation,” JMIR Form. Res., vol. 8, 2024, https://doi.org/10.2196/58623.
T. Ariga and Y. Hirose, “Recognition of spoken words with mispronounced lexical prosody in Japanese,” J. Acoust. Soc. Am., vol. 157, no. 6, pp. 4102–4118, 2025, https://doi.org/10.1121/10.0036775.
A. Derington, H. Wierstorf, A. G. Özkil, F. Eyben, F. Burkhardt, and B. W. Schuller, “Testing Correctness, Fairness, and Robustness of Speech Emotion Recognition Models,” IEEE Trans. Affect. Comput., vol. 16, no. 3, pp. 1929–1941, 2025, https://doi.org/10.1109/TAFFC.2025.3547218.
S. Yoo, H. Lee, J. I. Song, and O. Jeong, “A Korean emotion-factor dataset for extracting emotion and factors in Korean conversations,” Sci. Rep., vol. 13, no. 1, 2023, https://doi.org/10.1038/s41598-023-45386-8.
E. Jeong, G. Kim, and S. Kang, “Multimodal Prompt Learning in Emotion Recognition Using Context and Audio Information,” Mathematics, vol. 11, no. 13, 2023, https://doi.org/10.3390/math11132908.
Z. Mengesha, C. M. Heldreth, M. Lahav, J. Sublewski, and E. Tuennerman, “‘I don’t Think These Devices are Very Culturally Sensitive.’—Impact of Automated Speech Recognition Errors on African Americans,” Front. Artif. Intell., vol. 4, 2021, https://doi.org/10.3389/frai.2021.725911.
C. Wu, S. Le Vine, E. Bengel, J. Czerwinski, and J. W. Polak, “Sentiment analysis of popular-music references to automobiles, 1950s to 2010s,” Transportation (Amst)., vol. 49, no. 2, pp. 641–678, 2022, https://doi.org/10.1007/s11116-021-10189-1.
P. M. Lindborg, L. H. Lam, Y. C. Kam, and R. Yue, “Sensory Heritage Is Vital for Sustainable Cities: A Case Study of Soundscape and Smellscape at Wong Tai Sin,” Sustain., vol. 17, no. 16, 2025, https://doi.org/10.3390/su17167564.
Ö. Aydoǧmuş, M. C. Bingol, G. Boztas, and T. Tuncer, “An automated voice command classification model based on an attention-deep convolutional neural network for industrial automation system,” Eng. Appl. Artif. Intell., vol. 126, 2023, https://doi.org/10.1016/j.engappai.2023.107120.
A. Q. A. Hassan et al., “Integrating Applied Linguistics With Artificial Intelligence-Enabled Arabic Text-To-Speech Synthesizer,” Fractals, vol. 32, no. 9–10, 2024, https://doi.org/10.1142/S0218348X2540050X.
F. Jalali-Najafabadi, C. Gadepalli, D. Jarchi, and B. M. G. Cheetham, “Acoustic analysis and digital signal processing for the assessment of voice quality,” Biomed. Signal Process. Control, vol. 70, 2021, https://doi.org/10.1016/j.bspc.2021.103018.
A. H. El Fawal, A. Mansour, and A. Nasser, “Markov-Modulated Poisson Process Modeling for Machine-to-Machine Heterogeneous Traffic,” Appl. Sci., vol. 14, no. 18, 2024, https://doi.org/10.3390/app14188561.
N. Nixon, Y. Lin, and L. Snow, “Catalyzing Equity in STEM Teams: Harnessing Generative AI for Inclusion and Diversity,” Policy Insights from Behav. Brain Sci., vol. 11, no. 1, pp. 85–92, 2024, https://doi.org/10.1177/23727322231220356.
C. M. G. Villame and S. A. Guirnaldo, “Design and implementation of voice-command controller for fixed-wing unmanned aerial vehicles using automatic speech recognition and natural language processing techniques,” Sustain. Eng. Innov., vol. 6, no. 2, pp. 199–212, 2024, https://doi.org/10.37868/sei.v6i2.id309.
M. R. Islam, A. Ahmad, and M. S. Rahman, “Bangla text normalization for text-to-speech synthesizer using machine learning algorithms,” J. King Saud Univ. - Comput. Inf. Sci., vol. 36, no. 1, 2024, https://doi.org/10.1016/j.jksuci.2023.101807.
S. Baek, J. Kim, J. Lee, and M. Lee, “Implementation of a Virtual Assistant System Based on Deep Multi-modal Data Integration,” J. Signal Process. Syst., vol. 96, no. 3, pp. 179–189, 2024, https://doi.org/10.1007/s11265-022-01829-5.
S. J. I. Sam and K. Mohamed Jasim, “Hybridization of metaheuristics and NLP approach to examine public opinion towards virtual voice assistants,” Ann. Oper. Res., pp. 1-32, 2024, https://doi.org/10.1007/s10479-024-06105-2.
S. Dutta and J. H. Hansen, “Navigating the united states legislative landscape on voice privacy: Existing laws, proposed bills, protection for children, and synthetic data for ai,” arXiv preprint arXiv:2407.19677, 2024, https://doi.org/10.48550/arXiv.2407.19677.
Y. Wei et al., “Acoustic-based machine learning approaches for depression detection in Chinese university students,” Front. Public Heal., vol. 13, 2025, https://doi.org/10.3389/fpubh.2025.1561332.
D. Fernandes, S. Garg, M. Nikkel, and G. Guven, “A GPT-Powered Assistant for Real-Time Interaction with Building Information Models,” Buildings, vol. 14, no. 8, 2024, https://doi.org/10.3390/buildings14082499.
Z. Xu et al., “Depression detection methods based on multimodal fusion of voice and text,” Sci. Rep., vol. 15, no. 1, 2025, https://doi.org/10.1038/s41598-025-03524-4.
I. M. A. Shahin, A. B. Nassif, N. A. Al Hindawi, B. Alsabek, and N. A. AbuJabal, “Two-stage emotion recognition framework using CNN–transformer architecture and speaker cues,” Appl. Acoust., vol. 240, 2025, https://doi.org/10.1016/j.apacoust.2025.110963.
G. Chen, Z. Qian, S. Qiu, D. Zhang, and R. Zhou, “A gated leaky integrate-and-fire spiking neural network based on attention mechanism for multi-modal emotion recognition,” Digit. Signal Process. A Rev. J., vol. 165, 2025, https://doi.org/10.1016/j.dsp.2025.105322.
M. Alfaro-Contreras, J. M. Iñesta, and J. Calvo-Zaragoza, “Optical music recognition for homophonic scores with neural networks and synthetic music generation,” Int. J. Multimed. Inf. Retr., vol. 12, no. 1, 2023, https://doi.org/10.1007/s13735-023-00278-5.
L. Gong and X. J. Li, “Deepfake Voice Detection: An Approach Using End-to-End Transformer with Acoustic Feature Fusion by Cross-Attention,” Electron., vol. 14, no. 10, 2025, https://doi.org/10.3390/electronics14102040.
I. Carvalho, H. G. Gonçalo Oliveira and C. Silva, “The Importance of Context for Sentiment Analysis in Dialogues,” IEEE Access, vol. 11, pp. 86088–86103, 2023, https://doi.org/10.1109/ACCESS.2023.3304633.
M. Alfaro-Contreras and J. J. Valero-Mas, “Exploiting the two-dimensional nature of agnostic music notation for neural optical music recognition,” Appl. Sci., vol. 11, no. 8, 2021, https://doi.org/10.3390/app11083621.
Z. Dai, H. Zhou, Q. Ba, Y. Zhou, L. Wang, and G. Li, “Improving depression prediction using a novel feature selection algorithm coupled with context-aware analysis,” J. Affect. Disord., vol. 295, pp. 1040–1048, 2021, https://doi.org/10.1016/j.jad.2021.09.001.
N. Kumar and B. K. Baghel, “Intent Focused Semantic Parsing and Zero-Shot Learning for Out-of-Domain Detection in Spoken Language Understanding,” IEEE Access, vol. 9, pp. 165786–165794, 2021, https://doi.org/10.1109/ACCESS.2021.3133657.
A. Marijic and M. Bagic Babac, “Predicting song genre with deep learning,” Glob. Knowledge, Mem. Commun., vol. 74, no. 1–2, pp. 93–110, 2025, https://doi.org/10.1108/GKMC-08-2022-0187.
G. Chen, Z. Qian, D. Zhang, S. Qiu, and R. Zhou, “Enhancing Robustness Against Adversarial Attacks in Multimodal Emotion Recognition with Spiking Transformers,” IEEE Access, vol. 13, pp. 34584–34597, 2025, https://doi.org/10.1109/ACCESS.2025.3544086.
Y. Li et al., “Improving Text-Independent Forced Alignment to Support Speech-Language Pathologists with Phonetic Transcription,” Sensors, vol. 23, no. 24, 2023, https://doi.org/10.3390/s23249650.
M. M. Selim and M. S. Assiri, “Enhancing Arabic text-to-speech synthesis for emotional expression in visually impaired individuals using the artificial hummingbird and hybrid deep learning model,” Alexandria Eng. J., vol. 119, pp. 493–502, 2025, https://doi.org/10.1016/j.aej.2025.02.011.
S. Li and Y. Sung, “MRBERT: Pre-Training of Melody and Rhythm for Automatic Music Generation,” Mathematics, vol. 11, no. 4, 2023, https://doi.org/10.3390/math11040798.
D. Yook, G. Han, H. Chang, and I. Yoo, “CycleDiffusion: Voice Conversion Using Cycle-Consistent Diffusion Models,” Appl. Sci., vol. 14, no. 20, 2024, https://doi.org/10.3390/app14209595.
S. Jang and J. Lee, “User Intent-Based Music Generation Model Combining Actor-Critic Approach with MusicVAE,” IEEE Access, vol. 13, pp. 141281–141294, 2025, https://doi.org/10.1109/ACCESS.2025.3597741.
J. Min, Z. Liu, L. Wang, D. Li, M. Zhang, and Y. Huang, “Music Generation System for Adversarial Training Based on Deep Learning,” Processes, vol. 10, no. 12, 2022, https://doi.org/10.3390/pr10122515.
S. Lu and P. Wang, “Multi-dimensional fusion: transformer and GANs-based multimodal audiovisual perception robot for musical performance art,” Front. Neurorobot., vol. 17, 2023, https://doi.org/10.3389/fnbot.2023.1281944.
L. Comanducci, P. Bestagini, and S. Tubaro, “FakeMusicCaps: A Dataset for Detection and Attribution of Synthetic Music Generated via Text-to-Music Models,” J. Imaging, vol. 11, no. 7, 2025, https://doi.org/10.3390/jimaging11070242.
S. S. Reddy, S. K. Ahmad Mnoj, and K. P. Prasada Rao, “DNNT (Deep Neural Network for Telugu): a framework for speech recognition of Telugu language with parallel computing approach,” Int. J. Speech Technol., vol. 28, no. 2, pp. 341–349, 2025, https://doi.org/10.1007/s10772-025-10186-0.
Y. Zhao, Z. Xu, T. Zhang, M. Xie, B. Han, and Y. Liu, “Interactive Holographic Display System Based on Emotional Adaptability and CCNN-PCG,” Electron., vol. 14, no. 15, 2025, https://doi.org/10.3390/electronics14152981.
W. Kai and K. Xing, “Video-driven musical composition using large language model with memory-augmented state space,” Vis. Comput., vol. 41, no. 5, pp. 3345–3357, 2025, https://doi.org/10.1007/s00371-024-03606-w.
M. Ahmed, U. Rozario, M. M. Kabir, Z. Aung, J. Shin, and M. F. Mridha, “Musical Genre Classification Using Advanced Audio Analysis and Deep Learning Techniques,” IEEE Open J. Comput. Soc., vol. 5, pp. 457–467, 2024, https://doi.org/10.1109/OJCS.2024.3431229.
F. Zeng, “Multimodal music emotion recognition method based on multi data fusion,” Int. J. Arts Technol., vol. 14, no. 4, pp. 271–282, 2023, https://doi.org/10.1504/IJART.2023.133662.
V. S. G. S. P. Bottu and K. Ragavan, “Emotion-Based Music Recommendation System Integrating Facial Expression Recognition and Lyrics Sentiment Analysis,” IEEE Access, vol. 13, pp. 87740–87752, 2025, https://doi.org/10.1109/ACCESS.2025.3570011.
R. Phukan, N. Baruah, M. Neog, S. K. Sarma, and D. Konwar, “A Hybrid Neural-CRF Framework for Assamese Part-of-Speech Tagging,” IEEE Access, vol. 13, pp. 160476–160489, 2025, https://doi.org/10.1109/ACCESS.2025.3609572.
X. Liu et al., "Separate Anything You Describe," in IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 458-471, 2025, https://doi.org/10.1109/TASLP.2024.3520017.
A. Grgurevic and M. Bagic Babac, “Transformer-Based Approach for Solving Mathematical Problems Using Automatic Speech Recognition,” IEEE Access, vol. 13, pp. 79845–79859, 2025, https://doi.org/10.1109/ACCESS.2025.3564121.
D. Fernández-González, “Shift-Reduce Task-Oriented Semantic Parsing with Stack-Transformers,” Cognit. Comput., vol. 16, no. 6, pp. 2846–2862, 2024, https://doi.org/10.1007/s12559-024-10339-4.
J. Zhang, Z. Wang, J. Lai, and H. Wang, “GPTArm: An Autonomous Task Planning Manipulator Grasping System Based on Vision–Language Models,” Machines, vol. 13, no. 3, 2025, https://doi.org/10.3390/machines13030247.
A. S. Khatouni, N. Seddigh, B. Nandy, and null null, “Machine Learning Based Classification Accuracy of Encrypted Service Channels: Analysis of Various Factors,” J. Netw. Syst. Manag., vol. 29, no. 1, 2021, https://doi.org/10.1007/s10922-020-09566-5.
A. Sophia Koepke, A.-M. Oncescu, J. F. Henriques, Z. Akata, and S. Albanie, “Audio Retrieval with Natural Language Queries: A Benchmark Study,” IEEE Trans. Multimed., vol. 25, pp. 2675–2685, 2023, https://doi.org/10.1109/TMM.2022.3149712.
B. D. Killeen, S. Chaudhary, G. M. Osgood, and M. Unberath, “Take a shot! Natural language control of intelligent robotic X-ray systems in surgery,” Int. J. Comput. Assist. Radiol. Surg., vol. 19, no. 6, pp. 1165–1173, 2024, https://doi.org/10.1007/s11548-024-03120-3.
X. Mu and J. He, “Virtual Teacher-Aided Learning System Based on Voice Operated Character Animation,” Appl. Sci., vol. 14, no. 18, 2024, https://doi.org/10.3390/app14188177.
V. Brydinskyi, D. Sabodashko, Y. Khoma, M. A. Podpora, A. Konovalov, and V. V Khoma, “Enhancing Automatic Speech Recognition with Personalized Models: Improving Accuracy Through Individualized Fine-Tuning,” IEEE Access, vol. 12, pp. 116649–116656, 2024, https://doi.org/10.1109/ACCESS.2024.3443811.
S. Y. Ahn et al., “How do AI and human users interact? Positioning of AI and human users in customer service,” Text Talk, vol. 45, no. 3, pp. 301–318, 2025, https://doi.org/10.1515/text-2023-0116.
M. Jelassi, K. Matteli, H. Ben Khalfallah, and J. F. Demongeot, “Enhancing Personalized Mental Health Support Through Artificial Intelligence: Advances in Speech and Text Analysis Within Online Therapy Platforms,” Inf., vol. 15, no. 12, 2024, https://doi.org/10.3390/info15120813.
C. Qiang et al., "Learning Speech Representation from Contrastive Token-Acoustic Pretraining," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 10196-10200, 2024, https://doi.org/10.1109/ICASSP48485.2024.10447797.
K. Pothugunta, X. Liu, A. Susarla, and R. Padman, “Assessing inclusion and representativeness on digital platforms for health education: Evidence from YouTube,” J. Biomed. Inform., vol. 157, 2024, https://doi.org/10.1016/j.jbi.2024.104669.
Y. Yao, Z. Dai, and M. Shahbaz, “Integrating international Chinese visualization teaching and vocational skills training: leveraging attention-connectionist temporal classification models,” PeerJ Comput. Sci., vol. 10, 2024, https://doi.org/10.7717/PEERJ-CS.2223.
C. Gunasekara et al., “Overview of the Ninth Dialog System Technology Challenge: DSTC9,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 4066–4076, 2024, https://doi.org/10.1109/TASLP.2024.3426331.
T. HN, K. P. Gowda, R. J. R and A. J. L, "Empathy AI: Leveraging Emotion Recognition for Enhanced Human-AI Interaction," 2024 7th Asia Conference on Cognitive Engineering and Intelligent lnteraction (CEII), pp. 233-237, 2024, https://doi.org/10.1109/CEII65291.2024.00053.
K. Lim and J. Park, “Part-of-speech tagging using multiview learning,” IEEE Access, vol. 8, pp. 185184–195196, 2020, https://doi.org/10.1109/ACCESS.2020.3033979.
N. Ratnasari, A. P. Wibawa, and S. Patmanthara, “A digital hermeneutic analysis of linguistic musical meaning in generative AI using suno,” International Journal of Visual and Performing Arts, vol. 7, no. 2, 2025, https://doi.org/10.31763/viperarts.v7i2.2326.
S.-K. Choi, H.-C. Kwon, and M. Kim, “Combining Autoregressive Models and Phonological Knowledge Bases for Improved Accuracy in Korean Grapheme-to-Phoneme Conversion,” IEEE Access, vol. 13, pp. 107678–107693, 2025, https://doi.org/10.1109/ACCESS.2025.3581981.
. Sharma, A. Singh, S. Singh and G. Gupta, "AI-Powered Mock Interview Platform using Computer Vision, Natural Language Processing and Generative AI," 2025 3rd International Conference on Self Sustainable Artificial Intelligence Systems (ICSSAS), pp. 1258-1263, 2025, https://doi.org/10.1109/ICSSAS66150.2025.11080941.
B. Crowell, “Blockchain-based Metaverse Platforms: Augmented Analytics Tools, Interconnected Decision-Making Processes, and Computer Vision Algorithms,” Linguist. Philos. Investig., vol. 21, pp. 121–136, 2022, https://doi.org/10.22381/lpi2120228.
Supriyono, A. P. Wibawa, Suyono, and F. Kurniawan, “A survey of text summarization: Techniques, evaluation and challenges,” Nat. Lang. Process. J., vol. 7, no. April, p. 100070, 2024, https://doi.org/10.1016/j.nlp.2024.100070.
G. Badh and T. Knowles, “Acoustic and perceptual impact of face masks on speech: A scoping review,” PLoS One, vol. 18, no. 8 August, 2023, https://doi.org/10.1371/journal.pone.0285009.
P. Visutsak, J. Loungna, S. Sopromrat, C. Jantip, P. Soponkittikunchai, and X. Liu, “Mood-Based Music Discovery: A System for Generating Personalized Thai Music Playlists Using Emotion Analysis,” Appl. Syst. Innov., vol. 8, no. 2, 2025, https://doi.org/10.3390/asi8020037.
R. Griscom, J. A. Henry, D. Lee, R. P. Smiraglia, R. Szostak, and J. B. Young, “Classifying Musical Medium Of Performance: Object Or Property?,” Notes, vol. 80, no. 3, pp. 455–472, 2024, https://doi.org/10.1353/not.2024.a919032.
R. Flores, M. L. Tlachac, A. Shrestha, and E. A. Rundensteiner, “WavFace: A Multimodal Transformer-Based Model for Depression Screening,” IEEE J. Biomed. Heal. Informatics, vol. 29, no. 5, pp. 3632–3641, 2025, https://doi.org/10.1109/JBHI.2025.3529348.
Q. Wei, X. Huang, and Y. Zhang, “FV2ES: A Fully End2End Multimodal System for Fast Yet Effective Video Emotion Recognition Inference,” IEEE Trans. Broadcast., vol. 69, no. 1, pp. 10–20, 2023, https://doi.org/10.1109/TBC.2022.3215245.
M. F. Naaz, K. K. Goyal, and D. K. Alwani, “Explore the Integration of Multimodal Inputs with Facial Expressions for More Comprehensive Emotion Recognition,” Commun. Appl. Nonlinear Anal., vol. 31, no. 8s, pp. 651–670, 2024, https://doi.org/10.52783/cana.v31.1576.
B. Abibullaev, A. Keutayeva, and A. Zollanvari, “Deep Learning in EEG-Based BCIs: A Comprehensive Review of Transformer Models, Advantages, Challenges, and Applications,” IEEE Access, vol. 11, pp. 127271–127301, 2023, https://doi.org/10.1109/ACCESS.2023.3329678.
L. Pedrelli and X. Hinaut, “Hierarchical-Task Reservoir for Online Semantic Analysis from Continuous Speech,” IEEE Trans. Neural Networks Learn. Syst., vol. 33, no. 6, pp. 2654–2663, 2022, https://doi.org/10.1109/TNNLS.2021.3095140.
M. K. A. Aljero and N. Dimililer, “Genetic Programming Approach to Detect Hate Speech in Social Media,” IEEE Access, vol. 9, pp. 115115–115125, 2021, https://doi.org/10.1109/ACCESS.2021.3104535.
J. Khan, A. Alam, and Y. Lee, “Intelligent Hybrid Feature Selection for Textual Sentiment Classification,” IEEE Access, vol. 9, pp. 140590–140608, 2021, https://doi.org/10.1109/ACCESS.2021.3118982.
V. Sornlertlamvanich and S. Yuenyong, “Thai Named Entity Recognition Using BiLSTM-CNN-CRF Enhanced by TCC,” IEEE Access, vol. 10, pp. 53043–53052, 2022, https://doi.org/10.1109/ACCESS.2022.3175201.
T. Ashihara, M. Delcroix, Y. Ijima, and M. Kashino, “Unveiling the Linguistic Capabilities of a Self-Supervised Speech Model Through Cross-Lingual Benchmark and Layer-Wise Similarity Analysis,” IEEE Access, vol. 12, pp. 98835–98855, 2024, https://doi.org/10.1109/ACCESS.2024.3428364.
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in Vision: A Survey,” ACM Comput. Surv., vol. 54, no. 10, 2022, https://doi.org/10.1145/3505244.
C.-C. Wang, M.-Y. Day, and C.-L. Wu, “Political Hate Speech Detection and Lexicon Building: A Study in Taiwan,” IEEE Access, vol. 10, pp. 44337–44346, 2022, https://doi.org/10.1109/ACCESS.2022.3160712.
M. H. Asnawi, A. A. Pravitasari, T. Herawan, and T. Hendrawati, “The Combination of Contextualized Topic Model and MPNet for User Feedback Topic Modeling,” IEEE Access, vol. 11, pp. 130272–130286, 2023, https://doi.org/10.1109/ACCESS.2023.3332644.
G. Naif Alwakid, M. Humayun, and Z. Ahmad, “Transforming Disability Into Ability: An Explainable Vision-to-Voice Image Captioning Framework Using Transformer Models and Edge Computing,” IEEE Access, vol. 13, pp. 175212–175224, 2025, https://doi.org/10.1109/ACCESS.2025.3618646.
J. Gui, Z. Sun, Y. Wen, D. Tao, and J. Ye, “A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications,” IEEE Trans. Knowl. Data Eng., vol. 35, no. 4, pp. 3313–3332, 2023, https://doi.org/10.1109/TKDE.2021.3130191.
T. Tambe et al., “A 16-nm SoC for Noise-Robust Speech and NLP Edge AI Inference With Bayesian Sound Source Separation and Attention-Based DNNs,” IEEE J. Solid-State Circuits, vol. 58, no. 2, pp. 569–581, 2023, https://doi.org/10.1109/JSSC.2022.3179303.
M. R. Rajeswari and S. V Gangashetty, “Hybrid DNN-HMM-Based Approach for Telugu Language Speech Recognition,” IEEE Access, vol. 13, pp. 122752–122768, 2025, https://doi.org/10.1109/ACCESS.2025.3588664.
S. S. Malik et al., “Multi-Modal Emotion Detection and Sentiment Analysis,” IEEE Access, vol. 13, pp. 59790–59810, 2025, https://doi.org/10.1109/ACCESS.2025.3552475.
K. Mao et al., “Prediction of Depression Severity Based on the Prosodic and Semantic Features With Bidirectional LSTM and Time Distributed CNN,” IEEE Trans. Affect. Comput., vol. 14, no. 3, pp. 2251–2265, 2023, https://doi.org/10.1109/TAFFC.2022.3154332.
D.-W. Kim et al., “Automatic Assessment of Upper Extremity Function and Mobile Application for Self-Administered Stroke Rehabilitation,” IEEE Trans. Neural Syst. Rehabil. Eng., vol. 32, pp. 652–661, 2024, https://doi.org/10.1109/TNSRE.2024.3358497.
J. Zheng, H. Wang, and J. Yao, “Building Lightweight Domain-Specific Consultation Systems via Inter-External Knowledge Fusion Contrastive Learning,” IEEE Access, vol. 12, pp. 113244–113258, 2024, https://doi.org/10.1109/ACCESS.2024.3434648.
I. Hussain, M. R. Rizvi, Z. Abbas, A. N. Cheema, and I. M. Almanjahie, “MUST: An explainable AI–based framework for MUltilingual hate Speech deTection,” IEEE Access, 2025, https://doi.org/10.1109/ACCESS.2025.3629527.
A. Kukkar, R. Mohana, A. Sharma, A. Nayyar, and M. A. Shah, “Improving Sentiment Analysis in Social Media by Handling Lengthened Words,” IEEE Access, vol. 11, pp. 9775–9788, 2023, https://doi.org/10.1109/ACCESS.2023.3238366.
J. M. Molero, J. Pérez-Martín, A. Rodrigo, and A. Peñas, “Offensive Language Detection in Spanish Social Media: Testing from Bag-of-Words to Transformers Models,” IEEE Access, vol. 11, pp. 95639–95652, 2023, https://doi.org/10.1109/ACCESS.2023.3310244.
D. Suhartono, W. Wongso, and A. Tri Handoyo, “IdSarcasm: Benchmarking and Evaluating Language Models for Indonesian Sarcasm Detection,” IEEE Access, vol. 12, pp. 87323–87332, 2024, https://doi.org/10.1109/ACCESS.2024.3416955.
I. Hussain, R. Ahmad, S. Muhammad, K. Ullah, H. Shah, and A. Namoun, “PHTI: Pashto Handwritten Text Imagebase for Deep Learning Applications,” IEEE Access, vol. 10, pp. 113149–113157, 2022, https://doi.org/10.1109/ACCESS.2022.3216881.
F. Hasnat et al., “Understanding Sarcasm from Reddit texts using Supervised Algorithms,” in IEEE Region 10 Humanitarian Technology Conference, R10-HTC, pp. 1–6, 2022, https://doi.org/10.1109/R10-HTC54060.2022.9929882.
S. A. A. Ahmed, M. Awais, W. Wang, M. D. Plumbley, and J. Kittler, “ASiT: Local-Global Audio Spectrogram Vision Transformer for Event Classification,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 3684–3693, 2024, https://doi.org/10.1109/TASLP.2024.3428908.
J. Wang and J. Liu, “Voice Adversarial Sample Generation Method for Ultrasonicization of Motion Noise,” IEEE Access, vol. 12, pp. 177996–178009, 2024, https://doi.org/10.1109/ACCESS.2024.3506605.
W. Chen, X. Xing, X. Xu, J. Pang, and L. Du, “SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 31, pp. 775–788, 2023, https://doi.org/10.1109/TASLP.2023.3235194.
M. A. P. Putra et al., "Loss-Based Decentralized Federated Learning for Robust IoT Intrusion Detection System," 2024 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), pp. 119-123, 2024, https://doi.org/10.1109/IAICT62357.2024.10617474.
E. Ayetiran and O. Özgöbek, “A Review of Deep Learning Techniques for Multimodal Fake News and Harmful Languages Detection,” IEEE Access, vol. 12, pp. 76133–76153, 2024, https://doi.org/10.1109/ACCESS.2024.3406258.
Y. Patel et al., “Deepfake Generation and Detection: Case Study and Challenges,” IEEE Access, vol. 11, pp. 143296–143323, 2023, https://doi.org/10.1109/ACCESS.2023.3342107.
A. Hidayat, M. Sarifuddin, and null Hustinawaty, “Multi-Label Classification of Indonesian Voice Phishing Conversations: A Comparative Study of XLM-RoBERTa and ELECTRA,” J. Appl. Data Sci., vol. 6, no. 3, pp. 2177–2191, 2025, https://doi.org/10.47738/jads.v6i3.858.
F. T. Johora, R. Hasan, S. F. Farabi, M. Z. Alam, I. Sarkar and A. A. Mahmud, "AI Advances: Enhancing Banking Security with Fraud Detection," 2024 First International Conference on Technological Innovations and Advance Computing (TIACOMP), pp. 289-294, 2024, https://doi.org/10.1109/TIACOMP64125.2024.00055.
K. Sreelakshmi, B. Premjith, B. R. Chakravarthi, and K. P. Padannayil, “Detection of Hate Speech and Offensive Language CodeMix Text in Dravidian Languages Using Cost-Sensitive Learning Approach,” IEEE Access, vol. 12, pp. 20064–20090, 2024, https://doi.org/10.1109/ACCESS.2024.3358811.
K. Shuang, M. Gu, R. Li, J. Loo, and S. Su, “Interactive POS-aware network for aspect-level sentiment classification,” Neurocomputing, vol. 420, pp. 181–196, 2021, https://doi.org/10.1016/j.neucom.2020.08.013.
D. Aziz and D. Sztahó, “Multitask and Transfer Learning Approach for Joint Classification and Severity Estimation of Dysphonia,” IEEE J. Transl. Eng. Heal. Med., vol. 12, pp. 233–244, 2024, https://doi.org/10.1109/JTEHM.2023.3340345.
A. Willis, W. Portlock, S. J. Lee and H. -Y. Chang, "Home Automation, Voice, and Entry Network," 2025 Systems and Information Engineering Design Symposium (SIEDS), pp. 191-196, 2025, https://doi.org/10.1109/SIEDS65500.2025.11021198.
J. Liao, Y. Shi, and Y. Xu, “Automatic Speech Recognition Post-Processing for Readability: Task, Dataset and a Two-Stage Pre-Trained Approach,” IEEE Access, vol. 10, pp. 117053–117066, 2022, https://doi.org/10.1109/ACCESS.2022.3219838.
A. M. J. M. Z. Rahman, M. M. Kabir, M. F. Mridha, M. H. Alatiyyah, H. F. Alhasson, and S. S. Alharbi, “Arabic Speech Recognition: Advancement and Challenges,” IEEE Access, vol. 12, pp. 39689–39716, 2024, https://doi.org/10.1109/ACCESS.2024.3376237.
A.-H. Al-Ajmi and N. Al-Twairesh, “Building an Arabic Flight Booking Dialogue System Using a Hybrid Rule-Based and Data Driven Approach,” IEEE Access, vol. 9, pp. 7043–7053, 2021, https://doi.org/10.1109/ACCESS.2021.3049732.
Y.-C. Tsai and F.-C. Lin, “Paraphrase Generation Model Integrating Transformer Architecture, Part-of-Speech Features, and Pointer Generator Network,” IEEE Access, vol. 11, pp. 30109–30117, 2023, https://doi.org/10.1109/ACCESS.2023.3260849.
C. Tran and S. Sakti, "From Pixels to Voice: A Simple and Efficient End-to-End Spoken Image Description Approach via Vision Codec Language Models," ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5, 2025. https://doi.org/10.1109/ICASSP49660.2025.10890285.
V. Hassija, A. Chakrabarti, A. Singh, V. Chamola, and B. Sikdar, “Unleashing the Potential of Conversational AI: Amplifying Chat-GPT’s Capabilities and Tackling Technical Hurdles,” IEEE Access, vol. 11, pp. 143657–143682, 2023, https://doi.org/10.1109/ACCESS.2023.3339553.
S. Uruj, R. Goswami, S. D. Shetty, K. Kalaichelvi, and K. Karthikeyan, “Comparative Analysis of GPT-4 and LLaMA 3.2 Integration With Speech Processing Models for Enhancing Human–Robot Interaction and Motion Control in Real-World Applications,” IEEE Access, vol. 13, pp. 127170–127182, 2025, https://doi.org/10.1109/ACCESS.2025.3590592.
H. Ren et al., “F-NIRS-Based Dynamic Functional Connectivity Reveals the Innate Musical Sensing Brain Networks in Preterm Infants,” IEEE Trans. Neural Syst. Rehabil. Eng., vol. 30, pp. 1806–1816, 2022, https://doi.org/10.1109/TNSRE.2022.3178078.
E. Pusateri et al., "Retrieval Augmented Correction of Named Entity Speech Recognition Errors," ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5, 2025, https://doi.org/10.1109/ICASSP49660.2025.10888936.
K. Chauhan, K. K. Sharma, and T. Varma, “Multimodal Emotion Recognition Using Contextualized Audio Information and Ground Transcripts on Multiple Datasets,” Arab. J. Sci. Eng., vol. 49, no. 9, pp. 11871–11881, 2024, https://doi.org/10.1007/s13369-023-08395-3.
Z. Li, Z. Li, J. Zhang, Y. Feng, and J. Zhou, “Bridging Text and Video: A Universal Multimodal Transformer for Audio-Visual Scene-Aware Dialog,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 2476–2483, 2021, https://doi.org/10.1109/TASLP.2021.3065823.
Á. Gijón Flores, C. Bolaños Peño, H. Llumiguano Solano, J. Fernández-Bermejo Ruiz, F. Jesús Villanueva Molina and F. Rincón Calle, "From Voice to Shell: A SLM-Based Assistant for IoT Maintenance Tasks on the Edge," in IEEE Internet of Things Journal, vol. 13, no. 2, pp. 3000-3012, 2026, https://doi.org/10.1109/JIOT.2025.3632638.
J. A. Ovi, M. A. Islam, and M. R. Karim, “BaNeP: An End-to-End Neural Network Based Model for Bangla Parts-of-Speech Tagging,” IEEE Access, vol. 10, pp. 102753–102769, 2022, https://doi.org/10.1109/ACCESS.2022.3208269.
S. Singh and A. Mahmood, “The NLP Cookbook: Modern Recipes for Transformer Based Deep Learning Architectures,” IEEE Access, vol. 9, pp. 68675–68702, 2021, https://doi.org/10.1109/ACCESS.2021.3077350.
S. Sevim, S. İLhan Omurca, and E. Ekinci, “ParallelCVAE: A Parallel CVAE Mechanism for Multi-Turn Dialog Response Generation Model,” IEEE Access, vol. 13, pp. 189315–189328, 2025, https://doi.org/10.1109/ACCESS.2025.3628205.
T. Gu, H. Chen, C. Bin, L. Chang, and W. Chen, “Neighborhood Attentional Memory Networks for Recommendation Systems,” Sci. Program., vol. 2021, 2021, https://doi.org/10.1155/2021/8880331.
Z. Lin, J. He, Y. Zhao, R. Liang, H. Li, and Z. Wu, “EGRTE: adversarially training a self-explaining smoothed classifier for certified robustness,” Cybersecurity, vol. 8, no. 1, 2025, https://doi.org/10.1186/s42400-025-00375-4.
K. Yoshino et al., “Overview of the Tenth Dialog System Technology Challenge: DSTC10,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 765–778, 2024, https://doi.org/10.1109/TASLP.2023.3293030.
Á. L. Murciego, D. M. Jim, and N. Moreno-garc, “Context-Aware Recommender Systems in the Music Domain : A Systematic Literature Review,” Electronics, vol. 10, no. 13, p. 1555, 2021, https://doi.org/10.3390/electronics10131555.
J. Barnett, “The Ethical Implications of Generative Audio Models : A Systematic The Ethical Implications of Generative Audio Models : A Systematic Literature Review,” ACM Int. Conf. Proceeding Ser., pp. 146-161, 2026, https://doi.org/10.1145/3600211.3604686.
M. N. Hossain Khan, J. Li, N. L. McElwain, M. Hasegawa–Johnson and B. Islam, "Sound Tagging in Infant-centric Home Soundscapes," 2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), pp. 142-146, 2024, https://doi.org/10.1109/CHASE60773.2024.00023.
W. Budiharto et al., “Systematic Literature Review of The Use of Music Information Retrieval in Music Genre Classification,” Int. J. Comput. Sci. Humanit. AI, vol. 2, no. 1, pp. 2–4, 2025, https://doi.org/10.21512/ijcshai.v2i1.13019.
M. Shao, A. Basit, R. Karri, and M. Shafique, “Survey of Different Large Language Model Architectures: Trends, Benchmarks, and Challenges,” IEEE Access, vol. 12, pp. 188664–188706, 2024, https://doi.org/10.1109/ACCESS.2024.3482107.
J. Jiang, N. A. Teo, H. Pen, S. Ho, and Z. Wang, “Converting Vocal Performances into Sheet Music Leveraging Large Language Models,” in IEEE International Conference on Data Mining Workshops, ICDMW, pp. 445–452, 2024, https://doi.org/10.1109/ICDMW65004.2024.00063.
D. Pena, A. Aguilera, I. Dongo, J. Heredia, and Y. Cardinale, “A Framework to Evaluate Fusion Methods for Multimodal Emotion Recognition,” IEEE Access, vol. 11, pp. 10218–10237, 2023, https://doi.org/10.1109/ACCESS.2023.3240420.
J. Xue, Y. Deng, Y. Gao, and Y. Li, “Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 4700–4712, 2024, https://doi.org/10.1109/TASLP.2024.3485485.
S. Luz, F. Haider, D. Fromm, I. Lazarou, I. Kompatsiaris, and B. MacWhinney, “An Overview of the ADReSS-M Signal Processing Grand Challenge on Multilingual Alzheimer’s Dementia Recognition Through Spontaneous Speech,” IEEE Open J. Signal Process., vol. 5, pp. 738–749, 2024, https://doi.org/10.1109/OJSP.2024.3378595.
V. Ponzi and C. Napoli, “Graph Neural Networks: Architectures, Applications, and Future Directions,” IEEE Access, vol. 13, pp. 62870–62891, 2025, https://doi.org/10.1109/ACCESS.2025.3558752.
S. Biswas and G. Poornalatha, “Opinion Mining Using Multi-Dimensional Analysis,” IEEE Access, vol. 11, pp. 25906–25916, 2023, https://doi.org/10.1109/ACCESS.2023.3256521.
B. Wilkes, I. Vatolkin, and H. Müller, “Statistical and visual analysis of audio, text, and image features for multi-modal music genre recognition,” Entropy, vol. 23, no. 11, 2021, https://doi.org/10.3390/e23111502.
O. Sen et al., “Bangla natural language processing: A comprehensive analysis of classical, machine learning, and deep learning-based methods,” IEEE Access, vol. 10, pp. 38999–39044, 2022, https://doi.org/10.1109/ACCESS.2022.3165563.
M. Zulqarnain, R. Ghazali, M. G. Ghouse, N. A. Husaini, A. K. Z. Al-Saedi, and W. Sharif, “A comparative analysis on question classification task based on deep learning approaches,” PeerJ Comput. Sci., vol. 7, pp. 1–27, 2021, https://doi.org/10.7717/PEERJ-CS.570.
P. Bell, J. Fainberg, O. Klejch, J. Li, S. Renals, and P. Swietojanski, “Adaptation Algorithms for Neural Network-Based Speech Recognition: An Overview,” IEEE Open J. Signal Process., vol. 2, pp. 33–66, 2021, https://doi.org/10.1109/OJSP.2020.3045349.
M. Du, C. Liu and J. Lai, "InstantSpeech: Instant Synchronous Text-to-Speech Synthesis for LLM-driven Voice Chatbots," ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5, 2025. https://doi.org/10.1109/ICASSP49660.2025.10890120.
S.-Y. Tseng, S. Narayanan, and P. Georgiou, “Multimodal Embeddings from Language Models for Emotion Recognition in the Wild,” IEEE Signal Process. Lett., vol. 28, pp. 608–612, 2021, https://doi.org/10.1109/LSP.2021.3065598.
R. Yoshida, S. Yoshida, and M. MUNEYASU, “MAHGA: Multi-Aspect Heterogeneous Graph Analysis for Harmful Speech Detection on Social Networks,” IEEE Access, vol. 13, pp. 106673–106689, 2025, https://doi.org/10.1109/ACCESS.2025.3581214.
M. J. Dileep Kumar, M. Sukesh Rao and K. C. Narendra, "Multimodal Emotion Recognition: A Comprehensive Survey of Datasets, Methods, and Applications," in IEEE Access, vol. 13, pp. 201067-201097, 2025, https://doi.org/10.1109/ACCESS.2025.3636186.
F. Casu, A. Lagorio, P. Ruiu, G. A. Trunfio, and E. Grosso, “Integrating Fine-Tuned LLM with Acoustic Features for Enhanced Detection of Alzheimer’s Disease,” IEEE J. Biomed. Heal. Informatics, 2025, https://doi.org/10.1109/JBHI.2025.3566615.
Y. Sermet and I. Demir, “A semantic web framework for automated smart assistants: A case study for public health,” Big Data Cogn. Comput., vol. 5, no. 4, 2021, https://doi.org/10.3390/bdcc5040057.
S. Shin and R. R. A. Issa, “BIMASR: Framework for Voice-Based BIM Information Retrieval,” J. Constr. Eng. Manag., vol. 147, no. 10, 2021, https://doi.org/10.1061/(ASCE)CO.1943-7862.0002138.
M. Wairagkar et al., “Conversational artificial intelligence and affective social robot for monitoring health and well-being of people with dementia,” Alzheimer’s Dement., vol. 17, p. e053276, 2021, https://doi.org/10.1002/alz.053276.
J. Park and M. Nammee, “Design and Implementation of Attention Depression Detection Model Based on Multimodal Analysis,” Sustain., vol. 14, no. 6, 2022, https://doi.org/10.3390/su14063569.
K. Mori, “Decoding peak emotional responses to music from computational acoustic and lyrical features,” Cognition, vol. 222, 2022, https://doi.org/10.1016/j.cognition.2021.105010.
S. Salmi, S. Y. M. Mérelle, R. Gilissen, R. D. van der Mei, and S. Bhulai, “Detecting changes in help seeker conversations on a suicide prevention helpline during the COVID− 19 pandemic: in-depth analysis using encoder representations from transformers,” BMC Public Health, vol. 22, no. 1, 2022, https://doi.org/10.1186/s12889-022-12926-2.
M. R. Lima et al., “Conversational Affective Social Robots for Ageing and Dementia Support,” IEEE Trans. Cogn. Dev. Syst., vol. 14, no. 4, pp. 1378–1397, 2022, https://doi.org/10.1109/TCDS.2021.3115228.
E. J. Tan, E. Neill, J. L. Kleiner, and S. L. Rossell, “Depressive symptoms are specifically related to speech pauses in schizophrenia spectrum disorders,” Psychiatry Res., vol. 321, 2023, https://doi.org/10.1016/j.psychres.2023.115079.
J. J. Huallpa et al., “Exploring the ethical considerations of using Chat GPT in university education,” Period. Eng. Nat. Sci., vol. 11, no. 4, pp. 105–115, 2023, https://doi.org/10.21533/pen.v11i4.3770.
M. Qasim, T. Habib, S. Urooj, and B. Mumtaz, “DESCU: Dyadic emotional speech corpus and recognition system for Urdu language,” Speech Commun., vol. 148, pp. 40–52, 2023, https://doi.org/10.1016/j.specom.2023.02.002.
Y. Song, R. C. W. Wong, and X. Zhao, “Speech-to-SQL: toward speech-driven SQL query generation from natural language question,” VLDB J., vol. 33, no. 4, pp. 1179–1201, 2024, https://doi.org/10.1007/s00778-024-00837-0.
R. K. Chakrawarti, J. Bansal, and P. Bansal, “Machine translation model for effective translation of Hindi poetries into English,” J. Exp. Theor. Artif. Intell., vol. 34, no. 1, pp. 95–109, 2022, https://doi.org/10.1080/0952813X.2020.1836033.
D. Kim, W. H. Son, S. S. Kwak, T. Yun, J. Park, and J. Lee, “A Hybrid Deep Learning Emotion Classification System Using Multimodal Data,” Sensors, vol. 23, no. 23, 2023, https://doi.org/10.3390/s23239333.
R. Zheng and R. Zhang, “Classification of intelligent speech system and education method based on improved multi label transfer learning model,” Int. J. Syst. Assur. Eng. Manag., 2023, https://doi.org/10.1007/s13198-023-02056-2.
P. Zhang, X. Huang, Y. Wang, C. Jiang, S. He, and H. Wang, “Semantic Similarity Computing Model Based on Multi Model Fine-Grained Nonlinear Fusion,” IEEE Access, vol. 9, pp. 8433–8443, 2021, https://doi.org/10.1109/ACCESS.2021.3049378.
Y. Guo and Z. Yan, “Recommended System: Attentive Neural Collaborative Filtering,” IEEE Access, vol. 8, pp. 125953–125960, 2020, https://doi.org/10.1109/ACCESS.2020.3006141.
N. Amangeldy, A. Ukenova, G. T. Bekmanova, B. Razakhova, M. Milosz, and S. A. Kudubayeva, “Continuous Sign Language Recognition and Its Translation into Intonation-Colored Speech,” Sensors, vol. 23, no. 14, 2023, https://doi.org/10.3390/s23146383.
A. J. Moshayedi, A. S. Roy, A. Kolahdooz, and S. Yang, “Deep Learning Application Pros and Cons Over Algorithm,” EAI Endorsed Trans. AI Robot., vol. 1, 2022, https://doi.org/10.4108/airo.v1i.19.
A. Ghosh and K. Deepa, “QueryMintAI: Multipurpose Multimodal Large Language Models for Personal Data,” IEEE Access, vol. 12, pp. 144631–144651, 2024, https://doi.org/10.1109/ACCESS.2024.3468996.
T. Ben Moshe, I. Ziv, N. Dershowitz, and K. Bar, “The contribution of prosody to machine classification of schizophrenia,” Schizophrenia, vol. 10, no. 1, 2024, https://doi.org/10.1038/s41537-024-00463-3.
D. Thompson, H. Leuthold, and R. Filik, “Examining the influence of perspective and prosody on expected emotional responses to irony: Evidence from event-related brain potentials.,” Can. J. Exp. Psychol., vol. 75, no. 2, pp. 107–113, 2021, https://doi.org/10.1037/cep0000249.
R. Hou, “Music content personalized recommendation system based on a convolutional neural network,” Soft Comput., vol. 28, no. 2, pp. 1785–1802, 2024, https://doi.org/10.1007/s00500-023-09457-2.
T. Khan, M. Saif, and A. F. Mollah, “MuSIC: A Novel Multi-Scale Deep Neural Framework for Script Identification in the Wild,” IEEE Access, vol. 12, pp. 166955–166976, 2024, https://doi.org/10.1109/ACCESS.2024.3494023.
M. Rospocher and S. Eksir, “Assessing Fine-Grained Explicitness of Song Lyrics,” Inf., vol. 14, no. 3, 2023, https://doi.org/10.3390/info14030159.
M. Martinc, F. Haider, S. Pollak, and S. F. Luz, “Temporal Integration of Text Transcripts and Acoustic Features for Alzheimer’s Diagnosis Based on Spontaneous Speech,” Front. Aging Neurosci., vol. 13, 2021, https://doi.org/10.3389/fnagi.2021.642647.
A. Lücking and J. Ginzburg, “Leading voices: Dialogue semantics, cognitive science and the polyphonic structure of multimodal interaction,” Lang. Cogn., vol. 15, no. 1, pp. 148–172, 2023, https://doi.org/10.1017/langcog.2022.30.
J. Liu, C. Li, Y. Huang, and J. Han, “An intelligent medical guidance and recommendation model driven by patient-physician communication data,” Front. Public Heal., vol. 11, 2023, https://doi.org/10.3389/fpubh.2023.1098206.
S. N., S. Wagle, P. Ghosh and K. Kishore, "Sentiment Classification of English and Hindi Music Lyrics Using Supervised Machine Learning Algorithms," 2022 2nd Asian Conference on Innovation in Technology (ASIANCON), pp. 1-6, 2022, https://doi.org/10.1109/ASIANCON55314.2022.9908688.
V. Rajan, A. Brutti and A. Cavallaro, "Is Cross-Attention Preferable to Self-Attention for Multi-Modal Emotion Recognition?," ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4693-4697, 2022, https://doi.org/10.1109/ICASSP43922.2022.9746924.
M. A. Azim, W. Hussein, and N. L. Badr, “Using Character-Level Sequence-to-Sequence Model for Word Level Text Generation to Enhance Arabic Speech Recognition,” IEEE Access, vol. 11, pp. 91173–91183, 2023, https://doi.org/10.1109/ACCESS.2023.3302257.
A. E. A. Kaneho, N. Zrira, K. Ouazzani-Touhami, H. A. Khan, and S. Nawaz, “Development of a bilingual healthcare chatbot for pregnant women: A comparative study of deep learning models with BiGRU optimization,” Intell. Med., vol. 12, 2025, https://doi.org/10.1016/j.ibmed.2025.100261.
G. Ahmed and A. A. Lawaye, “CNN-based speech segments endpoints detection framework using short-time signal energy features,” Int. J. Inf. Technol., vol. 15, no. 8, pp. 4179–4191, 2023, https://doi.org/10.1007/s41870-023-01466-6.
B. Zhang, H. Cui, V. A. Nguyen, and M. T. Whitty, “Audio Deepfake Detection: What Has Been Achieved and What Lies Ahead,” Sensors, vol. 25, no. 7, 2025, https://doi.org/10.3390/s25071989.
S. Wu and M. Sun, “Exploring the efficacy of pre-trained checkpoints in text-to-music generation taskm,” arXiv preprint arXiv:2211.11216, 2022, https://doi.org/10.48550/arXiv.2211.11216.
Z. Wang, D. Li, R. Jiang, and M. Okumura, “Continuous Sign Language Recognition with Multi-Scale Spatial-Temporal Feature Enhancement,” IEEE Access, vol. 13, pp. 5491–5506, 2025, https://doi.org/10.1109/ACCESS.2025.3526330.
C. Singla et al., “Utilizing Convolutional Neural Networks To Comprehend Sign Language And Recognize Emotions,” Fractals, vol. 32, no. 9–10, 2024, https://doi.org/10.1142/S0218348X2540016X.
A. Casas-Mas, J. I. Pozo, and I. Montero, “Oral Tradition as Context for Learning Music From 4E Cognition Compared With Literacy Cultures. Case Studies of Flamenco Guitar Apprenticeship,” Front. Psychol., vol. 13, 2022, https://doi.org/10.3389/fpsyg.2022.733615.
W. Chen, “Deep Adversarial Neural Network Model Based on Information Fusion for Music Sentiment Analysis,” Comput. Sci. Inf. Syst., vol. 20, no. 4, pp. 1797–1817, 2023, https://doi.org/10.2298/CSIS221212031C.
S. MacNiven, J. J. Lennon, J. Roberts, and M. MacNiven, “The language of marketing hyperbole and consumer perception–The case of Glasgow,” PLoS One, vol. 18, no. 12, 2023, https://doi.org/10.1371/journal.pone.0295132.
Y. Wang, L. Yang, and Z. Lun, “Big Data Mining Analysis Technology For Natural Language Processing Robot Design,” J. Appl. Sci. Eng., vol. 27, no. 12, pp. 3677–3686, 2024, https://doi.org/10.6180/jase.202412_27(12).0008.
M. K. Singh, “A text independent speaker identification system using ANN, RNN, and CNN classification technique,” Multimed. Tools Appl., vol. 83, no. 16, pp. 48105–48117, 2024, https://doi.org/10.1007/s11042-023-17573-2.
T. Kim, J. Yang, and E. Park, “MSDLF-K: A Multimodal Feature Learning Approach for Sentiment Analysis in Korean Incorporating Text and Speech,” IEEE Trans. Multimed., vol. 27, pp. 1266–1276, 2025, https://doi.org/10.1109/TMM.2024.3521707.
Z. Shibo, H. Danke, H. Feifei, L. Liu, and X. Fei, “Application of intelligent speech analysis based on BiLSTM and CNN dual attention model in power dispatching,” Nanotechnol. Environ. Eng., vol. 6, no. 3, 2021, https://doi.org/10.1007/s41204-021-00148-7.
A. B. Nassif, I. M. A. Shahin, S. Hamsa, N. Nemmour, and K. Hirose, “CASA-based speaker identification using cascaded GMM-CNN classifier in noisy and emotional talking conditions,” Appl. Soft Comput., vol. 103, 2021, https://doi.org/10.1016/j.asoc.2021.107141.
S. Ayadi and Z. Lachiri, “Deep neural network architectures for audio emotion recognition performed on song and speech modalities,” Int. J. Speech Technol., vol. 26, no. 4, pp. 1165–1181, 2023, https://doi.org/10.1007/s10772-023-10079-0.
M. Dongbo, S. Miniaoui, L. Fen, S. A. Althubiti, and T. R. Alsenani, “Intelligent chatbot interaction system capable for sentimental analysis using hybrid machine learning algorithms,” Inf. Process. Manag., vol. 60, no. 5, 2023, https://doi.org/10.1016/j.ipm.2023.103440.
S. A. Just et al., “Moving beyond word error rate to evaluate automatic speech recognition in clinical samples: Lessons from research into schizophrenia-spectrum disorders,” Psychiatry Res., vol. 352, 2025, https://doi.org/10.1016/j.psychres.2025.116690.
A. Valladares-Poncela, P. Fraga-Lamas, and T. M. Fernández-Caramés, “On-Device Automatic Speech Recognition for Low-Resource Languages in Mixed Reality Industrial Metaverse Applications: Practical Guidelines and Evaluation of a Shipbuilding Application in Galician,” IEEE Access, vol. 13, pp. 77017–77038, 2025, https://doi.org/10.1109/ACCESS.2025.3564137.
R. G. Al-Anazi et al., “Multi-Class Automated Speech Language Recognition Using Natural Language Processing With Optimal Deep Learning Model,” Fractals, vol. 33, no. 2, 2025, https://doi.org/10.1142/S0218348X25400213.
X. Wu and Q. Zhang, “Intelligent Aging Home Control Method and System for Internet of Things Emotion Recognition,” Front. Psychol., vol. 13, 2022, https://doi.org/10.3389/fpsyg.2022.882699.
F. S. Al-Anzi, “Improved Noise-Resilient Isolated Words Speech Recognition Using Piecewise Differentiation,” Fractals, vol. 30, no. 8, 2022, https://doi.org/10.1142/S0218348X22402277.
J. Oh and J. Lee, “Multilingual Mobility: Audio-Based Language ID for Automotive Systems,” Appl. Sci., vol. 15, no. 16, 2025, https://doi.org/10.3390/app15169209.
K. Keyvan and J. X. Huang, “How to Approach Ambiguous Queries in Conversational Search: A Survey of Techniques, Approaches, Tools, and Challenges,” ACM Comput. Surv., vol. 55, no. 6, 2023, https://doi.org/10.1145/3534965.
S. Shah, H. Ghomeshi, E. Vakaj, E. Cooper, and S. A. Fouad, “A review of natural language processing in contact centre automation,” Pattern Anal. Appl., vol. 26, no. 3, pp. 823–846, 2023, https://doi.org/10.1007/s10044-023-01182-8.
M. Chiu, C. Tsai, and Y. Huang, “Integrating object detection and natural language processing models to build a personalized attraction recommendation agent in a smart product service system,” Adv. Eng. Informatics, vol. 61, 2024, https://doi.org/10.1016/j.aei.2024.102484.
M. Han, D. Zhu, X. Wen, L. Shu, and Z. Yao, “Research on Dialect Protection: Interaction Design of Chinese Dialects Based on BLSTM-CRF and FBM Theories,” IEEE Access, vol. 12, pp. 22059–22071, 2024, https://doi.org/10.1109/ACCESS.2024.3364098.
M. N. Islam, S. T. Mim, T. Tasfia, and M. M. N. Hossain, “Enhancing patient treatment through automation: The development of an efficient scribe and prescribe system,” Informatics Med. Unlocked, vol. 45, 2024, https://doi.org/10.1016/j.imu.2024.101456.
S. Chang and D. Kim, “Scalable Transformer Accelerator with Variable Systolic Array for Multiple Models in Voice Assistant Applications,” Electron., vol. 13, no. 23, 2024, https://doi.org/10.3390/electronics13234683.
C. Kooli and R. Chakraoui, “AI-driven assistive technologies in inclusive education: benefits, challenges, and policy recommendations,” Sustain. Futur., vol. 10, 2025, https://doi.org/10.1016/j.sftr.2025.101042.
J. Liu, X. Bao, and L. Chen, “Artificial intelligence in educational technology and transformative approaches to English language using fuzzy framework with CRITIC-TOPSIS method,” Sci. Rep., vol. 15, no. 1, 2025, https://doi.org/10.1038/s41598-025-09844-9.
A. Al Tarabsheh et al., “Towards contactless learning activities during pandemics using autonomous service robots,” Appl. Sci., vol. 11, no. 21, 2021, https://doi.org/10.3390/app112110449.
T. Mavropoulos et al., “Smart integration of sensors, computer vision and knowledge representation for intelligent monitoring and verbal human-computer interaction,” J. Intell. Inf. Syst., vol. 57, no. 2, pp. 321–345, 2021, https://doi.org/10.1007/s10844-021-00648-7.
F. Rustam et al., “Automated disease diagnosis and precaution recommender system using supervised machine learning,” Multimed. Tools Appl., vol. 81, no. 22, pp. 31929–31952, 2022, https://doi.org/10.1007/s11042-022-12897-x.
T. P. Li et al., “Socratic Artificial Intelligence Learning (SAIL): The Role of a Virtual Voice Assistant in Learning Orthopedic Knowledge,” J. Surg. Educ., vol. 81, no. 11, pp. 1655–1666, 2024, https://doi.org/10.1016/j.jsurg.2024.08.006.
L. M. Owens, J. J. Wilda, P. Y. Hahn, T. Koehler, and J. J. Fletcher, “The association between use of ambient voice technology documentation during primary care patient encounters, documentation burden, and provider burnout,” Fam. Pract., vol. 41, no. 2, pp. 86–91, 2024, https://doi.org/10.1093/fampra/cmad092.
L. M. Owens, J. J. Wilda, R. G. Grifka, J. Westendorp, and J. J. Fletcher, “Effect of Ambient Voice Technology, Natural Language Processing, and Artificial Intelligence on the Patient-Physician Relationship,” Appl. Clin. Inform., vol. 15, no. 4, pp. 660–667, 2024, https://doi.org/10.1055/a-2337-4739.
T. Desot, F. Portet, and M. Vacher, “End-to-End Spoken Language Understanding: Performance analyses of a voice command task in a low resource setting,” Comput. Speech Lang., vol. 75, 2022, https://doi.org/10.1016/j.csl.2022.101369.
D. Khalil et al., “An Automatic Speaker Clustering Pipeline for the Air Traffic Communication Domain,” Aerospace, vol. 10, no. 10, 2023, https://doi.org/10.3390/aerospace10100876.
J. Lee, Y. Sim, J. Kim, and Y. Suh, “EmoSDS: Unified Emotionally Adaptive Spoken Dialogue System Using Self-Supervised Speech Representations,” Futur. Internet, vol. 17, no. 4, 2025, https://doi.org/10.3390/fi17040143.
Y. Guo, Y. Liu, T. Zhou, L. Xu, and Q. Zhang, “An automatic music generation and evaluation method based on transfer learning,” PLoS One, vol. 18, no. 5, 2023, https://doi.org/10.1371/journal.pone.0283103.
L. Psyche, B. M. Kubit, Y. Ou, and E. H. Margulis, “Imaginings From an Unfamiliar World: Narrative Engagement With a New Musical System,” Psychol. Aesthetics, Creat. Arts, 2023, https://doi.org/10.1037/aca0000629.
J. Chang, J. C. S. Hung, and K. Lin, “Singability-enhanced lyric generator with music style transfer,” Comput. Commun., vol. 168, pp. 33–53, 2021, https://doi.org/10.1016/j.comcom.2021.01.002.
Y. Li, X. Li, Z. Lou, and C. Chen, “Long Short-Term Memory-Based Music Analysis System for Music Therapy,” Front. Psychol., vol. 13, 2022, https://doi.org/10.3389/fpsyg.2022.928048.
S. Radhakrishnan, J. M. Chatterjee, B. Pathy, and Y. Hu, “Automatic emotion recognition using deep neural network,” Multimed. Tools Appl., vol. 84, no. 28, pp. 33633–33662, 2025, https://doi.org/10.1007/s11042-024-20590-4.
R. He, R. Liu, T. Peng, and X. Hu, “MelodyTransformer: Improving lyric-to-melody generation by considering melodic features,” Neurocomputing, vol. 638, 2025, https://doi.org/10.1016/j.neucom.2025.130166.
M. Rospocher, “Explicit song lyrics detection with subword-enriched word embeddings,” Expert Syst. Appl., vol. 163, 2021, https://doi.org/10.1016/j.eswa.2020.113749.
S. Deepaisarn, S. Chokphantavee, S. Chokphantavee, P. Prathipasen, S. Buaruk, and V. Sornlertlamvanich, “NLP-based music processing for composer classification,” Sci. Rep., vol. 13, no. 1, 2023, https://doi.org/10.1038/s41598-023-40332-0.
U. Singh, A. Saraswat, H. K. Azad, K. Abhishek, and S. Selvarajan, “Towards improving e-commerce customer review analysis for sentiment detection,” Sci. Rep., vol. 12, no. 1, 2022, https://doi.org/10.1038/s41598-022-26432-3.
X. Wang, Y. Mao, X. Wu, Q. Xu, W. Jiang, and S. Yin, “An ATC instruction processing-based trajectory prediction algorithm designing,” Neural Comput. Appl., vol. 35, no. 32, pp. 23477–23490, 2023, https://doi.org/10.1007/s00521-021-05713-4.
A. K. Alshammari et al., “Applied Linguistics With Deep Learning-Based Data-Driven Text-To-Speech Synthesizer For Arabic Corpus,” Fractals, vol. 32, no. 9–10, 2024, https://doi.org/10.1142/S0218348X25400249.
D. Jia et al., “VOICE: Visual Oracle for Interaction, Conversation, and Explanation,” IEEE Trans. Vis. Comput. Graph., vol. 31, no. 10, pp. 8828–8845, 2025, https://doi.org/10.1109/TVCG.2025.3579956.
P. K. Adhikary et al., “Menstrual Health Education Using a Specialized Large Language Model in India: Development and Evaluation Study of MenstLLaMA,” J. Med. Internet Res., vol. 27, 2025, https://doi.org/10.2196/71977.
S. Li and Y. Sung, “Type-based mixture of experts and semi-supervised multi-task pre-training for symbolic music,” Expert Syst. Appl., vol. 292, 2025, https://doi.org/10.1016/j.eswa.2025.128613.
A. Amiri, A. Ghaffarnia, N. Ghaffar Nia, D. Wu, and Y. Liang, “Harmonizer: A Universal Signal Tokenization Framework for Multimodal Large Language Models,” Mathematics, vol. 13, no. 11, 2025, https://doi.org/10.3390/math13111819.
J. Kane, M. N. Johnstone, and P. Szewczyk, “Voice Synthesis Improvement by Machine Learning of Natural Prosody,” Sensors, vol. 24, no. 5, 2024, https://doi.org/10.3390/s24051624.
L. Chen, “Visual language transformer framework for multimodal dance performance evaluation and progression monitoring,” Sci. Rep., vol. 15, no. 1, 2025, https://doi.org/10.1038/s41598-025-16345-2.
S. García-Méndez, F. de Arriba-Pérez, F. Javier González-Castaño, J. A. Regueiro-Janeiro, and F. J. Gil-Castiñeira, “Entertainment Chatbot for the Digital Inclusion of Elderly People without Abstraction Capabilities,” IEEE Access, vol. 9, pp. 75878–75891, 2021, https://doi.org/10.1109/ACCESS.2021.3080837.
F. Ke, “Intelligent Classification Model of Music Emotional Environment Using Convolutional Neural Networks,” J. Environ. Public Health, vol. 2022, 2022, https://doi.org/10.1155/2022/7221064.
J. G. Yu, J. Zhao, L. F. Miranda-Moreno, and M. Korp, “Modular AI agents for transportation surveys and interviews: Advancing engagement, transparency, and cost efficiency,” Commun. Transp. Res., vol. 5, 2025, https://doi.org/10.1016/j.commtr.2025.100172.
S. Yawen, “The Educational Potential Of F. Chopin’s Metodological Principles Of In The Piano Training Of Chinese Students; Образовательный Потенциал Методических Принципов Ф. Шопена В Фортепианной Подготовке Китайских Студентов,” Music. Art Educ., vol. 11, no. 2, pp. 81–90, 2023, https://doi.org/10.31862/2309-1428-2023-11-2-81-90.
R. Pugalenthi, P. A. Chakkaravarthy, J. Ramya, S. Babu, and R. Rasika Krishnan, “Artificial learning companionusing machine learning and natural language processing,” Int. J. Speech Technol., vol. 24, no. 3, pp. 553–560, 2021, https://doi.org/10.1007/s10772-020-09773-0.
L. Chikwetu, S. B. Daily, B. J. Mortazavi, and J. P. Dunn, “Automated Diet Capture Using Voice Alerts and Speech Recognition on Smartphones: Pilot Usability and Acceptability Study,” JMIR Form. Res., vol. 7, 2023, https://doi.org/10.2196/46659.
D. Yang, K. Ji, and T. J. Tsai, “A deeper look at sheet music composer classification using self-supervised pretraining,” Appl. Sci., vol. 11, no. 4, pp. 1–16, 2021, https://doi.org/10.3390/app11041387.
D. Paul, A. Jain, S. Saha, and J. Mathew, “Multi-objective PSO based online feature selection for multi-label classification,” Knowledge-Based Syst., vol. 222, 2021, https://doi.org/10.1016/j.knosys.2021.106966.
T. V Rathcke and C. Y. Lin, “Towards a comprehensive account of rhythm processing issues in developmental dyslexia,” Brain Sci., vol. 11, no. 10, 2021, https://doi.org/10.3390/brainsci11101303.
E. Sezgin, S. A. Hussain, S. W. Rust, and Y. Huang, “Extracting Medical Information From Free-Text and Unstructured Patient-Generated Health Data Using Natural Language Processing Methods: Feasibility Study With Real-world Data,” JMIR Form. Res., vol. 7, 2023, https://doi.org/10.2196/43014.
Y. Huang and K. C. You, “Automated Generation of Chinese Lyrics Based on Melody Emotions,” IEEE Access, vol. 9, pp. 98060–98071, 2021, https://doi.org/10.1109/ACCESS.2021.3095964.
C. Gallezot et al., “Emotion expression through spoken language in Huntington disease,” Cortex, vol. 155, pp. 150–161, 2022, https://doi.org/10.1016/j.cortex.2022.05.024.
A. Osmanovic-Thunström, H. K. Carlsen, L. Ali, T. Larson, A. Hellström, and S. Steingrímsson, “Usability Comparison Among Healthy Participants of an Anthropomorphic Digital Human and a Text-Based Chatbot as a Responder to Questions on Mental Health: Randomized Controlled Trial,” JMIR Hum. Factors, vol. 11, 2024, https://doi.org/10.2196/54581.
J. Chang, “Enabling progressive system integration for AIoT and speech-based HCI through semantic-aware computing,” J. Supercomput., vol. 78, no. 3, pp. 3288–3324, 2022, https://doi.org/10.1007/s11227-021-03996-x.
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Novia Ratnasari, Aji Prasetya Wibawa

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See The Effect of Open Access).

This journal is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

