Bi-LSTM and Attention-based Approach for Lip-To-Speech Synthesis in Low-Resource Languages: A Case Study on Bahasa Indonesia
DOI:
https://doi.org/10.12928/biste.v7i4.14310Keywords:
Lip-to-Speech Synthesis, Speech Reconstruction, Sequence Modeling, Low-Resource Language Processing;, Indonesian Speech CorpusAbstract
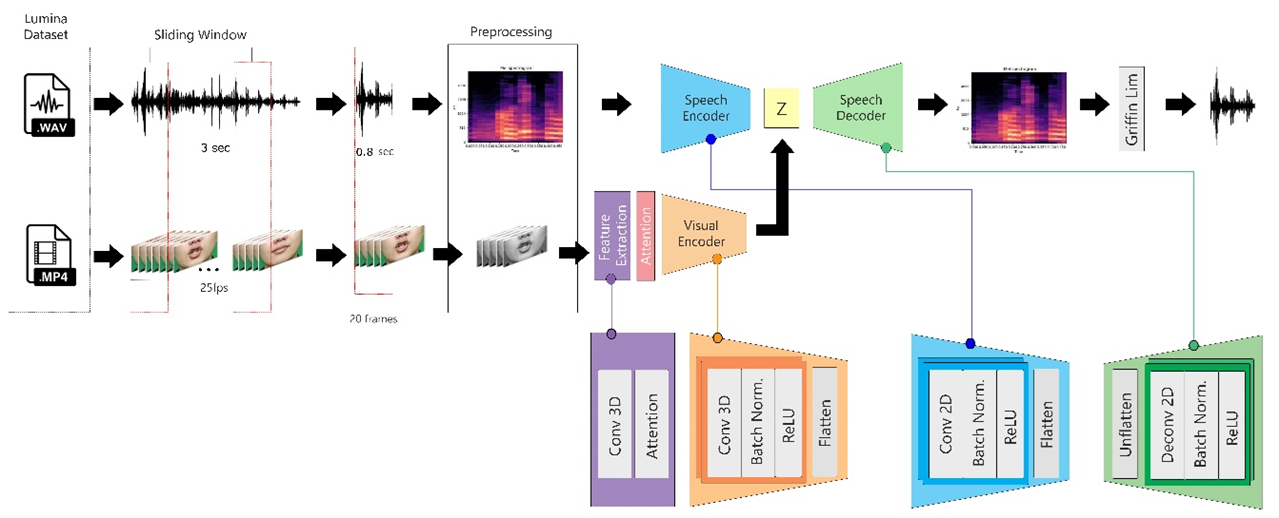
Lip-to-speech synthesis enables the transformation of visual information, particularly lip movements, into intelligible speech. This technology has gained increasing attention due to its potential in assistive communication for individuals with speech impairments, audio restoration in cases of missing or corrupted speech signals, and enhancement of communication quality in noisy or bandwidth-limited environments. However, research on low-resource languages, such as Bahasa Indonesia, remains limited, primarily due to the absence of suitable corpora and the unique phonetic structures of the language. To address this challenge, this study employs the LUMINA dataset, a purpose-built Indonesian audio-visual corpus comprising 14 speakers with diverse syllabic coverage. The main contribution of this work is the design and evaluation of an Attention-Augmented Bi-LSTM Multimodal Autoencoder, implemented as a two-stage parallel pipeline: (1) an audio autoencoder trained to learn compact latent representations from Mel-spectrograms, and (2) a visual encoder based on EfficientNetV2-S integrated with Bi-LSTM and multi-head attention to predict these latent features from silent video sequences. The experimental evaluation yields promising yet constrained results. Objective metrics yielded maximum scores of PESQ 1.465, STOI 0.7445, and ESTOI 0.5099, which are considerably lower than those of state-of-the-art English systems (PESQ > 2.5, STOI > 0.85), indicating that intelligibility remains a challenge. However, subjective evaluation using Mean Opinion Score (MOS) demonstrates consistent improvements: while baseline LSTM models achieve only 1.7–2.5, the Bi-LSTM with 8-head attention attains 3.3–4.0, with the highest ratings observed in female multi-speaker scenarios. These findings confirm that Bi-LSTM with attention improves over conventional baselines and generalizes better in multi-speaker contexts. The study establishes a first baseline for lip-to-speech synthesis in Bahasa Indonesia and underscores the importance of larger datasets and advanced modeling strategies to further enhance intelligibility and robustness in low-resource language settings.
References
D. J. Lewkowicz dan A. H. Tift, “Infants Deploy Selective Attention to the Mouth of a Talking Face When Learning Speech,” In Proceedings of the National Academy of Sciences of the United States of America (PNAS), vol. 109, no. 5, pp. 1431-1436, 2012, https://doi.org/10.1073/pnas.1114783109.
G. Li, M. Fu, M. Sun, X. Liu dan B. Zheng, “A Facial Feature and Lip Movement Enhanced Audio-Visual Speech Separation Model,” MDPI Sensor, vol. 23, 2023, https://doi.org/10.3390/s23218770.
J. S. Chung dan A. Zisserman, “Lip reading in the wild,” In Asian Conference on Computer Vision (ACCV), pp. 87-103, 2016, https://doi.org/10.1007/978-3-319-54184-6_6.
A. Adler, V. Emiya, M. G. Jafari, M. Elad, R. Gribonval dan M. D. Plumbley, “Audio Inpainting,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 3, pp. 922 - 932, 2012, https://doi.org/10.1109/TASL.2011.2168211.
D. Rethage, J. Pons dan X. Serra, “A Wavenet for Speech Denoising,” In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5069-5073, 2018, https://doi.org/10.1109/ICASSP.2018.8462417.
H. Shi, X. Shi, and S. Dogan, “Speech Inpainting Based on Multi-Layer Long Short-Term Memory Networks,” Future Internet, vol. 16, no. 2, p. 63, 2024, https://doi.org/10.3390/fi16020063.
G. Tauböck, S. Rajbamshi and P. Balazs, "Dictionary Learning for Sparse Audio Inpainting," in IEEE Journal of Selected Topics in Signal Processing, vol. 15, no. 1, pp. 104-119, 2021, https://doi.org/10.1109/JSTSP.2020.3046422.
K. R. Prajwal, R. Mukhopadhyay, V. P. Namboodiri and C. V. Jawahar, "Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis," 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13793-13802, 2020, https://doi.org/10.1109/CVPR42600.2020.01381.
D. Michelsanti, O. Slizovskaia, G. Haro dan J. Jensen, “Vocoder-Based Speech Synthesis from Silent Videos,” arXiv preprint arXiv:2004.02541, 2020, https://doi.org/10.48550/arXiv.2004.02541.
Z. Niu and B. Mak, "On the Audio-visual Synchronization for Lip-to-Speech Synthesis," 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 7809-7818, 2023, https://doi.org/10.1109/ICCV51070.2023.00721.
Z. Dong, Y. Xu, A. Abel, and D. Wang, “Lip2Speech: lightweight multi-speaker speech reconstruction with gabor features,” Applied Sciences, vol. 14, no. 2, p. 798, 2024, https://doi.org/10.3390/app14020798.
R. C. Zheng, Y. Ai dan Z. H. Ling, “Speech Reconstruction from Silent Lip and Tongue Articulation by Diffusion Models and Text-Guided Pseudo Target Generation,” In Proceedings of the 32nd ACM International Conference on Multimedia, pp. 6559-6568, 2024, https://doi.org/10.1145/3664647.3680770.
J. Li, C. Li, Y. Wu and Y. Qian, "Unified Cross-Modal Attention: Robust Audio-Visual Speech Recognition and Beyond," in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 1941-1953, 2024, https://doi.org/10.1109/TASLP.2024.3375641.
S. Ghosh, S. Sarkar, S. Ghosh, F. Zalkow dan N. D. Jana, “Audio-Visual Speech Synthesis Using Vision Transformer–Enhanced Autoencoders,” Applied Intelligence, vol. 54, no. 6, pp. 4507-4524, 2024, https://doi.org/10.1007/s10489-024-05380-7.
N. Sahipjohn, N. Shah, V. Tambrahalli and V. Gandhi, "RobustL2S: Speaker-Specific Lip-to-Speech Synthesis exploiting Self-Supervised Representations," 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Taipei, Taiwan, 2023, pp. 1492-1499, 2023, https://doi.org/10.1109/APSIPAASC58517.2023.10317357.
Y. Liang, F. Liu, A. Li, X. Li dan C. Zheng, “NaturalL2S: End-to-End High-quality Multispeaker Lip-to-Speech Synthesis with Differential Digital Signal Processing,” arXiv preprint arXiv:2502.12002, 2025, https://doi.org/10.48550/arXiv.2502.12002.
R. Mira, A. Haliassos, S. Petridis, B. W. Schuller, and M. Pantic, “Svts: Scalable video-to-speech synthesis,” arXiv preprint arXiv:2205.02058, 2022, https://doi.org/10.48550/arXiv.2205.02058.
H. Akbari, H. Arora, L. Cao and N. Mesgarani, "Lip2Audspec: Speech Reconstruction from Silent Lip Movements Video," 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2516-2520, 2018, https://doi.org/10.1109/ICASSP.2018.8461856.
Y. Yemini, A. Shamsian, L. Bracha, S. Gannot, and E. Fetaya, “Lipvoicer: Generating speech from silent videos guided by lip reading,” arXiv preprint arXiv:2306.03258, 2023, https://doi.org/10.48550/arXiv.2306.03258.
J. Choi, M. Kim, and Y. M. Ro, “Intelligible lip-to-speech synthesis with speech units,” arXiv preprint arXiv:2305.19603, 2023, https://doi.org/10.48550/arXiv.2305.19603.
T. Kefalas, Y. Panagakis, and M. Pantic, “Audio-visual video-to-speech synthesis with synthesized input audio,” arXiv preprint arXiv:2307.16584, 2023, https://doi.org/10.48550/arXiv.2307.16584.
A. P. Wibawa et al., “Bidirectional Long Short-Term Memory (Bi-LSTM) Hourly Energy Forecasting,” In E3S Web of Conferences, vol. 501, p. 01023, 2024, https://doi.org/10.1051/e3sconf/202450101023.
B. Fan, L. Xie, S. Yang, L. Wang dan F. K. Soong, “A deep bidirectional LSTM approach for video-realistic talking head,” Multimedia Tools and Applications, vol. 75, no. 9, pp. 5287-5309, 2016, https://doi.org/10.1007/s11042-015-2944-3.
H. Wang, F. Yu, X. Shi, Y. Wang, S. Zhang and M. Li, "SlideSpeech: A Large Scale Slide-Enriched Audio-Visual Corpus," ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 11076-11080, 2024, https://doi.org/10.1109/ICASSP48485.2024.10448079.
N. Harte and E. Gillen, "TCD-TIMIT: An Audio-Visual Corpus of Continuous Speech," in IEEE Transactions on Multimedia, vol. 17, no. 5, pp. 603-615, 2015, https://doi.org/10.1109/TMM.2015.2407694.
A. Ephrat et al., “Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation,” arXiv preprint arXiv:1804.03619, 2018, https://doi.org/10.1145/3197517.3201357.
P. Ma, A. Haliassos, A. Fernandez-Lopez, H. Chen, S. Petridis and M. Pantic, "Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels," ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5, 2023, https://doi.org/10.1109/ICASSP49357.2023.10096889.
E. R. Setyaningsih, A. N. Handayani, W. S. G. Irianto, Y. Kristian and C. T. S. L. Chen, “LUMINA: Linguistic unified multimodal Indonesian natural audio-visual dataset,” Data in Brief, vol. 54, 2024, https://doi.org/10.1016/j.dib.2024.110279.
S. Deshpande, K. Shirsath, A. Pashte, P. Loya, S. Shingade, and V. Sambhe, “A Comprehensive Survey of Advancement in Lip Reading Models: Techniques and Future Directions,” IET Image Processing, vol. 19, no. 1, p. e70095, 2025, https://doi.org/10.1049/ipr2.70095.
T. Afouras, J. S. Chung dan A. Zisserman, “LRS3-TED: a large-scale dataset for visual speech recognition,” arXiv preprint arXiv:1809.00496, 2018, https://doi.org/10.48550/arXiv.1809.00496.
C. T. S. L. Chen, Y. Kristian and E. R. Setyaningsih, "Audio-Visual Speech Reconstruction for Communication Accessibility: A ConvLSTM Approach to Indonesian Lip-to-Speech Synthesis," 2025 International Conference on Data Science and Its Applications (ICoDSA), pp. 770-776, 2025, https://doi.org/10.1109/ICoDSA67155.2025.11157146.
T. Afouras, J. S. Chung, A. Senior, O. Vinyals and A. Zisserman, "Deep Audio-Visual Speech Recognition," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 8717-8727, 2022, https://doi.org/10.1109/TPAMI.2018.2889052.
A. Rachman, R. Hidayat and H. A. Nugroho, "Analysis of the Indonesian vowel /e/ for lip synchronization animation," 2017 4th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), pp. 1-5, 2017, https://doi.org/10.1109/EECSI.2017.8239114.
A. Kurniawan and S. Suyanto, "Syllable-Based Indonesian Lip Reading Model," 2020 8th International Conference on Information and Communication Technology (ICoICT), pp. 1-6, 2020, https://doi.org/10.1109/ICoICT49345.2020.9166217.
S. Recanatesi, M. Farrell, M. Advani, T. Moore, G. Lajoie, and E. Shea-Brown, “Dimensionality compression and expansion in deep neural networks,” arXiv preprint arXiv:1906.00443, 2019, https://doi.org/10.48550/arXiv.1906.00443.
R. Yadav, A. Sardana, V. P. Namboodiri and R. M. Hegde, "Speech Prediction in Silent Videos Using Variational Autoencoders," ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 2021, pp. 7048-7052, 2021, https://doi.org/10.1109/ICASSP39728.2021.9414040.
C. B. Vennerød, A. Kjærran, and E. S. Bugge, “Long short-term memory RNN,” arXiv preprint arXiv:2105.06756, 2021, https://doi.org/10.48550/arXiv.2105.06756.
K. Dedes, A. B. P. Utama, A. P. Wibawa, A. N. Afandi, A. N. Handayani dan L. Hernandez, “Neural Machine Translation of Spanish-English Food Recipes Using LSTM,” JOIV: International Journal on Informatics Visualization, vol. 6, no. 2, pp. 290-297, 2022, https://doi.org/10.30630/joiv.6.2.804.
W. T. Handoko, Muladi dan A. N. Handayani, “Forecasting Solar Irradiation on Solar Tubes Using the LSTM Method and Exponential Smoothing,” Jurnal Ilmiah Teknik Elektro Komputer dan Informatika, vol. 9, pp. 649-660, 2023, https://doi.org/10.26555/jiteki.v9i3.26395.
A. Graves and J. Schmidhuber, "Framewise phoneme classification with bidirectional LSTM networks," Proceedings. 2005 IEEE International Joint Conference on Neural Networks, 2005., pp. 2047-2052 vol. 4, 2005, https://doi.org/10.1109/IJCNN.2005.1556215.
K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink and J. Schmidhuber, "LSTM: A Search Space Odyssey," in IEEE Transactions on Neural Networks and Learning Systems, vol. 28, no. 10, pp. 2222-2232, Oct. 2017, https://doi.org/10.1109/TNNLS.2016.2582924.
K. Cho, B. Van Merriënboer, D. Bahdanau, and Y. Bengio, “On the properties of neural machine translation: Encoder-decoder approaches,” arXiv preprint arXiv:1409.1259, 2014, https://doi.org/10.48550/arXiv.1409.1259.
M. T. Luong, H. Pham and C. D. Manning, “Effective approaches to attention-based neural machine translation,” arXiv preprint arXiv:1508.04025, 2015, https://doi.org/10.48550/arXiv.1508.04025.
C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi and J. Zhong, "Attention Is All You Need In Speech Separation," ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 21-25, 2021, https://doi.org/10.1109/ICASSP39728.2021.9413901.
C. Suardi, A. N. Handayani, R. A. Asmara, A. P. Wibawa, L. N. Hayati and H. Azis, "Design of Sign Language Recognition Using E-CNN," 2021 3rd East Indonesia Conference on Computer and Information Technology (EIConCIT), pp. 166-170, 2021, https://doi.org/10.1109/EIConCIT50028.2021.9431877.
G. Brauwers and F. Frasincar, "A General Survey on Attention Mechanisms in Deep Learning," in IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 4, pp. 3279-3298, 2023, https://doi.org/10.1109/TKDE.2021.3126456.
M. R. A. R. Maulana and M. I. Fanany, "Sentence-level Indonesian lip reading with spatiotemporal CNN and gated RNN," 2017 International Conference on Advanced Computer Science and Information Systems (ICACSIS), pp. 375-380, 2017, https://doi.org/10.1109/ICACSIS.2017.8355061.
T. Procter and A. Joshi, “Cultural competency in voice evaluation: considerations of normative standards for sociolinguistically diverse voices,” Journal of Voice, vol. 36, no. 6, pp. 793-801, 2022, https://doi.org/10.1016/j.jvoice.2020.09.025.
M. Kim, J. Hong and Y. M. Ro, "Lip-to-Speech Synthesis in the Wild with Multi-Task Learning," ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1-5, 2023, https://doi.org/10.1109/ICASSP49357.2023.10095582.
A. Ephrat, O. Halperin dan S. Peleg, “Improved Speech Reconstruction from Silent Video,” In Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 455-462, 2017, https://doi.org/10.1109/ICCVW.2017.61.
S. Hegde, R. Mukhopadhyay, C. V. Jawahar, and V. Namboodiri, “Towards accurate lip-to-speech synthesis in-the-wild,” In Proceedings of the 31st ACM International Conference on Multimedia, pp. 5523-5531, 2023, https://doi.org/10.1145/3581783.3611787.
K. W. Cheuk, H. Anderson, K. Agres and D. Herremans, "nnAudio: An on-the-Fly GPU Audio to Spectrogram Conversion Toolbox Using 1D Convolutional Neural Networks," in IEEE Access, vol. 8, pp. 161981-162003, 2020, https://doi.org/10.1109/ACCESS.2020.3019084.
V. Kazemi dan J. Sullivan, “One Millisecond Face Alignment with an Ensemble of Regression Trees,” In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1867-1874, 2014, https://doi.org/10.1109/CVPR.2014.241.
Y. Zhang, J. Zhang, Q. Wang, and Z. Zhong, “Dynet: Dynamic convolution for accelerating convolutional neural networks,” arXiv preprint arXiv:2004.10694, 2020, https://doi.org/10.48550/arXiv.2004.10694.
A. W. Rix, J. G. Beerends, M. P. Hollier and A. P. Hekstra, "Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs," 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), pp. 749-752 vol.2, 2001, https://doi.org/10.1109/ICASSP.2001.941023.
C. H. Taal, R. C. Hendriks, R. Heusdens and J. Jensen, "A short-time objective intelligibility measure for time-frequency weighted noisy speech," 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 4214-4217, 2010, https://doi.org/10.1109/ICASSP.2010.5495701.
J J. Jensen and C. H. Taal, "An Algorithm for Predicting the Intelligibility of Speech Masked by Modulated Noise Maskers," in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp. 2009-2022, 2016, https://doi.org/10.1109/TASLP.2016.2585878.
A. Alghamdi and W. -Y. Chan, "Modified ESTOI for improving speech intelligibility prediction," 2020 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), pp. 1-5, 2020, https://doi.org/10.1109/CCECE47787.2020.9255677.
Y. Leung, J. Oates, V. Papp, and S. P. Chan, ‘Speaking fundamental frequencies of adult speakers of Australian English and effects of sex, age, and geographical location,” Journal of Voice, vol. 36, no. 3, p. 434-e1, 2022, https://doi.org/10.1016/j.jvoice.2020.06.014.
A. Serrurier and C. Neuschaefer-Rube, “Morphological and acoustic modeling of the vocal tract,” The Journal of the Acoustical Society of America, vol. 153, no. 3, pp. 1867-1886, 2023, https://doi.org/10.1121/10.0017356.
Published
How to Cite
Issue
Section
License
Copyright (c) 2025 Eka Rahayu Setyaningsih, Anik Nur Handayani, Wahyu Sakti Gunawan Irianto, Yosi Kristian

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See The Effect of Open Access).

This journal is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

