
Naive Bayes for Thesis Labeling
DOI:
https://doi.org/10.12928/mf.v3i1.3763Keywords:
Confusion Matrix, Thesis Title, K-Fold Cross Validation, Classifitcation, Naive BayesAbstract
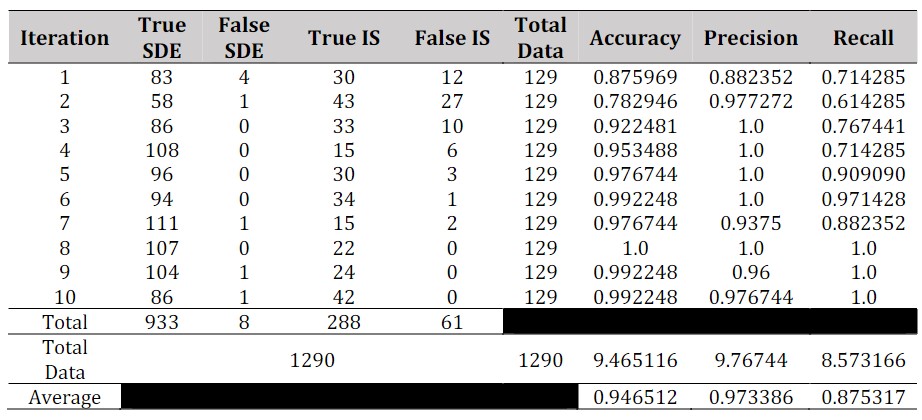
The thesis preparation in the Department of Informatics Universitas Ahmad Dahlan is divided into two areas of interest, namely Intelligent Systems and Software and Data Engineering. Existing thesis title data is only used as an archive and has never been processed or classified to determine the trend of thesis topics based on student interest each year. The stages include data collection, the data is divided into two parts (training data and test data), manual labeling of training data, text preprocessing, and classification using Naive Bayes. The results show the trend of thesis title taking from 2013 to 2018 shows the thesis trend in the field of Intelligent Systems and Software. Accuracy testing uses Confusion Matrix and K-Fold Cross Validation with a k value is 10, has a value of 94.60%, a precision of 97.30%, and a recall of 85.70%.
References
S. Kurniawati, D. Suryadarma, L. Bima, and A. Yusrina, “Education in Indonesia: A white elephant?,” J. Southeast Asian Econ., vol. 35, no. 2, pp. 185–199, 2018, doi: 10.1355/ae35-2e.
DPR-RI and P. R. INDONESIA, UNDANG-UNDANG REPUBLIK INDONESIA NOMOR 12 TAHUN 2012 TENTANG PENDIDIKAN TINGGI. 2012.
M. A. Alsubaei, “Curriculum Development: Teacher Involvement in Curriculum Development,” J. Educ. Pract., vol. 7, no. 9, pp. 106–107, 2016. Available at : https://eric.ed.gov/?id=EJ1095725
O. Ogundare and N. Wiggins, “Identifying Sub-documents in a Composite Scanned Document Using Naive Bayes, Levenshtein Distance and Domain Driven Knowledge Base,” 5th Int. Conf. Soft Comput. Mach. Intell. ISCMI 2018, pp. 84–87, 2018, doi: 10.1109/ISCMI.2018.8703245.
Z. Xiang, Z. Schwartz, J. H. Gerdes Jr, and M. Uysal, “What can big data and text analytics tell us about hotel guestexperience and satisfaction?,” Int. J. Hosp. Manag., vol. 44, pp. 120–130, 2015. DOI : https://doi.org/10.1016/j.ijhm.2014.10.013
J. H. Suh, C. H. Park, and S. H. Jeon, “Applying text and data mining techniques to forecasting the trend of petitions filed to e-people,” Expert Syst. with Appl. 37, pp. 7255–7268, 2010. DOI : https://doi.org/10.1016/j.eswa.2010.04.002
A. N. Khusna and I. Agustina, “Implementation of Information Retrieval Using TF-IDF Weighting Method On Detik.Com’s Website,” TSSA-IEEE, 2018. DOI : 10.1109/TSSA.2018.8708744.
Al. Alshalabi, H. Hamood, S. Tiun, N. Omar, and M. Albared, “Experiments on the Use of Features election and Machine Learning Methods in Automatic Malay Text Categorization,” ICEEI, 2013. DOI : http://dx.doi.org/10.1016/j.protcy.2013.12.254
M. S. Mubarok, A. Adiwijaya, and M. D. Aldhi, “Aspect-based sentiment analysis to review products using Naïve Bayes,” AIP Conf. Proc., vol. 1867, no. August, 2017, doi: 10.1063/1.4994463.
M. Allahyari et al., “A brief survey of text mining: Classification, clustering and extraction techniques,” arXiv, 2017. Available at : https://arxiv.org/abs/1707.02919
C. Dreisbach, T. A. Koleck, P. E. Bourne, and S. Bakken, “A systematic review of natural language processing and text mining of symptoms from electronic patient-authored text data,” Int. J. Med. Inform., vol. 125, no. December 2018, pp. 37–46, 2019, doi: 10.1016/j.ijmedinf.2019.02.008.
N. P. Katariya and M. S. Chaundri, “Text Preprocessing for Text Mining Using Side Information,” vol. 3, pp. 3–7, 2015. Available at : https://ijcsma.com/publications/january2015/V3I102.pdf
A. Pinto, H. Goncalo Oliveira, and A. Oliveira Alves, “Comparing the performance of different NLP toolkits in formal and social media text,” 5th Symp. Lang. Appl. Technol., 2016. DOI : http://dx.doi.org/10.4230/OASIcs.SLATE.2016.3
N. Alami, M. Meknassi, S. A. Ouatik, and N. Ennahnahi, “Impact of stemming on Arabic text summarization,” 4th IEEE Int. Colloq. Inf. Sci. Technol., pp. 338–343, 2016. DOI : 10.1109/CIST.2016.7805067.
M. Zampieri et al., “Language Identification and Morphosyntactic Tagging,” Secind Vardial Eval. Campaign, 2018. Available at : https://aclanthology.org/W18-3901/
E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S. Singh, “niversal adversarial triggers for attacking and analyzing NLP,” arXiv, 2019. Available at : https://arxiv.org/abs/1908.07125
M. Hosseinalizadeh et al., “Gully headcut susceptibility modeling using functional trees, naïve Bayes tree, and random forest models,” Geoderma, vol. 342, no. October 2018, pp. 1–11, 2019, doi: 10.1016/j.geoderma.2019.01.050.
S. A. Pattekari and A. Parveen, “Prediction System for Heart Disease Using Naive Bayes,” Int. J. Adv. Comput. Math. Sci., vol. 3, no. 3, pp. 290–294, 2012. DOI : http://dx.doi.org/10.4066/biomedicalresearch.29-18-620
O. Caelen, “A Bayesian interpretation of the confusion matrix,” Ann. Math. Artif. Intell., vol. 81, no. 3–4, pp. 429–450, 2017, doi: 10.1007/s10472-017-9564-8.
J. Mohajon, “Confusion Matrix for Your Multi-Class Machine Learning Model | by Joydwip Mohajon | Towards Data Science,” 2017. Available at : https://towardsdatascience.com/confusion-matrix-for-your-multi-class-machine-learning-model-ff9aa3bf7826
H. Moayedi, A. Osouli, H. Nguyen, and A. S. A. Rashid, “A novel Harris hawks’ optimization and k-fold cross-validation predicting slope stability,” Eng. Comput., pp. 1–11, 2019. DOI : 10.1007/s00366-019-00828-8
Downloads
Published
Issue
Section
License
Copyright (c) 2021 Dimas Chaerul Ekty Saputra

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Start from 2019 issues, authors who publish with JURNAL MOBILE AND FORENSICS agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License (CC BY-SA 4.0) that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work.

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.





