
Pelabelan Kelas Kata Bahasa Jawa Menggunakan Hidden Markov Model
DOI:
https://doi.org/10.12928/mf.v2i2.2450Keywords:
Bahasa Jawa, Hidden Markov Model, Kelas Kata, Most Probable POS-Tag, POS taggingAbstract
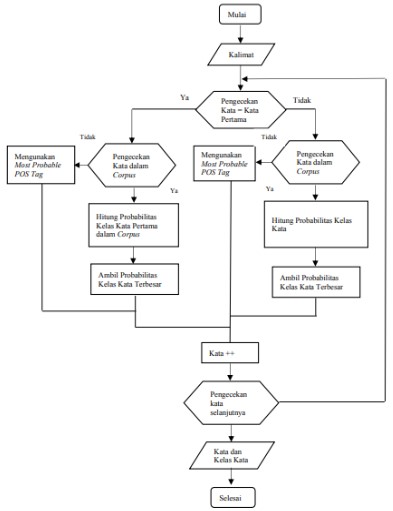
Part of Speech Tagging atau POS Tagging adalah proses memberikan label pada setiap kata dalam sebuah kalimat secara otomatis. Penelitian ini menggunakan algoritma Hidden Markov Model (HMM) untuk proses POS Tagging. Perlakuan untuk unknown words menggunakan Most Probable POS-Tag. Dataset yang digunakan berupa 10 cerita pendek berbahasa Jawa terdiri dari 10.180 kata yang telah diberikan tagset Bahasa Jawa. Pada penelitian ini proses POS Tagging menggunakan dua skenario. Skenario pertama yaitu menggunakan algoritma Hidden Markov Model (HMM) tanpa menggunakan perlakuan untuk unknown words. Skenario yang kedua menggunakan HMM dan Most Probable POS-Tag untuk perlakuan unknown words. Hasil menunjukan skenario pertama menghasilkan akurasi sebesar 45.5% dan skenario kedua menghasilkan akurasi sebesar 70.78%. Most Probable POS-Tag dapat meningkatkan akurasi pada POS Tagging tetapi tidak selalu menunjukan hasil yang benar dalam pemberian label. Most Probable POS-Tag dapat menghilangkan probabilitas bernilai Nol dari POS Tagging Hidden Markov Model. Hasil penelitian ini menunjukan bahwa POS Tagging dengan menggunakan Hidden Markov Model dipengaruhi oleh perlakuan terhadap unknown words, perbendaharaan kata dan hubungan label kata pada dataset.
Part of Speech Tagging or POS Tagging is the process of automatically giving labels to each word in a sentence. This study uses the Hidden Markov Model (HMM) algorithm for the POS Tagging process. Treatment for unknown words uses the Most Probable POS-Tag. The dataset used is in the form of 10 short stories in Javanese consisting of 10,180 words which have been given the Javanese tagset. In this study, the POS Tagging process uses two scenarios. The first scenario is using the Hidden Markov Model (HMM) algorithm without using treatment for unknown words. The second scenario uses HMM and Most Probable POS-Tag for treatment of unknown words. The results show that the first scenario produces an accuracy of 45.5% and the second scenario produces an accuracy of 70.78%. Most Probable POS-Tag can improve accuracy in POS Tagging but does not always produce correct labels. Most Probable POS-Tag can remove zero-value probability from POS Tagging Hidden Markov Model. The results of this study indicate that POS Tagging using the Hidden Markov Model is influenced by the treatment of unknown words, vocabulary and word label relationships in the dataset.
References
Aji P. Wibawa, Andrew Nafalski, Neil Murray, and Wayan F. Mahmudy, "Parallel Text Processing: Alignment of Indonesian to Javanese Language," Int. J. Inf. Control Comput. Sci., vol. 6.0, no. 2, Jan. 2014, doi: 10.5281/zenodo.1335958.
W. E. S. Nurlina, Herawati, D. Sutono, and T. Suwondo, Pembentukan Kata dan Pemilihan Kata dalam Bahasa Jawa. Jakarta: Pusat Bahasa Departemen Pendidikan Nasional, 2004.
G. Quinn, "Teaching Javanese respect usage to foreign learners," Electron. J. Foreign Lang. Teach., vol. 8, pp. 362-370, Dec. 2011.
A. K. Ogloblin, "Javanese," in The Austronesian Languages of Asia and Madagascar, Routledge Language Family Series, 2005, p. 590.
Wedhawati, Tata bahasa Jawa mutakhir. Kanisius, 2006.
A. Munandar, "Pemakaian Bahasa Jawa Dalam Situasi Kontak Bahasa Di Daerah Istimewa Yogyakarta," HUMANIORA, vol. 25, pp. 92-102, Feb. 2013.
H. B. Mardikantoro, "Pergeseran Bahasa Jawa Dalam Ranah Keluarga Pada Masyarakat Multibahasa Diwilayah Kabupaten Brebes," HUMANIORA, vol. 19, pp. 43-51, Feb. 2007.
F. H. Tondo, "Kepunahan Bahasa-Bahasa Daerah: Faktor Penyebab Dan Implikasi Etnolinguistis," J. Masy. Dan Budaya, vol. 11, no. 2, pp. 277-296, 2009.
N. X. Bach, N. D. Linh, and T. M. Phuong, "An empirical study on POS tagging for Vietnamese social media text," Comput. Speech Lang., vol. 50, pp. 1-15, Jul. 2018, doi: 10.1016/j.csl.2017.12.004.
N. Sabloak, B. Agung Hardono, and D. Alamsyah, "Part-of-Speech (POS) Tagging Bahasa Indonesia Menggunakan Algoritma Viterbi," Unpublished, Jul. 2016.
A. Mulyanto, Y. A. Nurhuda, and N. Wiyanto, "Penyelesaian Kata Ambigu Pada Proses POS Tagging Menggunakan Algoritma Hidden Markov Model ( HMM )," Pros. Semin. Nas. Metode Kuantitatif, vol. 0, no. 1, Nov. 2017.
A. Azimizadeh, M. Arab, and S. R. Quchani, "Persian part of speech tagger based on Hidden Markov Model," 2008, pp. 121-128.
L. M. S. Martinez, C. A. Cobos, and J. C. Corrales, "Memetic Algorithm Based on Global-Best Harmony Search and Hill Climbing for Part of Speech Tagging," in Mining Intelligence and Knowledge Exploration: 5th International Conference, MIKE 2017, Hyderabad, India, December 13-15, 2017, Proceedings, A. Ghosh, R. Pal, and R. Prasath, Eds. Springer International Publishing, 2017.
K. Widhiyanti and A. Harjoko, "POS Tagging Bahasa Indonesia Dengan HMM dan Rule Based," J. Inform., vol. 8, no. 2, Mar. 2013, doi: 10.21460/inf.2012.82.125.
H. Mohamed, N. Omar, and M. J. A. Aziz, "Statistical malay part-of-speech (POS) tagger using Hidden Markov approach," in 2011 International Conference on Semantic Technology and Information Retrieval, STAIR 2011, 2011, pp. 231-236, doi: 10.1109/STAIR.2011.5995794.
S. Dandapat, S. Sarkar, and A. Basu, "(PDF) A Hybrid Model for Part-of-Speech Tagging and its Application to Bengali.," Int. Conf. Comput. Intell., pp. 169-172.
H. R. U. Pramudita Ema; Amborowati, Armadyah, "Pengaruh Part of Speech Tagging Berbasis Aturan dan Distribusi Probabilitas Maximum Entropy untuk Bahasa Jawa Krama," J. Buana Inform., no. Vol 7, No 4 (2016): Jurnal Buana Informatika Volume 7 Nomor 4 Oktober 2016, 2016.
J. W. M. Verhaar, Pengantar Linguistik. Yogyakarta: UGM Press, 1982.
H. Alwi, Tatabahasa Baku Bahasa Indonesia. Balai Pustaka, 1993.
Y. Sudaryat, "Pemarkah Pertarafan Dalam Bahasa Sunda," Adab. J. Bhs. Dan Sastra, vol. 12, no. 2, pp. 263-282, Dec. 2013, doi: 10.14421/ajbs.2013.12203.
A. B. Setiyanto, Parama Sastra Bahasa Jawa. Yogyakarta: Panji Pustaka, 2007.
D. Setyohadi, "Perbaikan Performansi Klasifikasi Dengan Preprocessing Iterative Partitioning Filter Algorithm," telematika, Apr. 2017.
L. Setyowati, Bertalya, and T. W. R. Ningsih, "Aplikasi Transkripsi Fonetik Bahasa Indonesia Berdasarkan IPA (The International Phonetic Association) Untuk BIPA," Pros. Semin. Ilm. Nas. Komput. Dan Sist. Intelijen KOMMIT 2014, vol. 8, Oktober 2014.
Jurafsky, D and Martin, J, H, Speech and Language Processing"An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition". New Jersey: Prentice Hall, 2000.
Y. Wibisono, "Penggunaan Hidden Markov Model untuk Kompresi Kalimat," Jan. 2008.
A. Farizki Wicaksono and A. Purwarianti, "HMM Based Part-of-Speech Tagger for Bahasa Indonesia," Jan. 2010.
M. Haulrich, "Different Approaches to Unknown Words in a Hidden Markov Model Part-of Speech Tagger," Unpublished, May 2009.
Downloads
Published
Issue
Section
License
Copyright (c) 2020 Mohammad Mursyit, Aji Prasetya Wibawa, Ilham Ari Elbaith Zaeni, Harits Ar Rosyid

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Start from 2019 issues, authors who publish with JURNAL MOBILE AND FORENSICS agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under a Creative Commons Attribution License (CC BY-SA 4.0) that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work.

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.





