ISSN: 2685-9572 Buletin Ilmiah Sarjana Teknik Elektro
Vol. 8, No. 2, April 2026, pp. 561-575
Trends and Gaps in Transformer-Based EEG Modeling: A Review of Recent Developments
Yuri Pamungkas 1, Abdul Karim 2, Myo Min Aung 3, Muhammad Nur Afnan Uda 4, Uda Hashim 5
1 Department of Medical Technology, Institut Teknologi Sepuluh Nopember, Indonesia
2 Department of Artificial Intelligence Convergence, Hallym University, Republic of Korea
3 Department of Mechatronics Engineering, Rajamangala University of Technology Thanyaburi, Thailand
4 Department of Electronic Engineering (Computer), Universiti Malaysia Sabah, Malaysia
5 Department of Electrical and Electronics Engineering, Universiti Malaysia Sabah, Malaysia
ARTICLE INFORMATION |
| ABSTRACT |
Article History: Received 10 October 2025 Revised 30 December 2025 Accepted 07 May 2026 |
| 
In recent years, Transformer-based deep learning architectures have emerged as a powerful paradigm for modeling EEG signals, offering superior capability in capturing spatial–temporal dependencies compared to traditional convolutional or recurrent networks. However, the diversity of model designs, limited dataset generalization, and lack of standardization have created challenges in evaluating their true potential for real-world applications. This review addresses these issues by systematically examining the evolution, performance, and methodological trends of Transformer-based EEG models published between 2022 and 2024, highlighting both achievements and research gaps. The main contribution of this study is to provide a comprehensive mapping and critical analysis of Transformer architectures applied to EEG classification, feature extraction, and signal decoding tasks. Using the Scopus database, a structured search was conducted following specific inclusion criteria (English, peer-reviewed, open-access journal papers from 2022–2024) and a well-defined query combining EEG and Transformer-related keywords. Data from 63 eligible studies were extracted and categorized according to authorship, dataset, architecture type, EEG application, and evaluation metrics. Results show that hybrid Transformer models dominate recent research, achieving accuracies above 90% in tasks such as motor imagery, emotion recognition, seizure detection, and sleep staging. Pure Transformers like ViT and BERT-like models also demonstrate competitive performance but face scalability and interpretability challenges. In conclusion, Transformer-based EEG modeling is advancing rapidly, yet future efforts must focus on model efficiency, explainability, and benchmark standardization to enable broader clinical and real-world adoption. |
Keywords: Electroencephalography (EEG); Transformer Architecture; Brain-Computer Interface (BCI); Deep Learning; Attention-Based Modeling |
Corresponding Author: Yuri Pamungkas, Department of Medical Technology, Institut Teknologi Sepuluh Nopember, Indonesia. Email: yuri@its.ac.id |
This work is open access under a Creative Commons Attribution-Share Alike 4.0 
|
Document Citation: Y. Pamungkas, A. Karim, M. M. Aung, M. N. A. Uda, and U. Hashim, “Trends and Gaps in Transformer-Based EEG Modeling: A Review of Recent Developments,” Buletin Ilmiah Sarjana Teknik Elektro, vol. 8, no. 2, pp. 561-575, 2026, DOI: 10.12928/biste.v8i2.14933. |
- INTRODUCTION
Electroencephalography (EEG) is a non-intrusive brain imaging modality that captures electrical brain activity with very fine-grained temporal precision, providing crucial insights into cognitive processes, neural disorders, and BCIs [1][2]. Over the past decade, the accelerated advancement of artificial intelligence and deep learning techniques has fundamentally reshaped EEG analysis paradigms from conventional feature-based methods into data-driven modeling [3][4]. Early approaches (such as SVM, k-NN, and shallow neural networks) were limited in effectively addressing the inherently non-stationary characteristics and high noise levels present in EEG signals [5]-[7]. Subsequent developments in deep learning, particularly CNNs and RNNs, improved spatial and temporal feature extraction but still struggled to capture extended-range dependencies and interactions across multiple EEG channels [8][9]. This challenge makes a key research problem, how to effectively model holistic spatiotemporal dependencies over time in EEG data for improved accuracy, generalization, and interpretability.
The rise of Transformer-based architectural frameworks has brought a fundamental conceptual transformation in time-series and biomedical signal modeling [10]. Initially developed for NLP, Transformers employ attention-driven self-referential mechanisms that enable the model to learn context-aware relationships among temporally or spatially separated elements in a sequence [11]. This capability has proven demonstrated substantial advantages for EEG signal analysis, where inter-channel and temporal dependencies play a vital role [12]. More recent architectural adaptations (such as Vision Transformers (ViT), Time-Series Transformers, and hybrid CNN-Transformer frameworks) have been successfully applied to tasks derived from EEG signal analysis including affective state recognition, seizure detection, motor imagery classification, and sleep staging. These models outperform conventional deep networks by leveraging global attention mechanisms to learn spatial-temporal interactions, offering new possibilities for clinical and cognitive applications [13]-[15].
However, despite the promising performance, several gaps remain in the current Transformer-based EEG research landscape. Many studies use small or single-source datasets, limiting reproducibility and generalizability [16]-[18]. Furthermore, high model complexity and limited interpretability challenge their deployment in real-world biomedical environments [19]. There is also a lack of standardized benchmarks and explainability frameworks to validate Transformer-based EEG models across datasets and applications [20]. Addressing these limitations requires a structured synthesis of existing research to understand what has been achieved and what remains underexplored.
The aim of this review is to systematically analyze and summarize recent developments in Transformer-based EEG modeling, focusing on architectures, datasets, applications, and evaluation strategies. By identifying consistent trends and critical gaps, this review provides an evidence-based perspective on how attention-based deep learning is reshaping EEG analysis. The contribution of the research is to present a comprehensive mapping and critical evaluation of Transformer-based EEG studies, highlighting methodological innovations, performance insights, and future research directions toward more interpretable, scalable, and clinically applicable EEG models. This work not only situates current progress within the broader evolution of AI in biomedical signal processing but also establishes a roadmap for advancing Transformer-based approaches in brain signal understanding.
- METHODOLOGY
This review employed a rigorous and methodologically organized strategy to identify, select, and analyze recent studies focusing on deep learning frameworks grounded in Transformer architectures for the analysis of EEG signals. The literature search was conducted using the Scopus database, which was selected due to its extensive coverage of peer-reviewed and high-quality publications across the fields of biomedical engineering, neuroscience, and artificial intelligence. The search was performed in October 2025 to ensure the inclusion of the most recent and relevant studies. To retrieve articles that directly addressed the integration of Transformer architectures with EEG data analysis, a precisely designed search query was used, combining specific keywords with logical Boolean operators. The final search query was as follows: (“transformer” OR “vision transformer” OR “temporal transformer” OR “spatio-temporal transformer” OR “time series transformer”) AND (“EEG” OR “electroencephalography” OR “brain-computer interface” OR “BCI”) AND (“classification” OR “feature extraction” OR “representation learning” OR “signal decoding” OR “mental state recognition” OR “emotion recognition”). This search query was applied to article titles, abstracts, and keywords to maximize relevance while minimizing unrelated results.
The inclusion criteria were defined to ensure both scientific quality and topical precision. Articles were considered eligible if they were published between 2022 and 2024, written in English, and categorized as peer-reviewed journal articles. To enhance transparency and reproducibility, only open-access publications were included, allowing full access to methodological details and results. Conference proceedings, theses, preprints, and non-peer-reviewed documents were excluded. Studies that did not involve EEG data or Transformer-based architectures were also removed during the screening process. This inclusion strategy ensured that the reviewed papers represent the most current, credible, and accessible contributions in the field.
For each study that met the inclusion criteria, detailed information was extracted following a consistent classification scheme. The extracted data included the author(s), year of publication, dataset used, Transformer architecture employed (such as Vision Transformer, Time-Series Transformer, or hybrid models), EEG task or application (for example, emotion recognition, seizure detection, sleep staging, or BCI classification), and evaluation metrics (including accuracy, precision, recall, etc). This systematic extraction enabled a clear comparison of methodologies and outcomes across studies. The compiled data were then organized into a review Table 1 that allowed thematic categorization and identification of trends, gaps, and future directions. Through this structured methodology, the review aims to provide a comprehensive and evidence-based understanding of how Transformer architectures have been applied in EEG analysis and what methodological challenges remain for future exploration.
Table 1. Summary of Recent Studies on Transformer-based EEG Modeling (2022–2024)
Ref | Author(s) | Year | Dataset | Transformer Architecture | EEG Task / Application | Evaluation Metrics |
[21] | Xie et al. | 2022 | PhysioNet EEG Motor Movement/Imagery | s-Trans, t-Trans, s-CTrans, t-Ctrans, f-Ctrans | Motor imagery EEG classification | Accuracy 83.31% (2-class), 74.44% (3-class), 64.22% (4-class) |
[22] | Hussein et al. | 2022 | CHB-MIT, AES-Kaggle, Melbourne iEEG | Multi-Channel ViT | Seizure prediction | AUC up to 0.99, Accuracy 99.8% |
[23] | Liu et al. | 2022 | MASC | Convolutional Transformer + ResNet–LSTM | Mask detection from speech | UAR 82.2%, AUC 0.874 |
[24] | Murphy et al. | 2022 | NIH, CheXpert, PadChest, MIMIC-CXR, MURA | DeiT-B, DeiT-Ti | Radiograph disease classification | AUC 0.78–0.887 |
[25] | Wang et al. | 2022 | NHB-EEG | GLU-Oneformer | Driving fatigue detection | Accuracy 86.97%, F1 85.23% |
[26] | Xu et al. | 2022 | Custom (23 subjects) | Transformer encoder | Stress classification | Accuracy up to 92.7% |
[27] | He et al. | 2023 | VitalDB | Transformer + LSTM + GRN | Depth of anesthesia prediction | MDPE 0.47–1.14, RMSE 4.7 |
[28] | Wang et al. | 2023 | CHB-MIT, Xuanwu sEEG | CWTFFNet + Multi-Graph Conv | Seizure prediction | AUC up to 0.984 |
[29] | Ma et al. | 2023 | ERP CORE N400 | Erp-Transformer | Semantic EEG classification | Accuracy 89.92%, Recall 90.51% |
[30] | Chen et al. | 2023 | OpenNeuro | Dual-Branch CNN + ViT | Alzheimer’s classification | Accuracy 80.23%, AUC 82.19% |
[31] | Wang et al. | 2023 | Benchmark, BETA, UCSD | GZSL-SSVEP Transformer | SSVEP BCI classification | Accuracy 95.4%, ITR 245.6 |
[32] | Dang et al. | 2023 | Custom clinical EEG | TT-SGCN | Encephalitis classification | Accuracy 82.23% |
[33] | Yao et al. | 2023 | ISRUC-S3, PSG-35 | VSTTN (Swin + Longformer) | Sleep stage classification | Accuracy 89.24%, F1 87.61% |
[34] | Zhou et al. | 2023 | Custom + DEAP | Dual-Channel Transformer | Emotion recognition | Accuracy 97.3% |
[35] | Chen et al. | 2023 | BCI IV 2a, 2b, MI3 | CSP + Transformer | Motor imagery BCI | Accuracy up to 89.6% |
[36] | Song et al. | 2023 | BCI IV 2a, 2b, SEED | EEG Conformer | Motor imagery & emotion | Accuracy up to 92.4% |
[37] | Song et al. | 2023 | BCI IV 2a, 2b | Global Adaptive Transformer | Cross-subject MI | Accuracy 76.6–84.4% |
[38] | Zhang et al. | 2023 | KU MI-EEG, BCI 2a | LGCT | Motor imagery | Accuracy up to 81% |
[39] | Hu et al. | 2023 | BCI IV 2a, 2b | MSATNet | Motor imagery | Accuracy up to 89.34% |
[40] | Wang et al. | 2023 | Huashan Hospital | ECA Swin Transformer | Stroke rehabilitation BCI | Accuracy 87.67% |
[41] | Lu et al. | 2023 | SEED, SEED-IV | Bi-ViTNet | Emotion recognition | Accuracy 96.25% |
[42] | Zhao et al. | 2023 | Juntendo Hospital iEEG | ViT | Seizure detection | Accuracy >90%, F1 0.92 |
[43] | Tian et al. | 2023 | CHB-MIT | CNNs Meet Transformers | Seizure detection | Accuracy up to 100% |
[44] | Lih et al. | 2023 | Custom (121 participants) | EpilepsyNet | Epilepsy detection | Accuracy 85% |
[45] | Jin et al. | 2023 | Custom fNIRS | CNN–Transformer | Emotion recognition | Accuracy 86.7% |
[46] | Tigga et al. | 2023 | OpenNeuro | AttGRUT | Depression detection | Accuracy 98.67% |
[47] | Gour et al. | 2023 | TDBRAIN | Multi-head Transformer | Psychiatric EEG classification | Accuracy up to 65.8% |
[48] | Oh et al. | 2024 | SHHS | CNN–Transformer Hybrid | Sleep onset prediction | MAE 9.8 min |
[49] | Khan et al. | 2024 | ADNI | Mixed Transformer + U-Net | Alzheimer’s diagnosis | Accuracy 98% |
[50] | Zhang et al. | 2024 | Sleep-EDF | TSEDSleepNet | Sleep stage classification | Accuracy up to 88.9% |
[51] | Wang et al. | 2024 | Mumtaz2016, Arizona2020 | CNN–Transformer + Diffusion | Depression diagnosis | Accuracy 93.7% |
[52] | Lee et al. | 2024 | BCI 2020 Track #3–4 | DeiT-based Calibratable Net | Robotic arm control | Accuracy >80% |
[53] | Liu et al. | 2024 | SparrKULee, DTU | ADT Network | Speech envelope reconstruction | Score ≈0.168 |
[54] | Pradeepkumar et al. | 2024 | Sleep-EDF, SHHS | Cross-Modal Transformer | Sleep stage classification | Accuracy up to 84.7% |
[55] | Shi et al. | 2024 | CHB-MIT, Kaggle AES | B2-ViT | Seizure prediction | AUC up to 0.923 |
[56] | Liu et al. | 2024 | Qilu Hospital SCI, BCI IV 2a | EMPT | MI-EEG for SCI | Accuracy 95.2% |
[57] | Beiramvand et al. | 2024 | Muse, Enobio | Transformer | Mental workload | Accuracy up to 88% |
[58] | Kim et al. | 2024 | BCI IV-2a, IV-2b, Sleep-EDF | Dfformer | General EEG decoding | Accuracy up to 0.84 |
[59] | Ren et al. | 2024 | BNCI, LSC Speller | CNN + Transformer | Error-related potentials | Accuracy up to 78.7% |
[60] | Chen et al. | 2024 | BCI IV 2a, 2b | TBTSCTnet | Motor imagery | Accuracy up to 78.2% |
[61] | Ke et al. | 2024 | DEAP | Capsule–Transformer | Emotion recognition | Accuracy up to 96.88% |
[62] | Lu et al. | 2024 | SEED, SEED-IV | Convolution Interactive Transformer | Emotion recognition | Accuracy 98.57% |
[63] | Peng et al. | 2024 | CHSZ, TUSZ | MBMD Transformer | Seizure subtype classification | Accuracy up to 93.5% |
[64] | Li et al. | 2024 | Local, COG-BCI | MST-Net | Cognitive load | Accuracy up to 89.1% |
[65] | Ding et al. | 2024 | Benchmark, BETA | CNN-Former | Asynchronous SSVEP | Accuracy 93.2% |
[66] | Qin et al. | 2024 | BCIC-IV-2a, MAMEM-II | TBEEG | Dual-domain EEG decoding | Accuracy 91.4% |
[67] | Chen et al. | 2024 | DEAP, SEED, SEED-IV | DAMGCN | Emotion recognition | Accuracy 99.42% |
[68] | Pang et al. | 2024 | SEED, SEED-IV | MSMAE | Cross-session emotion | Accuracy 80.9% |
[69] | Luo et al. | 2024 | Tsinghua RSVP, PhysioNet | CST-TVA-DRTL | RSVP EEG classification | BA up to 93.1%, AUC 0.96 |
[70] | Hu et al. | 2024 | SEED, SEED-IV | STAFNet | Emotion recognition | Accuracy up to 97.9% |
[71] | Lee et al. | 2024 | MOBI | Bimodal Transformer | EEG gameplay classification | Accuracy 88.86% |
[72] | Yao et al. | 2024 | SEED, DEAP | EEG ST-TCNN | Emotion classification | Accuracy 96.67% |
[73] | Du et al. | 2024 | DEAP, SEED | MES-CTNet | Emotion recognition | Accuracy up to 98.3% |
[74] | Li et al. | 2024 | Ear-EEG (Toyama Univ.) | Morlet-ROCKET | SSVEP classification | Accuracy 75.5 ± 6.7% |
[75] | Ye et al. | 2024 | SEED-VIG | CA-ACGAN | Fatigue detection | Accuracy 90.7% |
[76] | Busia et al. | 2024 | CHB-MIT, CHUV | EEGformer | Wearable seizure detection | Accuracy 73–88% |
[77] | Wang et al. | 2024 | DEAP, SEED, DOC | MutaPT | DOC classification | Accuracy 85.7% |
[78] | Feng et al. | 2024 | Custom elderly EEG | ViT + RM + DBO | Emotion recognition | Accuracy 99.35% |
[79] | Yeom et al. | 2024 | BCI IV 2a, 2b | Query-Only Attention Transformer | Motor imagery | Accuracy 84.62% |
[80] | Seraphim et al. | 2024 | MASS, Dreem DOD-H | SPDTransNet | Sleep stage classification | Accuracy 89% |
[81] | Basheer et al. | 2024 | TDBRAIN | SCAM-Learning Transformer | Psychiatric dysfunctions | Accuracy 87.7% |
[82] | Shih et al. | 2024 | Neonatal EEG (Zenodo) | Transformer + EEGNet | HIE severity grading | Accuracy 0.95, F1 0.96 |
[83] | Holguin-Garcia et al. | 2024 | Bonn dataset | CNN–Transformer Encoder | Seizure classification | Accuracy 99.76% |
- RECENT DEVELOPMENTS IN TRANSFORMER-BASED EEG MODELING
- Pure Transformer Models
Pure Transformer architectures, which rely solely on self-attention mechanisms without convolutional or recurrent components, have demonstrated remarkable adaptability in EEG modeling between 2022 and 2024. These models, including Vision Transformer (ViT), Time-Series Transformer (TST), and BERT-like variants, leverage their inherent capacity to represent extended temporal relationships over long time horizons and encode comprehensive contextual interactions spanning multiple EEG channels. Unlike hybrid networks that combine CNNs or RNNs, pure Transformer designs process EEG data as sequences or tokenized patches, allowing them to learn intrinsic spatial–temporal correlations more efficiently. This conceptual transition has facilitated improved cross-domain generalization capability across subjects and datasets, particularly for tasks requiring high-resolution temporal inference such as seizure detection.
One of the earliest implementations was proposed by Xie et al. [21], who introduced multiple Transformer configurations (s-Trans, t-Trans, s-CTrans, t-CTrans, and f-CTrans) applied to PhysioNet EEG motor imagery data. Their model achieved up to 83.31% accuracy in 2-class classification, proving that self-attention alone could effectively model motor-related brain activity. Similarly, Hussein et al. [22] adopted a Multi-Channel Vision Transformer (ViT) for seizure prediction using large-scale EEG datasets (CHB-MIT, AES-Kaggle, Melbourne iEEG) and achieved an outstanding AUC of 0.99 and accuracy of 99.8%, illustrating the capacity of ViT to capture inter-channel relationships in multi-electrode EEG signals. Zhao et al. [42] further validated the robustness of ViT-based models in clinical seizure detection on intracranial EEG from Juntendo Hospital, reaching over 90% accuracy and F1-score of 0.92. These results highlight how pure self-attention mechanisms can excel in pathological EEG tasks traditionally dominated by CNN-based frameworks.
Emotion recognition and mental state decoding have also benefited from pure Transformer designs. Zhou et al. [34] developed a Dual-Channel Transformer trained on DEAP and custom emotion datasets, achieving 97.3% accuracy, while Lu et al. [41] proposed Bi-ViTNet, a bidirectional ViT architecture that enhanced emotion recognition accuracy to 96.25% on SEED and SEED-IV datasets. Both studies demonstrated that global attention improves affective EEG decoding by modeling inter-channel synchronization patterns and temporal dependencies. In a similar context, Hu et al. [70] introduced STAFNet, a self-attention-based Transformer network that achieved 97.9% accuracy in emotion classification, further confirming the dominance of pure attention models in affective computing.
The generalization and scalability of Transformer-based EEG decoding were further explored by Kim et al. [58], who proposed Dfformer, a generalized Transformer architecture for multiple EEG decoding tasks, achieving accuracy up to 84% across datasets such as BCI IV-2a, IV-2b, and Sleep-EDF. Beiramvand et al. [57] also utilized a standard Transformer for mental workload estimation using Muse and Enobio headsets, reporting up to 88% accuracy, emphasizing that even compact, pure Transformer architectures can yield robust performance on low-density EEG systems. Furthermore, Peng et al. [63] proposed an MBMD Transformer for seizure subtype classification across CHSZ and TUSZ datasets, achieving 93.5% accuracy, underscoring the adaptability of self-attention to multi-class clinical EEG problems.
- Hybrid Transformer Models
Hybrid Transformer architectures, which integrate self-attention mechanisms with convolutional, recurrent, or graph-based layers, have become the dominant trend in EEG analysis between 2022 and 2024. These models were developed to address the inherent shortcomings of Transformer-only models in modeling detailed localized dependency patterns and to improve computational resource efficiency when processing EEG signals characterized by high dimensional feature spaces. By combining the Transformers’ capacity for modeling global contextual representations with the CNNs’ strong ability to extract localized features or the RNN-based sequential temporal modeling capability, hybrid frameworks achieve superior performance across diverse EEG tasks such as seizure detection, emotion recognition, sleep staging, and motor imagery classification. This synergistic interaction at the architectural level has proven especially effective in addressing the inherent non-stationary behavior and noise characteristics of EEG signals while improving the transparency of model decision-making and overall robustness can be seen in Table 2.
Several early studies demonstrated the effectiveness of hybrid Transformer designs. Liu et al. [23] combined a Convolutional Transformer with a ResNet–LSTM backbone to detect mask-wearing from speech-related EEG data (MASC dataset), reporting a UAR of 82.2% and AUC of 0.874. Wang et al. [25] proposed GLU-Oneformer, a hybrid Transformer incorporating gating and convolutional components for driving fatigue detection, achieving 86.97% accuracy and F1-score of 85.23%. Xu et al. [26] employed a Transformer encoder integrated with traditional features for stress classification, reaching up to 92.7% accuracy on a custom dataset. These early implementations established the foundation for combining deep feature extraction and self-attention for physiological signal understanding.
The hybridization trend became more pronounced in 2023, where researchers began systematically blending CNN and Transformer layers for specific EEG applications. Chen et al. [30] designed a Dual-Branch CNN + ViT model for Alzheimer’s disease classification using the OpenNeuro dataset, achieving 80.23% accuracy and AUC of 82.19%. Song et al. [36] introduced EEG Conformer, which fused convolutional front-ends with Transformer encoders to jointly capture temporal and spatial EEG dependencies, achieving up to 92.4% accuracy for both motor imagery and emotion tasks. Likewise, Wang et al. [40] utilized an ECA Swin Transformer for stroke rehabilitation BCI, yielding 87.67% accuracy, illustrating how combining CNN attention modules with Transformer blocks enhances clinical EEG modeling.
Further refinements appeared in 2024 with increasingly complex hybrid designs. Oh et al. [48] proposed a CNN–Transformer hybrid for sleep onset prediction, achieving a mean absolute error (MAE) of 9.8 minutes, while Wang et al. [51] used a CNN–Transformer with Diffusion for depression diagnosis, reaching 93.7% accuracy on multi-source EEG datasets (Mumtaz2016, Arizona2020). Ren et al. [59] combined CNN and Transformer modules to classify error-related potentials, achieving 78.7% accuracy, while Ding et al. [65] introduced CNN-Former for asynchronous SSVEP decoding, reporting 93.2% accuracy. These studies demonstrate how CNN layers improve low-level EEG feature encoding, allowing the Transformer component to focus on learning global contextual dependencies across channels and time segments.
Hybrid architectures have also integrated graph and multimodal learning elements. Wang et al. [28] developed CWTFFNet + Multi-Graph Convolution, combining graph-based EEG representations with Transformer attention for seizure prediction, achieving an AUC up to 0.984. Du et al. [73] proposed MES-CTNet, a multimodal EEG–stimuli Transformer for emotion recognition, reaching up to 98.3% accuracy, while Pradeepkumar et al. [54] introduced a Cross-Modal Transformer for sleep stage classification, achieving 84.7% accuracy by fusing EEG and auxiliary physiological data. These works underscore the potential of hybrid Transformers not only in enhancing feature learning but also in enabling multimodal integration for more comprehensive neural decoding.
Table 2. Distribution of Pure and Hybrid Transformer-Based EEG Models
Category | Transformer Models | References |
Pure Transformer | ViT, DeiT, Swin, Longformer, Global Adaptive Transformer, MSMAE, STAFNet, DFformer, TBEEG, DAMGCN, ADT, MBMD, Bi-ViTNet, ECA Swin, MST-Net, EEGformer, SCAM-Learning | [21],[22],[24],[27]-[29],[33],[35],[37]-[43],[55]-[58],[60]-[64],[66]-[70],[73],[75]-[78],[81],[82] |
Hybrid Transformer | CNN–Transformer, LSTM–Transformer, GRU–Transformer, GCN–Transformer, Capsule–Transformer, GAN–Transformer, Diffusion–Transformer | [23],[25],[26],[30]-[32],[34],[36],[44]-[54],[59],[65],[71]-[74],[79],[80],[83] |
- Transformer-Based EEG Application
Transformer-based architectures have been extensively embraced and increasingly utilized across a broad spectrum of EEG applications from 2022 to 2024, spanning cognitive, affective, motor, and clinical domains. Their ability to model both spatial and temporal dependencies through self-attention mechanisms has enabled substantial and measurable enhancements in prediction precision, robustness across unseen data, and transparency of model decision-making compared to traditional deep learning methods. As summarized in the reviewed studies, Transformer-based EEG applications can be broadly categorized into five major domains: motor imagery and brain–computer interface (BCI) systems, seizure and neurological disorder detection, emotion and mental state recognition, sleep stage and fatigue monitoring, and cognitive workload or neuropsychological assessment can be seen in Figure 1.
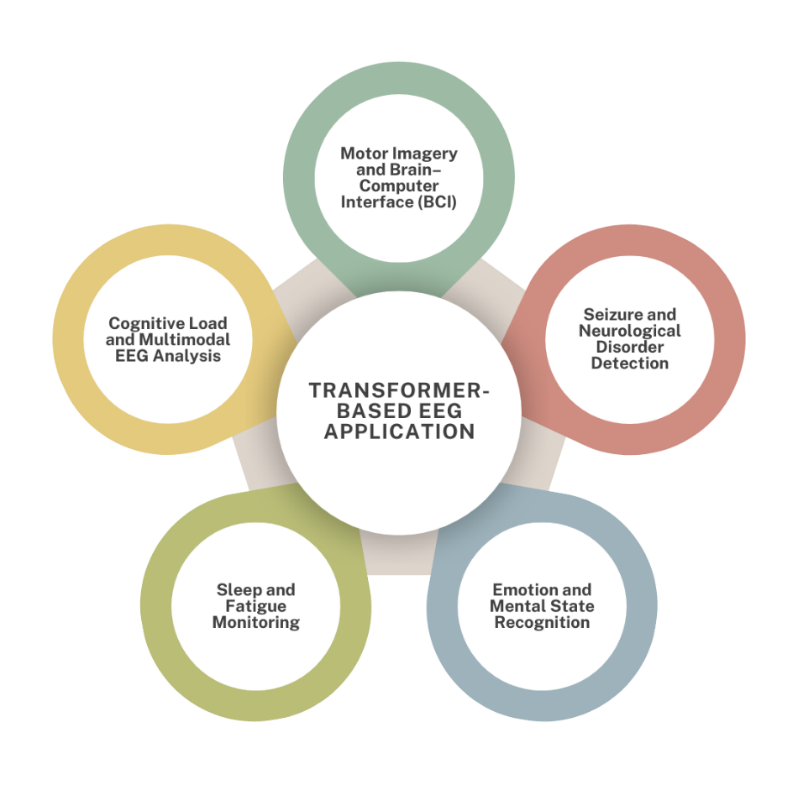
Figure 1. Transformer-based EEG application
A major research focus has been on improving the decoding accuracy and cross-subject generalization of EEG-based BCI systems. Xie et al. [21] pioneered the use of multi-variant Transformer models (s-Trans, t-Trans, s-CTrans, t-CTrans, f-CTrans) for motor imagery classification on the PhysioNet dataset, achieving 83.31% accuracy in two-class tasks. Subsequent works such as Chen et al. [35] and Song et al. [36] introduced CSP + Transformer and EEG Conformer architectures, pushing accuracy to 89.6% and 92.4%, respectively, across BCI Competition IV datasets. Hu et al. [39] and Yeom et al. [79] advanced this line with MSATNet and Query-Only Attention Transformer, which achieved accuracies above 84%, emphasizing the role of attention mechanisms in modeling channel-level interactions and improving transfer learning across sessions. Furthermore, Wang et al. [31] and Ding et al. [65] employed Transformer-based decoders for SSVEP BCI classification, reaching 95.4% and 93.2% accuracy, while Lee et al. [52] demonstrated practical control applications through a DeiT-based calibratable network achieving over 80% accuracy in robotic arm control tasks. These studies highlight the transformative role of attention-driven models in enhancing both precision and adaptability of EEG-based BCIs.
Another dominant application area involves seizure prediction and diagnosis of neurological disorders. Hussein et al. [22] utilized a Multi-Channel ViT for seizure prediction using datasets such as CHB-MIT and AES-Kaggle, achieving an AUC of 0.99 and accuracy of 99.8%. Tian et al. [43] demonstrated near-perfect detection (100% accuracy) using a CNN–Transformer hybrid, while Shi et al. [55] proposed B2-ViT, obtaining an AUC up to 0.923. Holguin-Garcia et al. [83] further achieved 99.76% accuracy in seizure classification using a CNN–Transformer Encoder. Beyond epilepsy, Chen et al. [30] and Khan et al. [49] leveraged Transformer-based frameworks for Alzheimer’s diagnosis, reaching 80.23% and 98% accuracy, respectively, and He et al. [27] applied a Transformer–LSTM–GRN hybrid to predict depth of anesthesia from VitalDB, with RMSE 4.7. These outcomes demonstrate how Transformers can capture complex neural signatures for both acute and chronic neurological monitoring.
Transformers have also excelled in affective and cognitive state decoding due to their capacity to learn long-range dependencies in EEG sequences. Zhou et al. [34] and Lu et al. [41] achieved high-performance emotion recognition using Dual-Channel Transformer and Bi-ViTNet, obtaining 97.3% and 96.25% accuracy, respectively. Subsequent studies, including Chen et al. [67] with DAMGCN (99.42%), Hu et al. [70] with STAFNet (97.9%), and Lu et al. [62] with Convolution Interactive Transformer (98.57%), achieved near-perfect results on SEED and DEAP datasets. These findings underscore the efficacy of attention mechanisms in modeling inter-hemispheric synchronization and affective EEG dynamics. Beyond emotion, Tigga et al. [46] used AttGRUT for depression detection (98.67%), while Wang et al. [51] achieved 93.7% in depression diagnosis using a CNN–Transformer + Diffusion model. Together, these studies affirm that Transformer-based models offer reliable decoding of complex emotional and psychiatric EEG patterns.
Transformer-based architectures have also contributed to advancements in sleep and fatigue-related EEG analysis. Yao et al. [33] introduced VSTTN, integrating Swin and Longformer Transformers for sleep stage classification, achieving 89.24% accuracy, while Zhang et al. [50] and Seraphim et al. [80] reached 88.9% and 89% accuracy using TSEDSleepNet and SPDTransNet, respectively. Oh et al. [48] applied a CNN–Transformer hybrid for sleep onset prediction, reporting a mean absolute error of 9.8 minutes, and Ye et al. [75] used CA-ACGAN for fatigue detection, achieving 90.7% accuracy. These models effectively capture temporal continuity across sleep cycles and microstate transitions, enabling fine-grained monitoring for health and cognitive performance applications.
Transformers have also been employed to assess cognitive workload and integrate multimodal neural data. Li et al. [64] proposed MST-Net for cognitive load classification, achieving 89.1% accuracy, while Peng et al. [63] applied MBMD Transformer for seizure subtype analysis, reaching 93.5% accuracy. Liu et al. [53] explored speech envelope reconstruction using ADT Network, demonstrating moderate correlation scores (~0.168), revealing the potential of Transformers in EEG-based auditory decoding. Moreover, Du et al. [73] and Pradeepkumar et al. [54] incorporated cross-modal EEG–stimuli fusion using MES-CTNet and Cross-Modal Transformer, achieving 98.3% and 84.7% accuracy, respectively. These multimodal approaches indicate the growing role of Transformers in integrating cross-sensory or behavioral information to enrich EEG interpretation.
- EMERGING TRENDS
Between 2022 and 2024, Transformer-based EEG modeling has evolved rapidly, revealing several emerging trends that shape the future of neural signal analysis. One prominent trend is the increasing architectural diversity of Transformer designs tailored for EEG signals. Researchers have transitioned from generic self-attention models toward specialized architectures that integrate spatial, temporal, and frequency-domain information. For example, Xie et al. [21] pioneered multiple Transformer variants (s-Trans, t-Trans, f-CTrans) that separately capture spatial and temporal dependencies, while Wang et al. [28] and Yao et al. [33] extended this idea through multi-graph and hybrid attention mechanisms that encode inter-channel connectivity patterns. The introduction of architectures such as VSTTN (Swin + Longformer) [33], EEG Conformer [36], and MSATNet [39] further highlights the growing emphasis on multi-scale attention fusion, allowing models to simultaneously learn local dynamics and long-range dependencies across EEG channels. This diversification of Transformer backbones signals a maturation of the field, where architectures are increasingly domain-specific rather than adapted directly from computer vision or NLP.
Another significant trend is the emergence of emotion and mental-state decoding as a dominant application area for Transformers in EEG research. Studies such as Zhou et al. [34], Lu et al. [41], and Chen et al. [67] demonstrated that self-attention mechanisms excel in recognizing subtle emotional variations by modeling inter-hemispheric synchrony and temporal correlations, achieving accuracies exceeding 97%. Later models such as STAFNet [70], Convolution Interactive Transformer [62], and MES-CTNet [73] pushed this boundary further, incorporating multimodal signals and cross-session generalization, achieving results up to 99.42% accuracy. This trend reflects a paradigm shift from simple classification tasks to more complex cognitive inference, where Transformers serve as interpretable models capable of decoding human affective and psychological states in near real-time.
The third emerging trend is the integration of multimodal and cross-domain learning within Transformer frameworks. Models such as Cross-Modal Transformer [54] and MES-CTNet [73] fused EEG with complementary data sources (such as physiological or visual stimuli) to enhance contextual understanding. Similarly, Liu et al. [53] utilized Transformers for speech envelope reconstruction, bridging auditory and neural data, while Wang et al. [77] explored multimodal consciousness assessment (MutaPT) with accuracy reaching 85.7%. These multimodal approaches signify a growing interest in leveraging Transformers for neurocognitive data fusion, enabling more holistic interpretations of brain activity that align with real-world sensory integration.
A fourth notable direction involves the trend toward lightweight, efficient, and generalizable Transformers for real-world deployment. Researchers have begun optimizing architectures for wearable EEG systems and clinical applications with limited computational resources. Beiramvand et al. [57] achieved 88% accuracy using a compact Transformer on low-density EEG headsets (Muse, Enobio), while Busia et al. [76] developed EEGformer for wearable seizure detection, maintaining competitive accuracy (73–88%) despite reduced electrode counts. Similarly, Kim et al. [58] proposed Dfformer, a generalized Transformer for multiple EEG decoding tasks, illustrating efforts toward scalability and hardware efficiency. This reflects a broader movement toward real-time EEG analytics, where Transformer models are optimized for embedded or edge devices without sacrificing accuracy. Finally, there is a growing emphasis on explainability and interpretability in Transformer-based EEG modeling. With increasing model complexity, researchers have started integrating attention visualization and explainable AI (XAI) frameworks to interpret the neural features captured by Transformers. For instance, emotion recognition studies such as Lu et al. [62] and Chen et al. [67] incorporated attention map analyses to identify brain regions most influential for classification. This emerging practice enhances transparency and supports clinical adoption, as it aligns with the interpretive demands of medical decision-making.
- RESEARCH GAPS AND FUTURE DIRECTIONS
Despite the impressive progress achieved between 2022 and 2024, Transformer-based EEG modeling still faces several critical challenges that hinder its broader adoption in clinical and real-world applications. One of the foremost gaps lies in the limited generalization and dataset diversity. Many studies, such as those by Xie et al. [21], Chen et al. [35], and Song et al. [36], evaluated their models on benchmark EEG datasets (e.g., PhysioNet, BCI Competition IV), which are relatively small, homogeneous, and collected under controlled laboratory conditions. As a result, models trained on these datasets often fail to generalize across subjects, sessions, or acquisition systems. Only a few works, such as Hussein et al. [22] and Busia et al. [76], attempted cross-dataset validation or wearable EEG integration, yet even these studies lack large-scale, standardized benchmarks that reflect real-world variability. Future research should thus prioritize the creation of multi-center EEG repositories and the adoption of cross-dataset transfer learning frameworks to improve model robustness and reproducibility across diverse recording environments.
Another key limitation is the computational complexity and inefficiency of current Transformer models. While large models such as Multi-Channel ViT [22] and DAMGCN [67] achieved exceptional performance (AUC up to 0.99 and accuracy near 99%), their high parameter count and memory requirements make them impractical for deployment in mobile or clinical devices. This challenge has motivated a recent shift toward lightweight architectures, such as Dfformer [58] and EEGformer [76], but these remain in early development and often sacrifice accuracy for efficiency. Therefore, future efforts should focus on model compression, pruning, and quantization techniques tailored for EEG data, as well as the exploration of efficient Transformer variants (e.g., Performer, Linformer) that preserve performance while reducing resource demand. These strategies are critical to enabling real-time EEG decoding in wearable neurotechnology and point-of-care diagnostic systems.
A further gap involves the lack of interpretability and neurophysiological validation. Although attention mechanisms inherently offer a degree of explainability, most Transformer-based EEG studies still function as black boxes. Few works, such as Lu et al. [62] and Chen et al. [67], visualized attention weights to highlight task-relevant EEG regions, but systematic approaches linking attention maps to neurophysiological phenomena remain rare. Without such interpretability, clinical adoption is limited, as practitioners require transparent insights into how EEG patterns correspond to cognitive or pathological states. Future research should incorporate explainable AI (XAI) frameworks that combine saliency mapping, channel importance ranking, and temporal attribution to ensure that Transformer decisions align with established neuroscientific knowledge. Integrating these methods with clinician-in-the-loop evaluations could bridge the gap between model interpretability and medical usability.
Another major research gap concerns the underexploration of multimodal and cross-domain learning in EEG Transformers. While some studies, such as Du et al. [73] and Pradeepkumar et al. [54], introduced cross-modal architectures by fusing EEG with other physiological or sensory modalities, most models still rely exclusively on EEG data. This limits their capacity to capture the broader neural–behavioral context underlying brain activity. Future directions should emphasize multimodal Transformers that integrate EEG with eye-tracking, facial expression, fNIRS, or physiological signals (e.g., GSR, ECG). Additionally, self-supervised and contrastive learning approaches could be applied to leverage large amounts of unlabeled EEG data, improving model pretraining and transferability across domains. Finally, there remains a pressing need for standardized evaluation frameworks and reproducibility protocols. Current studies use heterogeneous metrics, such as accuracy [21],[36],[70], AUC [22],[28],[55], and F1-score [42],[82], making direct performance comparison challenging. The absence of consistent validation splits, hyperparameter transparency, and open-source codebases further restricts scientific reproducibility. To address these issues, future research should establish benchmarking standards for Transformer-based EEG analysis, similar to those in computer vision and NLP, including shared datasets, unified evaluation pipelines, and public repositories can be seen in Table 3.
Table 3. Research Gaps and Future Directions in Transformer-based EEG Studies
Category | Research Gaps | Future Directions | References |
Limited Cross-Subject Generalization | Many Transformer models show strong within-subject accuracy but poor generalization across subjects due to individual EEG variability. | Develop domain adaptation, subject-invariant embeddings, and federated Transformer training to improve cross-user robustness. | [37],[39],[56],[59],[79] |
Dataset Imbalance & Limited Diversity | Public EEG datasets (e.g., SEED, DEAP, BCI-IV) dominate; lack of large-scale, multimodal, and diverse datasets. | Create benchmark-scale multimodal EEG datasets (EEG+EOG+fNIRS+HRV) and promote open-access repositories. | [33],[34],[47],[50],[78] |
Overfitting on Small Datasets | Transformer-based models require large data; many studies rely on <30 subjects, leading to overfitting. | Employ self-supervised pretraining, contrastive learning, and synthetic EEG augmentation (GANs, diffusion models). | [26],[46],[68],[75],[77] |
Limited Temporal Dynamics Modeling | Some models capture spatial relations well but neglect long-range temporal dependencies in EEG signals. | Integrate hybrid temporal–spatial Transformers (e.g., Swin+Longformer, Temporal Graph Transformers). | [33],[36],[60],[70] |
Lack of Explainability & Interpretability | Most works report accuracy without visual explainability (e.g., attention maps, feature attribution). | Incorporate explainable AI (XAI) frameworks such as attention heatmaps, SHAP/Grad-CAM for clinical interpretability. | [28],[39],[42],[67] |
Low Real-Time Efficiency for BCI Applications | Transformers are computationally expensive, unsuitable for low-latency BCI deployment. | Develop lightweight and hardware-aware models (e.g., EEGformer for MCUs, pruning, quantization, edge inference). | [40],[76],[80] |
Task-Specific Optimization Limitations | Many studies apply generic ViT variants without task-tailored modifications for EEG signal structure. | Design EEG-specific Transformer backbones that integrate neurophysiological priors and frequency-domain features. | [35],[41],[62],[66] |
Lack of Multimodal Integration | Emotion, cognitive load, and fatigue studies often rely on EEG alone. | Fuse multimodal biosignals (EEG, EOG, HRV, facial EMG, text, and audio) using cross-modal or multi-branch Transformers. | [25],[58],[64],[73],[78] |
Inconsistent Evaluation Metrics | Evaluation often limited to accuracy; few report AUC, F1, or Cohen’s Kappa for fair comparison. | Standardize evaluation protocols and adopt balanced metrics for clinical reliability. | [22],[47],[66],[81] |
Lack of Longitudinal & Real-World Validation | Most experiments are lab-based with short sessions; lacking real-world or long-term monitoring validation. | Conduct real-world clinical trials and longitudinal EEG tracking to assess model stability over time. | [40],[56],[77],[82] |
Emotion and Cognitive Task Variability | High performance in SEED/DEAP datasets not always transferable to new emotional paradigms. | Build task-independent emotion models through transfer learning and dynamic adaptation. | [34],[41],[61],[68],[70] |
Limited Integration with Clinical Decision Systems | Few studies link EEG-Transformer outputs to clinical diagnostic workflows or EHR data. | Embed Transformer-based EEG analysis into decision-support systems for neurology and psychiatry. | [30],[44],[63],[81] |
Underexplored Self-Supervised & Generative Approaches | Minimal exploration of Transformers for EEG reconstruction, denoising, or pretraining. | Apply generative Transformers (e.g., MAE, diffusion models) for EEG signal restoration and anomaly detection. | [68],[75],[77],[78] |
Benchmarking Challenges | Different preprocessing, sampling rates, and metrics hinder reproducibility and fair comparison. | Propose unified preprocessing pipelines and cross-dataset benchmarking standards for EEG-Transformer research. | [33],[47],[50],[58] |
Lack of Multiclass Clinical Labeling | Many datasets use binary labels (e.g., seizure/no-seizure), limiting clinical usefulness. | Expand EEG datasets with fine-grained labeling (e.g., seizure types, sleep stages, disease progression). | [28],[63],[66],[80] |
- CONCLUSIONS
This review highlights the rapid evolution and growing impact of Transformer-based architectures in EEG signal analysis from 2022 to 2024. The findings demonstrate that attention-driven models (both pure Transformers and hybrid variants) have achieved remarkable improvements across diverse EEG applications, including motor imagery, seizure detection, emotion recognition, sleep staging, and cognitive load estimation. The ability of Transformers to model global temporal–spatial dependencies has enabled them to outperform traditional deep learning methods while offering new perspectives for feature representation and interpretability. Furthermore, the emergence of domain-specific adaptations such as ViT, Swin Transformer, and EEG Conformer reflects the field’s shift toward architectures tailored to the intrinsic characteristics of EEG data. The integration of attention mechanisms with convolutional, recurrent, and graph-based modules has also proven highly effective in capturing multi-scale dynamics and enhancing robustness across datasets and subjects.
However, despite these advancements, multiple unresolved obstacles continue to remain that restrict real-world implementation and operational adoption of Transformer-based EEG models. Current research remains constrained by small, homogeneous datasets, high computational demands, and limited interpretability, which collectively hinder real-world translation. The lack of unified benchmarking standards and well-established reproducibility protocols further impedes objective performance evaluation and reliable cross-study comparison. Future research should focus on the design and optimization of Transformer architectures that balance computational efficiency with interpretability, leveraging self-supervised and multimodal learning, and establishing open EEG benchmarks that support large-scale, cross-domain training. By addressing these limitations, the next generation of Transformer-based EEG systems can progress from high-performance experimental models toward clinically reliable and scalable neurotechnology capable of transforming brain–computer interaction, cognitive monitoring, and neurological diagnostics.
DECLARATION
Author Contribution
All authors contributed equally to the main contributor to this paper. All authors read and approved the final paper.
Acknowledgement
The authors would like to acknowledge the Department of Medical Technology, Institut Teknologi Sepuluh Nopember, for the facilities and support in this research. The authors also gratefully acknowledge financial support from the Institut Teknologi Sepuluh Nopember for this work, under project scheme of the Publication Writing and IPR Incentive Program (PPHKI) 2025.
Conflicts of Interest
The authors declare no conflict of interest.
REFERENCES
- A. Chaddad, Y. Wu, R. Kateb, and A. Bouridane, “Electroencephalography Signal Processing: A Comprehensive Review and Analysis of Methods and Techniques,” Sensors, vol. 23, no. 14, pp. 6434–6434, 2023, https://doi.org/10.3390/s23146434.
- H. Yadav and S. Maini, “Decoding brain signals: A comprehensive review of EEG-Based BCI paradigms, signal processing and applications,” Computers in Biology and Medicine, vol. 196, p. 110937, 2025, https://doi.org/10.1016/j.compbiomed.2025.110937.
- A. Farizal, A. D. Wibawa, D. P. Wulandari and Y. Pamungkas, "Investigation of Human Brain Waves (EEG) to Recognize Familiar and Unfamiliar Objects Based on Power Spectral Density Features," 2023 International Seminar on Intelligent Technology and Its Applications (ISITIA), pp. 77-82, 2023, https://doi.org/10.1109/ISITIA59021.2023.10221052.
- A. K. Singh and S. Krishnan, “Trends in EEG signal feature extraction applications,” Frontiers in artificial intelligence, vol. 5, 2023, https://doi.org/10.3389/frai.2022.1072801.
- A. D. Wibawa, N. Fatih, Y. Pamungkas, M. Pratiwi, P. A. Ramadhani, and Suwadi, “Time and Frequency Domain Feature Selection Using Mutual Information for EEG-based Emotion Recognition,” 2022 9th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI). pp. 19–24, 2022, https://doi.org/10.23919/eecsi56542.2022.9946522.
- M. H. Al-Adhaileh, S. Ahmad, A. A. Alharbi, M. Alarfaj, M. Dhopeshwarkar, and T. H. H. Aldhyani, “Diagnosis of epileptic seizure neurological condition using EEG signal: a multi-model algorithm,” Frontiers in Medicine, vol. 12, 2025, https://doi.org/10.3389/fmed.2025.1577474.
- Y. Pamungkas, A. D. Wibawa and M. H. Purnomo, "EEG Data Analytics to Distinguish Happy and Sad Emotions Based on Statistical Features," 2021 4th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), pp. 345-350, 2021, https://doi.org/10.1109/ISRITI54043.2021.9702766.
- Y. Wei, Y. Wang, and J. Watada, “A Modular Perspective on the Evolution of Deep Learning: Paradigm Shifts and Contributions to AI,” Applied Sciences, vol. 15, no. 19, p. 10539, 2025, https://doi.org/10.3390/app151910539.
- T. Shawly and A. A. Alsheikhy, “A Neural ODE-Enhanced Deep Learning Framework for Accurate and Real-Time Epilepsy Detection,” Computer Modeling in Engineering & Sciences, vol. 143, no. 3, pp. 3033–3064, 2025, https://doi.org/10.32604/cmes.2025.065264.
- S. Mahmoud, B. C. Kara, C. Eyupoglu, C. Uzay, M. S. Tosun, and O. Karakuş, “A Survey of Large Language Models: Evolution, Architectures, Adaptation, Benchmarking, Applications, Challenges, and Societal Implications,” Electronics, vol. 14, no. 18, pp. 3580–3580, 2025, https://doi.org/10.3390/electronics14183580.
- S. R. Choi and M. Lee, “Transformer Architecture and Attention Mechanisms in Genome Data Analysis: A Comprehensive Review,” Biology, vol. 12, no. 7, p. 1033, 2023, https://doi.org/10.3390/biology12071033.
- M. A. Pfeffer, S. Sai, and J. Kwok, “Exploring the frontier: Transformer-based models in EEG signal analysis for brain-computer interfaces,” Computers in Biology and Medicine, vol. 178, pp. 108705–108705, 2024, https://doi.org/10.1016/j.compbiomed.2024.108705.
- E. Vafaei and M. Hosseini, “Transformers in EEG Analysis: A Review of Architectures and Applications in Motor Imagery, Seizure, and Emotion Classification,” Sensors, vol. 25, no. 5, p. 1293, 2025, https://doi.org/10.3390/s25051293.
- N. Esmi, A. Shahbahrami, G. Gaydadjiev, and P. de Jonge, “TEREE: Transformer-based emotion recognition using EEG and Eye movement data,” Intelligence-Based Medicine, vol. 12, p. 100305, 2025, https://doi.org/10.1016/j.ibmed.2025.100305.
- K. Zhao and X. Guo, “PilotCareTrans Net: an EEG data-driven transformer for pilot health monitoring,” Frontiers in Human Neuroscience, vol. 19, 2025, https://doi.org/10.3389/fnhum.2025.1503228.
- E. Aanestad, S. Beniczky, H. Olberg, and J. Brogger, “Unveiling variability: A systematic review of reproducibility in visual EEG analysis, with focus on seizures,” Epileptic Disorders, 2024, https://doi.org/10.1002/epd2.20291.
- S. Wong, A. Simmons, J. R.‐Villicana, S. Barnett, S. Sivathamboo, P. Perucca, Z. Ge, P. Kwan, L. Kuhlmann, R. Vasa, K. Mouzakis, and T. J O'Brien, “EEG datasets for seizure detection and prediction - A review,” Epilepsia Open, 2023, https://doi.org/10.1002/epi4.12704.
- Y. Pamungkas, S. Pratasik, M. Krisnanda, and P. N. Crisnapati, “Optimizing Gated Recurrent Unit Architecture for Enhanced EEG-Based Emotion Classification”, J Robot Control (JRC), vol. 6, no. 3, pp. 1450–1461, 2025, https://doi.org/10.18196/jrc.v6i3.26016.
- B. R. Rai, B. K. Rai, A. S. Mamatha, and Nikshitha, “An Analytical Framework for Enhancing Brain Signal Classification through Hybrid Filtering and Dimensionality Reduction,” Healthcare Analytics, p. 100435, 2025, https://doi.org/10.1016/j.health.2025.100435.
- E. Vafaei and M. Hosseini, “Transformers in EEG Analysis: A Review of Architectures and Applications in Motor Imagery, Seizure, and Emotion Classification,” Sensors, vol. 25, no. 5, p. 1293, 2025, https://doi.org/10.3390/s25051293.
- J. Xie, J. Zhang, J. Sun, Z. Ma, L. Qin, G. Li, H. Zhou, and Y. Zhan, “A Transformer-Based Approach Combining Deep Learning Network and Spatial-Temporal Information for Raw EEG Classification,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 30, pp. 2126–2136, 2022, https://doi.org/10.1109/tnsre.2022.3194600.
- R. Hussein, S. Lee, and R. K. Ward, “Multi-Channel Vision Transformer for Epileptic Seizure Prediction,” Biomedicines, vol. 10, no. 7, pp. 1551–1551, 2022, https://doi.org/10.3390/biomedicines10071551.
- S. Liu, A. M.-Ragolta, T. Yan, K. Qian, E. P.-Cabaleiro, B. Hu, and B. W. Schuller, “Capturing Time Dynamics From Speech Using Neural Networks for Surgical Mask Detection,” IEEE Journal of Biomedical and Health Informatics, vol. 26, no. 8, pp. 4291–4302, 2022, https://doi.org/10.1109/jbhi.2022.3173128.
- Z. R. Murphy, K. Venkatesh, J. Sulam, and P. H. Yi, “Visual Transformers and Convolutional Neural Networks for Disease Classification on Radiographs: A Comparison of Performance, Sample Efficiency, and Hidden Stratification,” Radiology: Artificial Intelligence, vol. 4, no. 6, 2022, https://doi.org/10.1148/ryai.220012.
- J. Wang, Y. Xu, J. Tian, H. Li, W. Jiao, Y. Sun, and G. Li, “Driving Fatigue Detection with Three Non-Hair-Bearing EEG Channels and Modified Transformer Model,” vol. 24, no. 12, pp. 1715–1715, 2022, https://doi.org/10.3390/e24121715.
- X. Xu, Y. Zhao, R. Zhang, and T. Xu, “Research on Stress Reduction Model Based on Transformer,” KSII Transactions on Internet and Information Systems, vol. 16, no. 12, 2022, https://doi.org/10.3837/tiis.2022.12.009.
- Y. He, S. Peng, M. Chen, Z. Yang, and Y. Chen, “A Transformer-Based Prediction Method for Depth of Anesthesia During Target-Controlled Infusion of Propofol and Remifentanil,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 3363–3374, 2023, https://doi.org/10.1109/tnsre.2023.3305363.
- Y. Wang, W. Cui, T. Yu, X. Li, X. Liao, and Y. Li, “Dynamic Multi-Graph Convolution-Based Channel-Weighted Transformer Feature Fusion Network for Epileptic Seizure Prediction,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 4266–4277, 2023, https://doi.org/10.1109/tnsre.2023.3321414.
- Y. Ma, Y. Tang, Y. Zeng, T. Ding, and Y. Liu, “An N400 identification method based on the combination of Soft-DTW and transformer,” Frontiers in computational neuroscience, vol. 17, 2023, https://doi.org/10.3389/fncom.2023.1120566.
- Y. Chen, H. Wang, D. Zhang, L. Zhang, and L. Tao, “Multi-feature fusion learning for Alzheimer’s disease prediction using EEG signals in resting state,” ProQuest, vol. 17, p. 1272834, 2023, https://doi.org/10.3389/fnins.2023.1272834.
- X. Wang, A. Liu, L. Wu, L. Guan, and X. Chen, “Improving Generalized Zero-Shot Learning SSVEP Classification Performance From Data-Efficient Perspective,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 4135–4145, 2023, https://doi.org/10.1109/tnsre.2023.3324148.
- R. Dang, T. Yu, B. Hu, Y. Wang, Z. Pan, R. Luo, and Q. Wang, “Temporal transformer-spatial graph convolutional network: an intelligent classification model for anti N-methyl-D-aspartate receptor encephalitis based on electroencephalogram signal,” Frontiers in Neuroscience, vol. 17, 2023, https://doi.org/10.3389/fnins.2023.1223077.
- H. Yao, T. Liu, R. Zou, S. Ding, and Y. Xu, “A Spatial-Temporal Transformer Architecture Using Multi-Channel Signals for Sleep Stage Classification,” IEEE transactions on neural systems and rehabilitation engineering, vol. 31, pp. 3353–3362, 2023, https://doi.org/10.1109/tnsre.2023.3305201.
- Y. Zhou and J. Lian, “Identification of emotions evoked by music via spatial-temporal transformer in multi-channel EEG signals,” Frontiers in Neuroscience, vol. 17, p. 1188696, 2023, https://doi.org/10.3389/fnins.2023.1188696.
- X. Chen, J. An, H. Wu, S. Li, B. Liu, and D. Wu, “Front-End Replication Dynamic Window (FRDW) for Online Motor Imagery Classification,” IEEE transactions on neural systems and rehabilitation engineering, vol. 31, pp. 3906–3914, 2023, https://doi.org/10.1109/tnsre.2023.3321640.
- Y. Song, Q. Zheng, B. Liu, and X. Gao, “EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 710–719, 2023, https://doi.org/10.1109/tnsre.2022.3230250.
- Y. Song, Q. Zheng, Q. Wang, X. Gao, and P. Heng, “Global Adaptive Transformer for Cross-Subject Enhanced EEG Classification,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 2767–2777, 2023, https://doi.org/10.1109/tnsre.2023.3285309.
- J. Zhang, K. Li, B. Yang, and X. Han, “Local and global convolutional transformer-based motor imagery EEG classification,” Frontiers in neuroscience, vol. 17, p. 1219988, 2023, https://doi.org/10.3389/fnins.2023.1219988.
- L. Hu, W. Hong, and L. Liu, “MSATNet: multi-scale adaptive transformer network for motor imagery classification,” Frontiers in neuroscience, vol. 17, p. 1173778, 2023, https://doi.org/10.3389/fnins.2023.1173778.
- H. Wang, L. Cao, C. Huang, J. Jia, Y. Dong, C. Fan, and V. H. C. de Albuquerque, “A Novel Algorithmic Structure of EEG Channel Attention Combined With Swin Transformer for Motor Patterns Classification,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 31, pp. 3132–3141, 2023, https://doi.org/10.1109/tnsre.2023.3297654.
- W. Lu, T.-P. Tan, and H. Ma, “Bi-branch Vision Transformer Network for EEG Emotion Recognition,” IEEE Access, vol. 11, pp. 36233-36243, 2023, https://doi.org/10.1109/access.2023.3266117.
- X. Zhao, N. Yoshida, T. Ueda, H. Sugano, and T. Tanaka, “Epileptic seizure detection by using interpretable machine learning models,” Journal of Neural Engineering, vol. 20, no. 1, pp. 015002–015002, 2023, https://doi.org/10.1088/1741-2552/acb089.
- Z. Tian, B. Hu, Y. Si, and Q. Wang, “Automatic Seizure Detection and Prediction Based on Brain Connectivity Features and a CNNs Meet Transformers Classifier,” Brain sciences, vol. 13, no. 5, pp. 820–820, 2023, https://doi.org/10.3390/brainsci13050820.
- O. S. Lih, V. Jahmunah, E. E. Palmer, P. D. Barua, S. Dogan, T. Tuncer, S. García, F. Molinari and, U. R. Acharya, “EpilepsyNet: Novel automated detection of epilepsy using transformer model with EEG signals from 121 patient population,” Computers in Biology and Medicine, vol. 164, pp. 107312–107312, 2023, https://doi.org/10.1016/j.compbiomed.2023.107312.
- Z. Jin, Z. Xing, Y. Wang, S. Fang, X. Gao, and X. Dong, “Research on Emotion Recognition Method of Cerebral Blood Oxygen Signal Based on CNN-Transformer Network,” Sensors, vol. 23, no. 20, p. 8643, 2023, https://doi.org/10.3390/s23208643.
- N. P. Tigga and S. Garg, “Efficacy of novel attention-based gated recurrent units transformer for depression detection using electroencephalogram signals,” Health Information Science and Systems, vol. 11, no. 1, 2022, https://doi.org/10.1007/s13755-022-00205-8.
- N. Gour, T. Hassan, M. Owais, I. I. Ganapathi, P. Khanna, M. L. Seghier, and N. Werghi, “Transformers for autonomous recognition of psychiatric dysfunction via raw and imbalanced EEG signals,” Brain Informatics, vol. 10, no. 1, 2023, https://doi.org/10.1186/s40708-023-00201-y.
- S. Oh, Y.-S. Kweon, G.-H. Shin, and S.-W. Lee, “Association Between Sleep Quality and Deep Learning-Based Sleep Onset Latency Distribution Using an Electroencephalogram,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 1806–1816, 2024, https://doi.org/10.1109/tnsre.2024.3396169.
- A. A. Khan, R. K. Mahendran, K. Perumal, and M. Faheem, “Dual-3DM3-AD: Mixed Transformer based Semantic Segmentation and Triplet Pre-processing for Early Multi-Class Alzheimer’s Diagnosis,” IEEE transactions on neural systems and rehabilitation engineering, vol. 32, pp. 696-707, 2024, https://doi.org/10.1109/tnsre.2024.3357723.
- Z. Zhang, B.-S. Lin, C.-W. Peng, and B.-S. Lin, “Multi-Modal Sleep Stage Classification With Two-Stream Encoder-Decoder,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 2096–2105, 2024, https://doi.org/10.1109/tnsre.2024.3394738.
- Y. Wang, S. Zhao, H. Jiang, S. Li, B. Luo, T. Li, and G. Pan, “DiffMDD: A Diffusion-Based Deep Learning Framework for MDD Diagnosis Using EEG,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 728–738, 2024, https://doi.org/10.1109/tnsre.2024.3360465.
- B.-H. Lee, J.-H. Cho, B.-H. Kwon, M. Lee, and S.-W. Lee, “Iteratively Calibratable Network for Reliable EEG-Based Robotic Arm Control,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 2793–2804, 2024, https://doi.org/10.1109/tnsre.2024.3434983.
- R. Liu, C. Liu, D. Cui, H. Zhang, X. Xu, Y. Duan, Y. Chao, X. Sha, L. Sun, X. Ma, S. Li, and S. Chang, “ADT Network: A Novel Nonlinear Method for Decoding Speech Envelopes From EEG Signals,” Trends in Hearing, vol. 28, p. 23312165241282872-23312165241282872, 2024, https://doi.org/10.1177/23312165241282872.
- J. Pradeepkumar, M. Anandakumar, V. Kugathasan, D. Suntharalingham, S. L. Kappel, A. C. De Silva, and C. U. S. Edussooriya, “Toward Interpretable Sleep Stage Classification Using Cross-Modal Transformers,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 2893–2904, 2024, https://doi.org/10.1109/tnsre.2024.3438610.
- S. Shi and W. Liu, “B2-ViT Net: Broad Vision Transformer Network with Broad Attention for Seizure Prediction,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 178-188, 2024, https://doi.org/10.1109/tnsre.2023.3346955.
- M. Liu, Y. Liu, W. Shi, Y. Lou, Y. Sun, Q. Meng, D. Wang, F. Xu, Y. Zhang, L. Zhang, and J. Leng, “EMPT: a sparsity Transformer for EEG-based motor imagery recognition,” Frontiers in neuroscience, vol. 18, 2024, https://doi.org/10.3389/fnins.2024.1366294.
- M. Beiramvand, M. Shahbakhti, N. Karttunen, R. Koivula, J. Turunen, and T. Lipping, “Assessment of Mental Workload Using a Transformer Network and Two Prefrontal EEG Channels: An Unparameterized Approach,” IEEE Transactions on Instrumentation and Measurement, vol. 73, pp. 1–10, 2024, https://doi.org/10.1109/tim.2024.3395312.
- S.-J. Kim, D.-H. Lee, H.-G. Kwak, and S.-W. Lee, “Towards Domain-free Transformer for Generalized EEG Pre-training,” IEEE transactions on neural systems and rehabilitation engineering, vol. 32, pp. 482–492, 2024, https://doi.org/10.1109/tnsre.2024.3355434.
- G. Ren, A. Kumar, S. S. Mahmoud, and Q. Fang, “A deep neural network and transfer learning combined method for cross-task classification of error-related potentials,” Frontiers in Human Neuroscience, vol. 18, pp. 1394107–1394107, 2024, https://doi.org/10.3389/fnhum.2024.1394107.
- W. Chen, Y. Luo, and J. Wang, “Three-Branch Temporal-Spatial Convolutional Transformer for Motor Imagery EEG Classification,” IEEE Access, vol. 12, pp. 79754–79764, 2024, https://doi.org/10.1109/access.2024.3405652.
- S. Ke, C. Ma, W. Li, J. Lv, and L. Zou, “Multi-Region and Multi-Band Electroencephalogram Emotion Recognition Based on Self-Attention and Capsule Network,” Applied Sciences, vol. 14, no. 2, pp. 702–702, 2024, https://doi.org/10.3390/app14020702.
- W. Lu, L. Xia, T. P. Tan, and H. Ma, “CIT-EmotionNet: convolution interactive transformer network for EEG emotion recognition,” PeerJ Computer Science, vol. 10, pp. e2610–e2610, 2024, https://doi.org/10.7717/peerj-cs.2610.
- R. Peng, Z. Du, C. Zhao, J. Luo, W. Liu, X. Chen, and D. Wu, “Multi-Branch Mutual-Distillation Transformer for EEG-Based Seizure Subtype Classification,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 831–839, 2024, https://doi.org/10.1109/tnsre.2024.3365713.
- Z. Li, R. Zhang, Y. Zeng, L. Tong, R. Lu, and B. Yan, “MST-net: A multi-scale swin transformer network for EEG-based cognitive load assessment,” Brain Research Bulletin, vol. 206, p. 110834, 2024, https://doi.org/10.1016/j.brainresbull.2023.110834.
- W. Ding, A. Liu, L. Guan, and X. Chen, “A Novel Data Augmentation Approach Using Mask Encoding for Deep Learning-Based Asynchronous SSVEP-BCI,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 875–886, 2024, https://doi.org/10.1109/tnsre.2024.3366930.
- Y. Qin, W. Zhang, and X. Tao, “TBEEG: A Two-Branch Manifold Domain Enhanced Transformer Algorithm for Learning EEG Decoding,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 1445–1455, 2024, https://doi.org/10.1109/tnsre.2024.3380595.
- W. Chen, Y. Liao, R. Dai, Y. Dong, and L. Huang, “EEG-based emotion recognition using graph convolutional neural network with dual attention mechanism,” Frontiers in Computational Neuroscience, vol. 18, p. 1416494, 2024, https://doi.org/10.3389/fncom.2024.1416494.
- M. Pang, H. Wang, J. Huang, C.-M. Vong, Z. Zeng, and C. Chen, “Multi-Scale Masked Autoencoders for Cross-Session Emotion Recognition,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 1637–1646, 2024, https://doi.org/10.1109/tnsre.2024.3389037.
- J. Luo, W. Cui, S. Xu, L. Wang, H. Chen, and Y. Li, “A Cross-Scale Transformer and Triple-View Attention Based Domain-Rectified Transfer Learning for EEG Classification in RSVP Tasks,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 32, pp. 672–683, 2024, https://doi.org/10.1109/tnsre.2024.3359191.
- F. Hu, K. He, M. Qian, X. Liu, Z. Qiao, L. Zhang, and J. Xiong, “STAFNet: an adaptive multi-feature learning network via spatiotemporal fusion for EEG-based emotion recognition,” Frontiers in Neuroscience, vol. 18, p. 1519970, 2024, https://doi.org/10.3389/fnins.2024.1519970.
- J. Lee and J.-H. Han, “Bimodal Transformer with Regional EEG Data for Accurate Gameplay Regularity Classification,” Brain Sciences, vol. 14, no. 3, p. 282, 2024, https://doi.org/10.3390/brainsci14030282.
- X. Yao, T. Li, P. Ding, F. Wang, L. Zhao, A. Gong, W. Nan, and Y. Fu, “Emotion classification based on transformer and CNN for EEG spatial-temporal feature learning”, Brain Sci., vol. 14, no. 3, p. 268, 2024, https://doi.org/10.3390/brainsci14030268.
- Y. Du, H. Ding, M. Wu, F. Chen, and Z. Cai, “MES-CTNet: A Novel Capsule Transformer Network Base on a Multi-Domain Feature Map for Electroencephalogram-Based Emotion Recognition,” Brain Sciences, vol. 14, no. 4, p. 344, 2024, https://doi.org/10.3390/brainsci14040344.
- X. Li, T. Haba, G. Cui, F. Kinoshita, and H. Touyama, “The classification of SSVEP-BCI based on ear-EEG via RandOm Convolutional KErnel Transform with Morlet wavelet,” Discover Applied Sciences, vol. 6, no. 4, 2024, https://doi.org/10.1007/s42452-024-05816-2.
- H. Ye, M. Chen, and G. Feng, “Research on Fatigue Driving Detection Technology Based on CA-ACGAN,” Brain Sciences, vol. 14, no. 5, p. 436, 2024, https://doi.org/10.3390/brainsci14050436.
- P. Busia, A. Cossettini, T. M. Ingolfsson, S. Benatti, A. Burrello, V. J. B. Jung, M. Scherer, M. A. Scrugli, A. Bernini, P. Ducouret, P. Ryvlin, P. Meloni, and L. Benini, “Reducing False Alarms in Wearable Seizure Detection with EEGformer: A Compact Transformer Model for MCUs,” IEEE transactions on biomedical circuits and systems, pp. 1–13, 2024, https://doi.org/10.1109/tbcas.2024.3357509.
- Z. Wang, J. Yu, J. Gao, Y. Bai, and Z. Wan, “MutaPT: A Multi-Task Pre-Trained Transformer for Classifying State of Disorders of Consciousness Using EEG Signal,” Brain Sciences, vol. 14, no. 7, pp. 688–688, 2024, https://doi.org/10.3390/brainsci14070688.
- G. Feng, H. Wang, M. Wang, X. Zheng, and R. Zhang, “A Research on Emotion Recognition of the Elderly Based on Transformer and Physiological Signals,” Electronics, vol. 13, no. 15, pp. 3019–3019, 2024, https://doi.org/10.3390/electronics13153019.
- H. Yeom and K. An, “A Simplified Query-Only Attention for Encoder-Based Transformer Models,” Applied Sciences, vol. 14, no. 19, p. 8646, 2024, https://doi.org/10.3390/app14198646.
- M. Seraphim, A. Lechervy, F. Yger, L. Brun, and O. Etard, “Automatic Classification of Sleep Stages from EEG Signals Using Riemannian Metrics and Transformer Networks,” SN Computer Science, vol. 5, no. 7, 2024, https://doi.org/10.1007/s42979-024-03310-5.
- S. Basheer, G. Aldehim, A. S. Alluhaidan, and S. Sakri, “Improving mental dysfunction detection from EEG signals: Self-contrastive learning and multitask learning with transformers,” Alexandria Engineering Journal, vol. 106, pp. 52–59, 2024, https://doi.org/10.1016/j.aej.2024.06.058.
- D.-H. Shih, F.-I. Chung, T.-W. Wu, S.-Y. Huang, and M.-H. Shih, “Advanced Trans-EEGNet Deep Learning Model for Hypoxic-Ischemic Encephalopathy Severity Grading,” Mathematics, vol. 12, no. 24, p. 3915, 2024, https://doi.org/10.3390/math12243915.
- S. A. Holguin‑Garcia, E. Guevara‑Navarro, A. E. Daza‑Chica, M. A. Patiño‑Claro, H. B. Arteaga‑Arteaga, G. A. Ruz, R. Tabares‑Soto, and M. A. Bravo‑Ortiz, “A comparative study of CNN-capsule-net, CNN-transformer encoder, and Traditional machine learning algorithms to classify epileptic seizure,” BMC Medical Informatics and Decision Making, vol. 24, no. 1, 2024, https://doi.org/10.1186/s12911-024-02460-z.
Yuri Pamungkas (Trends and Gaps in Transformer-Based EEG Modeling: A Review of Recent Developments)