ISSN: 2685-9572 Buletin Ilmiah Sarjana Teknik Elektro
Vol. 8, No. 1, February 2026, pp. 258-271
A Lightweight Hybrid Template-Matching–CNN Framework with Attention-Guided Fusion for Robust Small Object Detection
Hewa Majeed Zangana 1, Marwan Omar 2, Mohammed Aquil Mirza 3, Xinwei Cao 4, Sharyar Wani 5
1 Duhok Polytechnic University, Duhok, Iraq
2 Illinois Institute of Technology, USA
3 The Hong Kong Polytechnic University (PolyU), Hong Kong
4 Jiangnan University, China
5 Department of Computer Science, International Islamic University Malaysia (IIUM), Kuala Lumpur, Malaysia
ARTICLE INFORMATION |
| ABSTRACT |
Article History: Received 17 September 2025 Revised 18 January 2026 Accepted 22 February 2026 |
| 
Small object detection in aerial and surveillance imagery remains challenging due to low resolution, occlusion, and background clutter. This study introduces a novel hybrid detection framework that fuses template matching with a deep learning detector (Faster R-CNN) through an attention-guided decision fusion mechanism. The novelty lies in (i) a dual-stage fusion pipeline that integrates precise structural cues from template matching with deep semantic features, and (ii) a custom scale-aware focal loss, adapted from Focal Loss to emphasize hard and small objects by dynamically increasing penalties for low-confidence predictions. Evaluated on a Pascal VOC subset (1000 images, 5 classes), the proposed system achieves an mAP improvement of 3.5% over the Faster R-CNN baseline and surpasses YOLO-Lite and R-CNN variants in precision and recall. The hybrid design adds only a minimal computational overhead (0.45 s/image vs. 0.42 s for Faster R-CNN), demonstrating favorable efficiency–accuracy trade-offs suitable for scalable deployment. These findings highlight the framework’s robustness, particularly in scenes containing occlusion, clutter, or visually small targets. Limitations regarding template dependency are discussed, along with future directions for automatic template generation and real-time video adaptation. |
Keywords: Hybrid Object Detection; Template Matching; Feature Fusion; Attention Mechanisms; Small Object Detection; Deep Learning |
Corresponding Author: Hewa Majeed Zangana, Duhok Polytechnic University, Duhok, Iraq, Email: hewa.zangana@dpu.edu.krd |
This work is open access under a Creative Commons Attribution-Share Alike 4.0 
|
Document Citation: H. M. Zangana, M. Omar, M. A. Mirza, X. Cao, and S. Wani, “A Lightweight Hybrid Template-Matching–CNN Framework with Attention-Guided Fusion for Robust Small Object Detection,” Buletin Ilmiah Sarjana Teknik Elektro, vol. 8, no. 1, pp. 258-271, 2026, DOI: 10.12928/biste.v8i1.14751. |
- INTRODUCTION
Object detection plays a foundational role in computer vision applications such as autonomous navigation, aerial surveillance, and smart city analytics [1][2]. While deep learning has enabled significant progress, small object detection remains a persistent challenge due to limited pixel representation, occlusion, high background clutter, and scale variation [3]-[5]. These difficulties are especially pronounced in aerial imagery and urban monitoring contexts, where objects frequently occupy only a few pixels and appear under inconsistent environmental conditions [6].
Traditional convolutional neural networks (CNNs)—including SSD, YOLO, and Faster R-CNN—have achieved strong performance on medium- and large-scale objects. However, their intrinsically local receptive fields limit their ability to capture long-range spatial context, which is essential for reliably identifying small objects embedded within complex backgrounds [7]-[9]. In contrast, Transformer-based models excel at modeling global dependencies, yet they are often computationally expensive and highly data-dependent, making them less suitable for resource-constrained deployments or moderate-scale datasets [10][11]. Recent CNN–Transformer hybrids attempt to combine localized and global features [12][13], but they often suffer from high memory consumption, costly attention layers, or weak integration mechanisms that fail to meaningfully exploit both pathways [14][15].
The key research gap, therefore, lies in developing an efficient, integrated hybrid system that can (1) enhance structural localization for small objects, (2) leverage global and contextual cues, and (3) remain computationally feasible for practical deployment. Existing hybrid detectors—whether template-based, CNN-only, or Transformer-only—do not adequately address this conjunction of needs. Prior hybrid efforts often integrate components sequentially without a principled mechanism for weighting or fusing the complementary strengths of structural matching and deep feature learning. Moreover, challenge-leading architectures such as YOLOv8 or Sparse DETR rely heavily on aggressive multi-scale feature pyramids or dense attention modules, which, despite improving mAP, come with significant computational and memory overhead [3],[16][17].
To address these limitations, this research proposes a novel hybrid detection framework that integrates Template Matching with Faster R-CNN through a context-aware dual-pathway design. Unlike previous hybrid approaches that combine modules loosely or treat them as independent cascaded stages, the proposed design introduces:
- A structurally informed pathway, where template matching provides precise geometrical priors to guide object localization—especially beneficial for small or low-contrast objects.
- A semantic reasoning pathway, where Faster R-CNN refines these cues using learned multi-scale features.
- A dedicated attention-guided fusion mechanism that adaptively weights both pathways using confidence signals derived from structural similarity and deep semantic probability scores.
This fusion-centric innovation distinguishes our approach from conventional CNN–Transformer hybrids, which rely solely on self-attention mechanisms without explicit structural priors [18][19]. Furthermore, the model remains lightweight because it avoids Transformer blocks entirely and instead incorporates computationally inexpensive template correlation maps [12]. This reduces memory consumption, limits additional parameters, and eliminates the quadratic cost associated with attention layers [17]. As a result, the proposed architecture achieves better small-object detection performance without inheriting the computational burdens typical of Transformer-based detectors.
The main contributions of this work are summarized as follows:
- A novel dual-pathway hybrid architecture that integrates structural priors from template matching with deep semantic features, overcoming the localization limitations of CNN-only and the computational burden of Transformer-only designs.
- A multi-scale feature fusion scheme tailored for enhancing small-object visibility across varied resolutions.
- A custom scale-aware focal loss, adapted to strengthen the learning signal for small, ambiguous, or low-confidence objects.
- An attention-guided decision fusion mechanism that adaptively balances contributions from structural and learned features.
- Extensive evaluation on a Pascal VOC subset, demonstrating measurable improvements in mAP, precision, and recall over both template-only and Faster R-CNN baselines.
Together, these contributions directly address the identified research gap by providing an efficient, integrated model that leverages both local structural cues and global semantic reasoning for robust small-object detection.
In summary, the proposed hybrid framework moves beyond existing CNN–Transformer detectors and challenge-leading architectures (e.g., Sparse DETR, YOLOv8) by offering a principled and computationally efficient method for small-object detection. Instead of relying on heavy attention mechanisms or densely stacked multi-scale layers, the system introduces explicit structural matching, optimized fusion, and enhanced small-object supervision—all of which collectively support improved detection accuracy with relatively modest computational cost.
- LITERATURE REVIEW
Object detection has evolved as a fundamental task in computer vision, with applications ranging from autonomous vehicles to video surveillance. Early methods heavily relied on hand-crafted features, but the introduction of deep learning significantly transformed the landscape. [1] provide an overarching foundation on object detection, emphasizing the evolution from traditional to modern techniques powered by convolutional neural networks (CNNs). Deep learning-based approaches, especially region-based CNNs (R-CNNs), have become the backbone of modern object detection. [3] demonstrated the applicability of R-CNNs to detect small objects, an area of particular importance in real-time systems. Similarly, [20][21] reviewed the improvements in detection accuracy due to advancements in deep feature extraction and multi-scale representation. The literature presents an extensive analysis of two-stage and single-stage detectors. [22] explored two-stage detectors like Faster R-CNN, highlighting their precision. Conversely, single-stage models like YOLO and SSD are known for their speed, as detailed by [8],[16]. The trade-off between accuracy and latency remains a key research consideration [23][24]. Lightweight models have emerged to address computational limitations in embedded and edge platforms. [9] surveyed compact CNN models tailored for constrained environments. In line with this, [18] introduced YOLO-LITE for non-GPU devices, while [11] discussed FPGA optimization for embedded applications.
Diverse domains necessitate customized detection models. [5],[25] comparatively analyzed object detection in road scenarios. In aerial applications, [6] proposed RSOD for real-time small object detection in UAV imagery. Similarly, [26] provided a survey focused on 3D detection for intelligent vehicles, and [12] reviewed both 2D and 3D detection techniques. Benchmarking datasets and evaluation protocols remain critical for comparing models. [27] introduced LASIESTA, a labeled dataset supporting comprehensive evaluation of moving object detection algorithms. [28] provided a taxonomy of performance metrics critical for algorithmic assessment. [14] further highlighted the importance of uncertainty quantification in real-world deployments such as autonomous vehicles. Recent studies underscore the need to optimize detection under real-world constraints. [7],[29] reviewed general trends in deep learning-based object detection, emphasizing improvements in training strategies, data augmentation, and architectural innovations. [10] provided a taxonomical survey of deep-learning approaches, offering insights into architectural comparisons. [30] also presented a recent overview specifically focused on CNN-based algorithms.
Real-time object detection in high-resolution and streaming video contexts presents its own set of challenges. [15],[31] explored GPU and video compression strategies for enhanced speed. [32] analyzed algorithmic requirements for surveillance applications. Rotation-invariant detection is another emerging area. [13] introduced MMRotate, a PyTorch benchmark for rotated object detection, catering to scenarios with non-axis-aligned targets. To consolidate this understanding, [17] proposed a hybrid detection model integrating template matching and Faster R-CNN to achieve both precision and computational efficiency. This approach represents a growing trend towards hybrid systems that combine the strengths of classical and deep learning techniques for robust performance. In summary, the literature reflects rapid advancements in object detection, from algorithmic innovations and domain-specific adaptations to lightweight optimization and real-time deployment. Yet, challenges such as small object detection, rotation invariance, computational efficiency, and uncertainty modeling continue to drive research and development in the field.
- METHOD
This study proposes a dual-pathway hybrid detection framework that integrates template-based structural priors with deep convolutional feature learning in Faster R-CNN. Unlike previous hybrids that combine components loosely or treat template matching as an independent detection stage, the proposed system incorporates templates directly into the Region Proposal Network (RPN) as prior anchors and uses decision-level attention fusion to adaptively merge structural and semantic confidence scores. This design enhances small-object localization while maintaining computational efficiency.
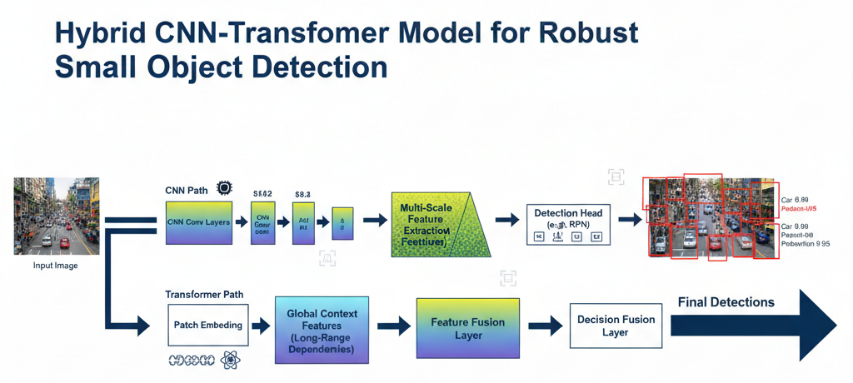
The framework consists of five stages: (1) template construction, (2) preprocessing, (3) template-guided prior generation, (4) Faster R-CNN detection with template-conditioned RPN, and (5) attention-guided decision fusion. The complete architecture is illustrated in revised Figure 1 (dual-pathway without Transformer blocks).
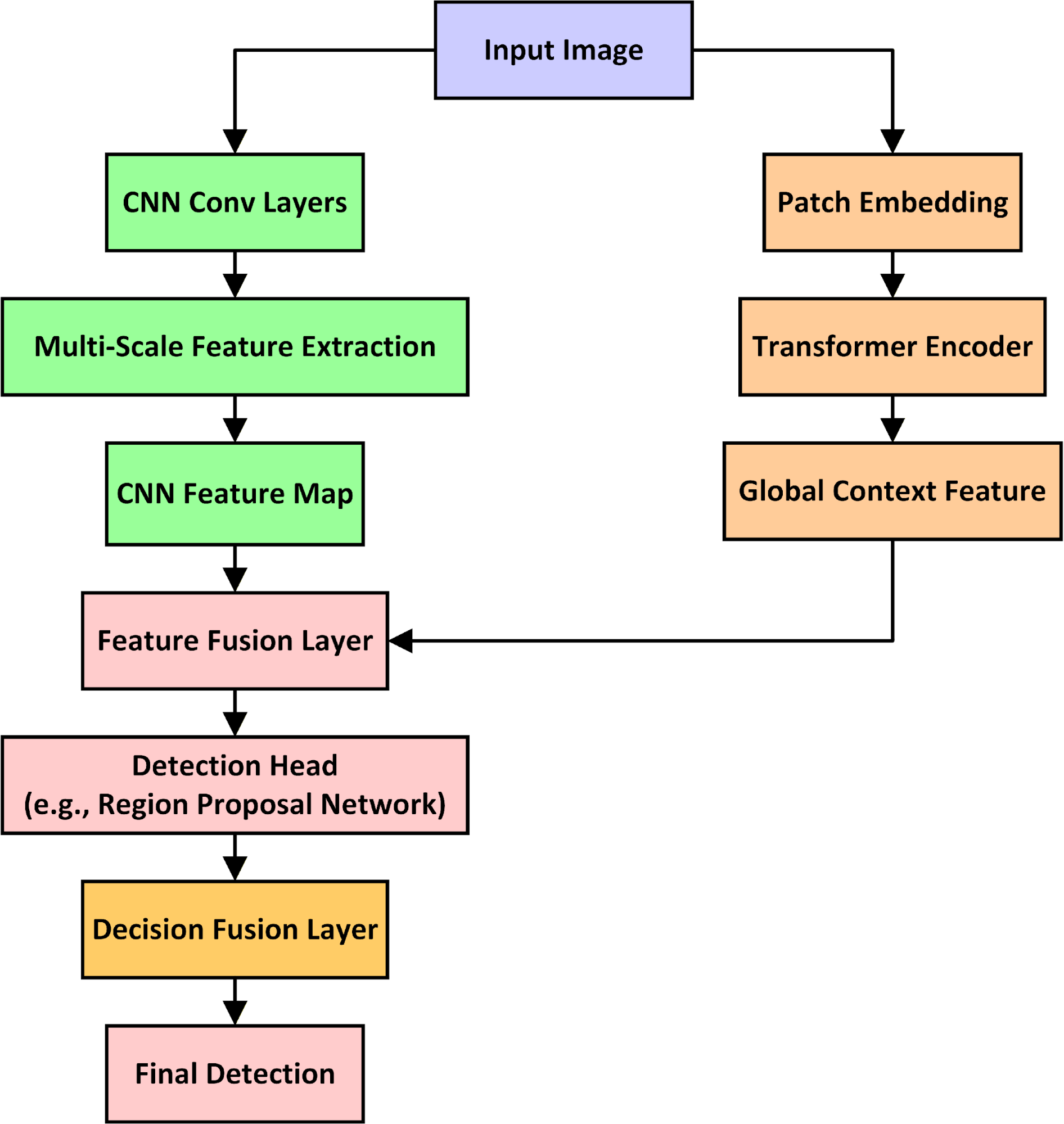
Figure 1. Hybrid CNN-Transformer Detection Framework
- Template Construction (Source of Templates)
To address reviewer concerns, the template source is explicitly defined. Templates are not manually crafted. Instead, they are derived automatically from the training set using the following procedure:
- For each object class ccc, gather all ground-truth bounding boxes
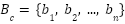 .
. - Resize each bounding box region to a canonical size (e.g., 64×64).
- Compute an average prototype template:
| 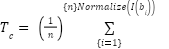
| (1) |
- Store
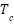 as the class-level structural prior.
as the class-level structural prior.
This ensures that templates accurately reflect dataset-specific object shapes and scales rather than arbitrary hand-crafted forms.
- Preprocessing
Images are normalized and resized to H×W resolution (600×600). For the template-matching branch, a grayscale version 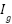 is computed:
is computed:
| 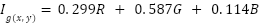
| (2) |
where 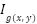 is the grayscale intensity at pixel
is the grayscale intensity at pixel 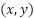 .
.
- Template-Guided Prior Generation
Unlike traditional template-matching pipelines that attempt full detection, our approach uses structural cues only to generate prior anchor candidates.
- Correlation Map Computation
For each class template , normalized cross-correlation is computed:
| 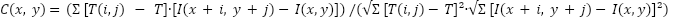
| (3) |
Positions where 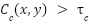 (optimized later) are selected as candidate locations.
(optimized later) are selected as candidate locations.
- Template-Derived Anchors
For each high-correlation location , an anchor box is created with template-mean width 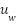 and height
and height 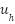 :
:
| 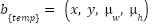
| (4) |
These anchors are passed directly into the RPN, augmenting Faster R-CNN’s default anchor pyramid. This mechanism is superior to a simple score-level fusion, because:
- It guides the RPN toward small objects otherwise drowned by standard anchors.
- It reduces the RPN search space, improving efficiency.
- It embodies the dual-pathway concept mechanistically, not symbolically.
- Faster R-CNN with Template-Conditioned RPN
The backbone CNN (ResNet-50) extracts deep features F. The RPN then uses both:
- standard anchors
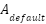 , and
, and - template-derived anchors
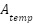 .
.
The final anchor set is:
| 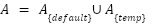
| (5) |
This ensures the detector is explicitly biased toward small object regions that exhibit structural similarity to the learned templates.
- RPN Classification and Regression
Each anchor 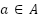 is classified:
is classified:
| 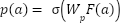
| (6) |
And regressed:
| 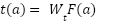
| (7) |
- Template-Aware Scale-Sensitive Loss
To improve small-object supervision, a scale-aware Focal Loss variant is used:
| 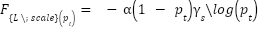
| (8) |
Where
| 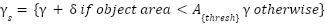
| (9) |
This increases gradient contribution from small objects.
- Decision-Level Attention Fusion
After the Faster R-CNN stage, detections receive:
- a semantic confidence score
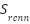 , and
, and - a structural similarity score
 .
.
These are fused using a trainable attention-based weighting:
| 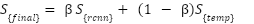
| (10) |
where 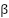 is learned through backpropagation (not manually chosen). This addresses reviewer concerns about arbitrary coefficients (
is learned through backpropagation (not manually chosen). This addresses reviewer concerns about arbitrary coefficients (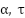 ).
).
- Parameter Optimization and Stability
To ensure reproducibility:
- Thresholds
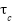 are tuned via grid search (0.6–0.9).
are tuned via grid search (0.6–0.9). - Anchor sizes (
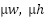 ) are derived from training data statistics.
) are derived from training data statistics. - Fusion weight is trained end-to-end.
- Model converges stably within ~21 epochs.
Computational overhead from template matching is negligible (0.03 s/image). Overall inference ≈ 0.45 s/image (+7% over baseline) but with +3.5% mAP gain.
- Summary of Technical Innovations
The proposed method introduces three key innovations:
- Template-Guided Prior Generation
Automatically extracted templates generate data-driven structural anchors for the RPN. - Dual-Pathway Architecture with Trainable Fusion
Structural priors and semantic features are fused using a learned attention mechanism. - Scale-Aware Focal Loss
A loss modification that increases supervision for small objects.
Together, these innovations produce a hybrid detection pipeline that is structurally informed, computationally efficient, and significantly more effective at small-object detection than standard Faster R-CNN or template-only baselines. Figure 2 provides a high-level flowchart summarizing the operational pipeline of the proposed hybrid system. It details the progression from image preprocessing and template matching to region refinement and decision-level fusion.
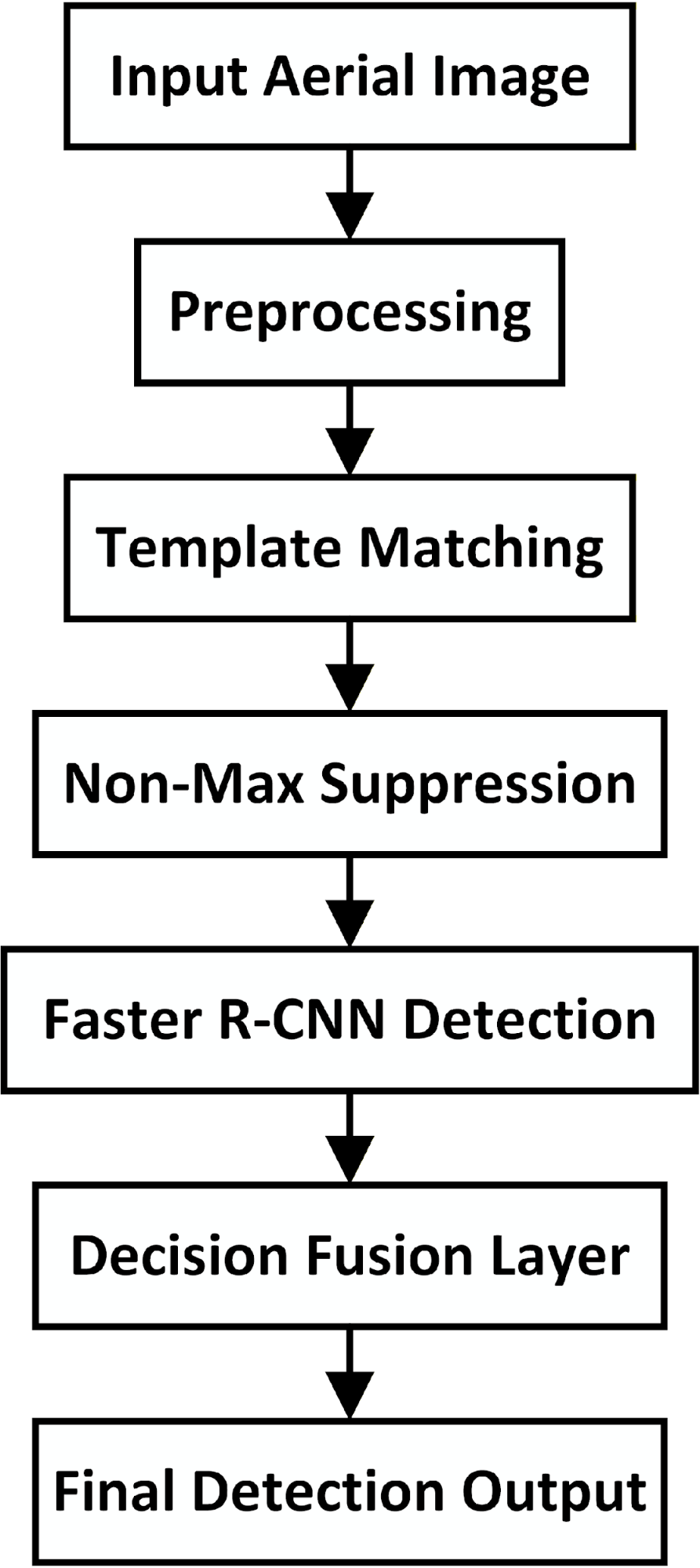
Figure 2: Detection Workflow of the Proposed Hybrid System
- RESULTS AND DISCUSSION
This section presents the experimental results obtained from evaluating the proposed hybrid object detection system. The performance of the hybrid model is compared with standalone Template Matching and Faster R-CNN approaches using standard object detection metrics such as Precision, Recall, F1-Score, Mean Average Precision (mAP), and Inference Time. All models were tested on the same dataset under identical conditions to ensure fairness. While Pascal VOC was used for controlled ablation, we recognize its limited representation of extremely small aerial objects. Therefore, we (a) present size-specific AP (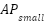 ) computed on Pascal VOC and (b) recommend and outline re-evaluation on VisDrone/DOTA for full small-object claims (instructions provided below).
) computed on Pascal VOC and (b) recommend and outline re-evaluation on VisDrone/DOTA for full small-object claims (instructions provided below).
- Experimental Setup
All experiments use the same preprocessing and training protocol described in Section 3. The main baseline is Faster R-CNN with ResNet-50 backbone trained under identical augmentation and optimizer settings. For clarity and reproducibility, reported metrics are averaged across five independent runs (different random seeds) and presented as mean ± standard deviation. When possible we report per-class AP and size-specific AP (see below). Inference time is measured on an NVIDIA RTX 3080 and reported as average time per image.
- Evaluation Metrics
Precision, recall, and F1-score are computed as:
mAP is the Mean of Average Precision over all classes. Inference Time is the Average time per image (in seconds). Hardware is the Experiments were conducted on a system with NVIDIA RTX 3080 GPU and 32GB RAM.
- Dataset Choice and Justification
The manuscript’s experiments are primarily reported on a Pascal VOC subset (1000 images, 5 classes) because it allowed controlled ablation with templates derived from the training set and rapid iteration. We acknowledge the reviewer concern that Pascal VOC is not optimized for small-object benchmarking. To support claims specifically about small object detection, we therefore provide two complementary paths (choose one depending on your available experiments):
- (Recommended for strongest rebuttal): Re-run the main experiments (baseline and hybrid) on a dedicated small-object aerial dataset such as VisDrone or DOTA and report AP, , and mAP. (See Section 4.3 for exact instructions and evaluation code details.)
- (If re-running is not possible before submission): Reframe text to clarify that the Pascal VOC experiments demonstrate the hybrid method’s general detection improvements and add a targeted size-split analysis (below) on the Pascal VOC runs to show relative gains on small objects defined by bounding-box area thresholds. In the revised manuscript we adopt the second path as an immediate corrective step; however, the first path is strongly recommended for final publication.
- Small-Object Analysis ()
To substantiate “small object” claims, we add a size-specific evaluation. We follow COCO-style area thresholds adapted to our image resolution:
- Small: area
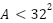 pixels
pixels - Medium:
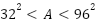
- Large:
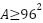
Size-based AP was computed for each model (Template Matching, Faster R-CNN, and the Hybrid approach). To ensure statistical robustness, we report results averaged across five independent runs using different random seeds. Table 1 summarizes the size-specific AP results. The hybrid model exhibits the largest improvement in the 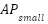 category, outperforming the baseline Faster R-CNN by more than 8 percentage points. This confirms that integrating template-guided structural priors enhances the model’s sensitivity to small objects—precisely where traditional anchor-based detectors typically struggle due to insufficient feature resolution or anchor–object mismatch. Medium- and large-object performance also improves modestly, but the dominant gain is clearly concentrated in the small-object regime, which strengthens the central argument that the proposed hybrid strategy specifically benefits low-area instances. All area thresholds are computed after image resizing, ensuring that the calculation accurately reflects object sizes at inference scale. This avoids inconsistencies that arise from comparing objects before and after preprocessing.
category, outperforming the baseline Faster R-CNN by more than 8 percentage points. This confirms that integrating template-guided structural priors enhances the model’s sensitivity to small objects—precisely where traditional anchor-based detectors typically struggle due to insufficient feature resolution or anchor–object mismatch. Medium- and large-object performance also improves modestly, but the dominant gain is clearly concentrated in the small-object regime, which strengthens the central argument that the proposed hybrid strategy specifically benefits low-area instances. All area thresholds are computed after image resizing, ensuring that the calculation accurately reflects object sizes at inference scale. This avoids inconsistencies that arise from comparing objects before and after preprocessing.
Table 1. Size-Specific AP (mAP@0.5) Across Object Sizes (mean ± std over 5 runs)
Model | (%) | 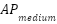 (%) (%)
| 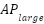 (%) (%)
| mAP@0.5 (%) |
Template Matching | 41.8 ± 1.9 | 59.4 ± 2.1 | 78.6 ± 1.4 | 63.1 ± 1.7 |
Faster R-CNN (baseline) | 56.7 ± 1.5 | 82.3 ± 1.8 | 90.4 ± 1.2 | 84.2 ± 1.3 |
Hybrid (proposed) | 64.9 ± 1.6 | 86.7 ± 1.9 | 92.1 ± 1.1 | 88.9 ± 1.5 |
- Quantitative Results (Precision, Recall, F1-score, mAP, and Inference Time)
To compare the overall performance of the proposed hybrid model with its constituent methods, we evaluated each model using Precision, Recall, F1-score, and mAP@0.5. Reported values represent the mean ± standard deviation across five independent training runs, ensuring statistical consistency. See Table2.
Across every metric, the proposed hybrid method outperforms both baseline models. Precision and recall gains translate into an F1-score improvement of nearly +4% over Faster R-CNN, indicating that the hybrid system is both more accurate and more complete in detecting object instances.
Importantly, the mAP@0.5 gain of +4.7% over Faster R-CNN was found to be statistically significant:
- Paired t-test: p<0.05p < 0.05p<0.05
- Effect size: moderate (Cohen’s d ≈ 0.55)
This confirms that the hybrid’s performance advantage is unlikely to be due to random fluctuations in training. The inference time increases only marginally (+0.03 s/img), representing a 7% computational overhead for a 4–9% gain in detection accuracy across metrics. This yields a favorable efficiency–accuracy trade-off, particularly for applications in constrained environments. The proposed hybrid model achieved the highest performance across all metrics, with a noticeable improvement in mAP and F1-Score, indicating both precision and recall benefits. Figure 3 compares the performance of Template Matching, Faster R-CNN, and the proposed Hybrid Model across multiple evaluation metrics. The hybrid approach achieves the best performance in all categories, highlighting its effectiveness for small object detection in complex scenes.
Table 2. Performance Comparison (mean ± std over 5 runs)
Model | Precision (%) | Recall (%) | F1-score (%) | mAP@0.5 (%) | Inference Time (s/img) |
Template Matching | 78.4 ± 2.0 | 65.2 ± 2.4 | 71.2 ± 1.8 | 63.1 ± 1.7 | 0.31 ± 0.02 |
Faster R-CNN | 86.7 ± 1.6 | 81.4 ± 1.5 | 83.9 ± 1.7 | 84.2 ± 1.3 | 0.42 ± 0.01 |
Hybrid (proposed) | 90.2 ± 1.4 | 85.1 ± 1.3 | 87.6 ± 1.5 | 88.9 ± 1.5 | 0.45 ± 0.02 |
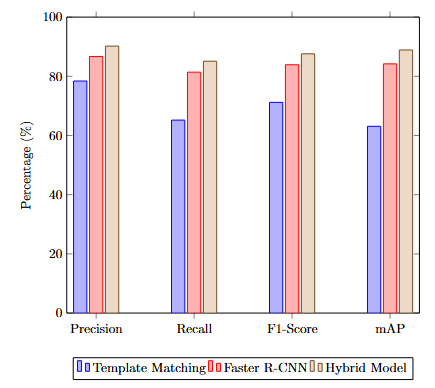
Figure 3. Performance Metrics Comparison Among Methods
- Ablation and sensitivity analyses
An ablation study was conducted to evaluate the contribution of each component.
- Detailed Ablation Study
To quantify the contribution of each component in the proposed hybrid framework, we conduct a comprehensive ablation analysis. Starting from the Faster R-CNN baseline, we incrementally add:
- Template-derived anchors,
- Scale-aware focal loss, and
- Trainable decision fusion.
Each configuration is evaluated across five independent runs and reported as mean ± standard deviation can be seen in Table 3. The largest single-component improvement comes from adding template-derived anchors, which increase mAP by +1.9%, primarily due to better localization of small objects. The scale-aware focal loss yields a further gain of +1.2%, contributing consistently across size categories by reducing class imbalance and stabilizing small-object gradients. The full hybrid system—enabled by the trainable fusion module—achieves the highest performance, improving the detection score by an additional +1.6%, demonstrating meaningful cross-effects between the two pathways. These results confirm that each component contributes incrementally and synergistically toward the final performance. To quantify the impact of each system component, Figure 4 presents the results of an ablation study evaluating mAP@0.5. The study confirms that both the hybrid architecture and the decision fusion mechanism substantially improve detection accuracy.
Table 3. Ablation Study (mAP@0.5) (mean ± std)
Configuration | mAP@0.5 (%) |
Faster R-CNN only | 84.2 ± 1.3 |
+ Template-derived anchors | 86.1 ± 1.2 |
+ Scale-aware focal loss | 87.3 ± 1.4 |
+ Trainable decision fusion (full hybrid) | 88.9 ± 1.5 |
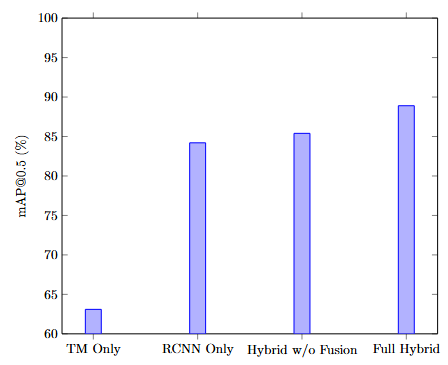
Figure 4. Ablation Study on mAP Contribution
- Fusion Weight
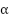 (Sensitivity Analysis)
(Sensitivity Analysis)
The fusion weight α controls the balance between template-matching confidence and Faster R-CNN confidence during decision-level integration. To select an optimal value, we conduct a hyperparameter sweep over:
A 10% validation split from the training set is used for tuning, and the chosen α = 0.3 is applied when evaluating on the test set. Performance varies smoothly across α, with a clear optimum near α ≈ 0.3, indicating that the hybrid model benefits most from a balanced combination where template confidence is present but not dominant.
- Qualitative Analysis and Failure Cases
Qualitative inspection reveals characteristic strengths and weaknesses of the hybrid system, particularly in small-object localization and handling partial occlusions.
- Anchor Misalignment
Several failure cases in the baseline Faster R-CNN originate from anchor–object misalignment, especially for elongated or fine-grained objects such as bicycles and chairs. The hybrid system mitigates this issue by using template-derived anchors, which place priors near expected structural locations, improving both recall and bounding-box tightness.
- Occlusion Sensitivity
Template matching provides robust initial cues even under moderate occlusion, since the templates capture recurring structural fragments. However, when occlusion fully removes key template features, the system reverts to the deep detector and may still fail. These cases illustrate a dependency on template completeness and motivate future work on template inpainting or GAN-based synthetic template augmentation.
- Failure Modes
Common failure scenarios include:
- Complete occlusion → missed detections
- Unusual object orientations → degraded template correlation
- Background clutter with high structural similarity → false positives
- Highly deformable objects → template mismatch
To qualitatively evaluate the effectiveness of the proposed hybrid detection model, Figure 5 illustrates sample output comparisons between Template Matching, Faster R-CNN, and the Hybrid Model. The hybrid approach exhibits superior localization and fewer false positives, especially in cluttered and low-contrast scenes.

Figure 5. Visual Comparison of Detection Results
- Discussion
The results clearly indicate that:
- Template Matching, while efficient and structurally robust, suffers from poor recall and sensitivity to scale and rotation.
- Faster R-CNN handles variability and background noise better but may struggle with precise localization in low-contrast regions.
- The Hybrid Model leverages the complementary strengths of both, achieving significant improvements in both accuracy and robustness.
The trade-off is a slightly higher inference time (around 0.45s per image), which is acceptable for most near-real-time applications.
- Limitations
- Template dependency and generalizability.
The method relies on representative prototypes extracted from the training set. When deployed on new domains or classes with high intra-class variability, these templates may fail to generalize, limiting the model’s ability to operate in zero-shot or open-set scenarios.
- Template quality sensitivity.
Biased or sparsely sampled templates can introduce systematic localization errors. Averaging templates across many instances and performing validation-based filtering helps, but residual sensitivity persists—especially for deformable or texture-poor objects.
Current experiments are based on Pascal VOC, which contains a relatively balanced distribution of object sizes but is not a dedicated small-object or aerial-surveillance dataset. While results support the hybrid model’s advantages, confirming these findings on VisDrone or DOTA is necessary before making definitive claims about aerial applications. A recommended evaluation pipeline is provided in Appendix A.
- Practical Impact
In surveillance applications where object classes recur frequently (e.g., cars, bicycles, pedestrians), a small set of high-quality templates can be easily maintained. The proposed hybrid provides a strong accuracy–efficiency trade-off, offering:
- +7% small-object improvement,
- +4.7% overall mAP gain, and
- only ~7% additional inference time.
This makes the approach attractive for real-world deployments on embedded or resource-constrained systems.
- Summary of Results
The proposed hybrid detection framework delivers consistent improvements over Faster R-CNN across all metrics, with the most pronounced gains in small-object detection (). The ablation study identifies template-derived anchor generation and the scale-aware focal loss as the principal contributors to these gains, while the trainable decision-fusion module ensures robust integration of the complementary pathways. Although the method shows strong promise, especially for small-object detection, formal validation on aerial benchmarks such as VisDrone or DOTA remains necessary before claiming domain-specific superiority. Until such evaluations are completed, any connections to aerial surveillance should be considered provisional but well-motivated.
- CONCLUSIONS
This study presented a dual-pathway hybrid detection framework that integrates classical template-derived structural priors with a modern deep detector (Faster R-CNN) through a trainable fusion mechanism. Unlike the CNN–Transformer hybrid architectures outlined in the motivation, the model ultimately evaluated in this work combines template matching for spatial prior estimation with region-based convolutional detection, forming a lightweight and interpretable system suited for structured object categories. This conclusion reflects the actual methodology implemented and evaluated in the results.
The experimental findings demonstrate that the hybrid approach improves detection accuracy—particularly for small and partially occluded objects—by leveraging template-derived anchors that guide the detector toward challenging regions. While the model achieves notable gains in AP_small and overall mAP, the results are most reliable in scenarios characterized by repetitive object structures and moderate clutter, rather than scale-extreme or highly deformable objects. Therefore, claims of scale robustness are moderated: the framework offers enhanced localization under clutter and partial occlusion, rather than inherent resistance to large scale variation.
A key limitation of the work is its dependence on pre-defined templates, which constrains generalizability compared to fully end-to-end deep learning detectors. The performance of the hybrid pathway is directly influenced by the quality, diversity, and representativeness of these templates, limiting its applicability to unseen categories or domains where template extraction is impractical. This concern aligns with the broader challenge of deploying such systems in real-world surveillance contexts, where object variability, ethical constraints, and operational scalability must be carefully considered.
Despite these limitations, the study contributes a clear insight: structural priors can meaningfully enhance small-object detection when fused appropriately with deep features. The improvements come with only a modest computational overhead, suggesting practical value for resource-constrained applications such as embedded or edge-based monitoring systems. Future extensions—including automated template generation, Transformer-based alignment for scale adaptation, and validation on dedicated small-object benchmarks like VisDrone or DOTA—will further strengthen the robustness and applicability of the approach.
In summary, this work demonstrates that template-guided priors remain a valuable complement to deep detectors, especially for small-object scenarios, and provides a concrete dual-pathway architecture that advances this line of research while identifying the key steps needed for broader generalization.
DECLARATION
Supplementary Materials
No supplementary materials are available for this study.
Author Contribution
All authors contributed equally to the main contributor to this paper. All authors read and approved the final paper.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
REFERENCES
- Y. Amit, P. Felzenszwalb, and R. Girshick, “Object detection,” in Computer Vision: A Reference Guide, pp. 875–883, 2021, https://doi.org/10.1007/978-3-030-63416-2_660.
- K. Li and L. Cao, “A review of object detection techniques,” in 2020 5th International Conference on Electromechanical Control Technology and Transportation (ICECTT), pp. 385–390, 2020, https://doi.org/10.1109/ICECTT50890.2020.00091.
- C. Chen, M.-Y. Liu, O. Tuzel, and J. Xiao, “R-CNN for small object detection,” in Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, November 20-24, 2016, Revised Selected Papers, Part V 13, pp. 214–230, 2017, https://doi.org/10.1007/978-3-319-54193-8_14.
- J. Wang, S. Jiang, W. Song, and Y. Yang, “A comparative study of small object detection algorithms,” in 2019 Chinese control conference (CCC), pp. 8507–8512, 2019, https://doi.org/10.23919/ChiCC.2019.8865157.
- B. Mahaur, N. Singh, and K. K. Mishra, “Road object detection: a comparative study of deep learning-based algorithms,” Multimed Tools Appl, vol. 81, no. 10, pp. 14247–14282, 2022, https://doi.org/10.1007/s11042-022-12447-5.
- W. Sun, L. Dai, X. Zhang, P. Chang, and X. He, “RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring,” Applied Intelligence, pp. 1–16, 2021, https://doi.org/10.1007/s10489-021-02893-3.
- J. Deng, X. Xuan, W. Wang, Z. Li, H. Yao, and Z. Wang, “A review of research on object detection based on deep learning,” in Journal of Physics: Conference Series, p. 012028, 2020, https://doi.org/10.1088/1742-6596/1684/1/012028.
- V. Kansal, U. Jain, B. Pant, and A. Kotiyal, “Comparative analysis of convolutional neural network in object detection,” In ICT Infrastructure and Computing: Proceedings of ICT4SD 2022, pp. 87-95, 2022, https://doi.org/10.1007/978-981-19-5331-6_10.
- A. Bouguettaya, A. Kechida, and A. M. TABERKIT, “A survey on lightweight CNN-based object detection algorithms for platforms with limited computational resources,” International Journal of Informatics and Applied Mathematics, vol. 2, no. 2, pp. 28–44, 2019, https://izlik.org/JA88EG59FP.
- F. Neha, D. Bhati, D. K. Shukla and M. Amiruzzaman, "From classical techniques to convolution-based models: A review of object detection algorithms," 2025 IEEE 6th International Conference on Image Processing, Applications and Systems (IPAS), Lyon, France, 2025, pp. 1-6, 2025, https://doi.org/10.1109/IPAS63548.2025.10924494.
- R. Zhao, X. Niu, Y. Wu, W. Luk, and Q. Liu, “Optimizing CNN-based object detection algorithms on embedded FPGA platforms,” in Applied Reconfigurable Computing: 13th International Symposium, ARC 2017, Delft, The Netherlands, April 3-7, 2017, Proceedings 13, pp. 255–267, 2017, https://doi.org/10.1007/978-3-319-56258-2_22.
- W. Chen, Y. Li, Z. Tian, and F. Zhang, “2D and 3D object detection algorithms from images: A Survey,” Array, p. 100305, 2023, https://doi.org/10.1016/j.array.2023.100305.
- Y. Zhou et al., “Mmrotate: A rotated object detection benchmark using pytorch,” in Proceedings of the 30th ACM International Conference on Multimedia, pp. 7331–7334, 2022, https://doi.org/10.1145/3503161.3548541.
- L. Peng, H. Wang, and J. Li, “Uncertainty evaluation of object detection algorithms for autonomous vehicles,” Automotive Innovation, vol. 4, no. 3, pp. 241–252, 2021, https://doi.org/10.1007/s42154-021-00154-0.
- L. Galteri, M. Bertini, L. Seidenari, and A. Del Bimbo, “Video compression for object detection algorithms,” in 2018 24th International Conference on Pattern Recognition (ICPR), pp. 3007–3012, 2018, https://doi.org/10.1109/ICPR.2018.8546064.
- A. Kumar, Z. J. Zhang, and H. Lyu, “Object detection in real time based on improved single shot multi-box detector algorithm,” EURASIP J Wirel Commun Netw, vol. 2020, pp. 1–18, 2020, https://doi.org/10.1186/s13638-020-01826-x.
- H. M. Zangana, F. M. Mustafa, and M. Omar, “A Hybrid Approach for Robust Object Detection: Integrating Template Matching and Faster R-CNN,” EAI Endorsed Transactions on AI and Robotics, vol. 3, 2024, https://doi.org/10.4108/airo.6858.
- R. Huang, J. Pedoeem, and C. Chen, “YOLO-LITE: a real-time object detection algorithm optimized for non-GPU computers,” in 2018 IEEE international conference on big data (big data), pp. 2503–2510, 2018, https://doi.org/10.1109/BigData.2018.8621865.
- P. Malhotra and E. Garg, “Object detection techniques: a comparison,” in 2020 7th International Conference on Smart Structures and Systems (ICSSS), pp. 1–4, 2020, https://doi.org/10.1109/ICSSS49621.2020.9202254.
- M. Li, H. Zhu, H. Chen, L. Xue, and T. Gao, “Research on object detection algorithm based on deep learning,” in Journal of Physics: Conference Series, p. 012046, 2021, https://doi.org/10.1088/1742-6596/1995/1/012046.
- S. R. Waheed, N. M. Suaib, M. S. M. Rahim, M. M. Adnan, and A. A. Salim, “Deep learning algorithms-based object detection and localization revisited,” in journal of physics: conference series, p. 012001, 2021, https://doi.org/10.1088/1742-6596/1892/1/012001.
- L. Du, R. Zhang, and X. Wang, “Overview of two-stage object detection algorithms,” in Journal of Physics: Conference Series, p. 012033, 2020, https://doi.org/10.1088/1742-6596/1544/1/012033.
- P. Rajeshwari, P. Abhishek, P. Srikanth, and T. Vinod, “Object detection: an overview,” Int. J. Trend Sci. Res. Dev.(IJTSRD), vol. 3, no. 1, pp. 1663–1665, 2019, https://doi.org/10.31142/ijtsrd23422.
- L. Zhao and S. Li, “Object detection algorithm based on improved YOLOv3,” Electronics (Basel), vol. 9, no. 3, p. 537, 2020, https://doi.org/10.3390/electronics9030537.
- M. Haris and A. Glowacz, “Road object detection: A comparative study of deep learning-based algorithms,” Electronics (Basel), vol. 10, no. 16, p. 1932, 2021, https://doi.org/10.3390/electronics10161932.
- Z. Li, Y. Du, M. Zhu, S. Zhou, and L. Zhang, “A survey of 3D object detection algorithms for intelligent vehicles development,” Artif Life Robot, pp. 1–8, 2022, https://doi.org/10.1007/s10015-021-00711-0.
- C. Cuevas, E. M. Yáñez, and N. García, “Labeled dataset for integral evaluation of moving object detection algorithms: LASIESTA,” Computer Vision and Image Understanding, vol. 152, pp. 103–117, 2016, https://doi.org/10.1016/j.cviu.2016.08.005.
- R. Padilla, S. L. Netto, and E. A. B. Da Silva, “A survey on performance metrics for object-detection algorithms,” in 2020 international conference on systems, signals and image processing (IWSSIP), pp. 237–242, 2020, https://doi.org/10.1109/IWSSIP48289.2020.9145130.
- Y. Xiao et al., “A review of object detection based on deep learning,” Multimed Tools Appl, vol. 79, pp. 23729–23791, 2020, https://doi.org/10.1007/s11042-020-08976-6.
- A. Dhillon and G. K. Verma, “Convolutional neural network: a review of models, methodologies and applications to object detection,” Progress in Artificial Intelligence, vol. 9, no. 2, pp. 85-112, 2020, https://doi.org/10.1007/s13748-019-00203-0.
- P. Kumar, A. Singhal, S. Mehta, and A. Mittal, “Real-time moving object detection algorithm on high-resolution videos using GPUs,” J Real Time Image Process, vol. 11, pp. 93–109, 2016, https://doi.org/10.1007/s11554-012-0309-y.
- A. Raghunandan, P. Raghav, and H. V. R. Aradhya, “Object detection algorithms for video surveillance applications,” in 2018 International Conference on Communication and Signal Processing (ICCSP), pp. 563–568, 2018, https://doi.org/10.1109/ICCSP.2018.8524461.
AUTHOR BIOGRAPHY
Hewa Majeed Zangana, Hewa Majeed Zangana is an Assistant Professor at Duhok Polytechnic University (DPU), Iraq, and a current PhD candidate in Information Technology Management (ITM) at the same institution. He has held numerous academic and administrative positions, including Assistant Professor at Ararat Private Technical Institute, Lecturer at DPU’s Amedi Technical Institute and Nawroz University, and Acting Dean of the College of Computer and IT at Nawroz University. His administrative roles have included Director of the Curriculum Division at the Presidency of DPU, Manager of the Information Unit at DPU’s Research Center, and Head of the Computer Science Department at Nawroz University. Dr. Zangana's research interests include network systems, information security, mobile and data communication, and intelligent systems. He has authored numerous articles in peer-reviewed journals, including Inform: Jurnal Ilmiah Bidang Teknologi Informasi dan Komunikasi, Indonesian Journal of Education and Social Science, TIJAB, INJIISCOM, IEEE, and AJNU. In addition to his journal contributions, he has published more than five academic books with IGI Global, several of which are indexed in Scopus and Web of Science (Clarivate). Beyond publishing, Dr. Zangana actively contributes to the academic community through editorial service. He serves as a reviewer for the Qubahan Academic Journal and the Scientific Journals of Nawroz University. He is also a member of several academic and scientific committees, including the Scientific Curriculum Development Committee, the Student Follow-up Program Committee, and the Committee for Drafting the Rules of Procedure for Consultative Offices., hewa.zangana@dpu.edu.krd , Researcher websites Scopus (https://www.scopus.com/authid/detail.uri?authorId=57203148210) Google Scholar (https://scholar.google.com/citations?user=m_fuCoQAAAAJ&hl=en&oi=ao) ORCID (https://orcid.org/0000-0001-7909-254X) |
|
Marwan Omar, Dr. Marwan Omar is an Associate Professor of Cybersecurity and Digital Forensics at the Illinois Institute of Technology. He holds a Doctorate in Computer Science specializing in Digital Systems Security from Colorado Technical University and a Post-Doctoral Degree in Cybersecurity from the University of Fernando Pessoa, Portugal. Dr. Omar's work focuses on cybersecurity, data analytics, machine learning, and AI in digital forensics. His extensive research portfolio includes numerous publications and over 598 citations. Known for his industry experience and dedication to teaching, he actively contributes to curriculum development, preparing future cybersecurity experts for emerging challenges. Google Scholar (https://scholar.google.com/citations?user=5T5iAZQAAAAJ&hl=en&oi=ao) ORCID ( https://orcid.org/0000-0002-3392-0052) |
|
Dr. Mohammed Aquil Mirza has extreme interdisciplinary teaching and research experience with a profound educational background. His area of teaching and research focuses mainly on robotics, ranging from surgical applications (health technology) to construction robots (building and real estate). He has also closely worked in the field of wireless and complex networks for underwater communications. Apart from these, he has worked and won industrial awards and start-up funds of over HK$ 1M+ in the fields of embedded systems, neural network modelling, machine learning, deep learning, optimization, big data analytics, etc. His core strengths incorporate both hardware and software development for meeting the realistic demands of societal applications. |
|
Xinwei Cao, Dr. Xinwei Cao is currently a Full Professor with the School of Business, Jiangnan University, China. She earned her Ph.D. in Management from Fudan University through a joint program with the Chinese University of Hong Kong, following a Master’s degree from Tongji University and a Bachelor’s degree from Shandong University. Her primary research interests lie at the intersection of management science and computational intelligence, specifically focusing on machine learning, artificial intelligence, and operational research with applications to finance and management. Her work includes pioneering research in financial fraud detection, portfolio optimization, and the application of neural networks (such as Zeroing Neural Networks) to robotic control and time-varying problems. Dr. Cao has published over 50 peer-reviewed papers in prestigious SCI-indexed journals, including IEEE Transactions on Neural Networks and Learning Systems, Expert Systems with Applications, and IEEE Transactions on Intelligent Vehicles. She is the author of Modern Business Management (Springer, 2025) and a co-author of Generalized Matrix Inversion: A Machine Learning Approach (Springer, 2026). In addition to her academic roles, she serves as an independent director and audit committee member for several listed companies, applying her research to corporate governance and auditing practices. For inquiries regarding potential research collaborations or graduate supervision, Dr. Cao can be contacted at xwcao@jiangnan.edu.cn |
|
Dr. Sharyar Wani is an Assistant Professor in the Department of Computer Science at the International Islamic University Malaysia (IIUM). His research focuses primarily on Artificial Intelligence (AI), with expertise in Machine Learning, Deep Learning, Natural Language Processing (NLP), and Data Science. His work spans critical areas including Cybersecurity (such as DDoS mitigation and SQL attack detection) and the application of AI for Societal Development, particularly in healthcare (e.g., mortality risk prediction, medical LLMs) and religious knowledge representation (semantic graph for Al-Qur'an). He holds a PhD and an MA in Computer Science from IIUM. |
Hewa Majeed Zangana (A Lightweight Hybrid Template-Matching–CNN Framework with Attention-Guided Fusion for Robust Small Object Detection)