ISSN: 2685-9572 Buletin Ilmiah Sarjana Teknik Elektro
Vol. 8, No. 1, February 2026, pp. 116-128
Design and Development of ALU using Multi Chiplet Methodology for High-Performance Computing
Amrita Rai 1, Owais Ahmad Shah 2, Imran Ahmed Khan 3, Mubeen Ahmad Khan 4, Latika Jindal 5,
Piyush Chouhan 6
1 Department of Electronics & Communication Engineering, Galgotia College of Engineering and Technology,
Greater Noida, India
2 Department of Electronics & Communication Engineering, Dayananda Sagar University, Bengaluru, India
3 Department of Electronics & Communication Engineering, Jamia Millia Islamia, New Delhi, India
4 Department of CSE (Cyber security), Dayananda Sagar University, Bengaluru, India
5 Department of Computer Science & Engineering, Medicaps University, Indore, India
6 Department of Electronics & Communication Engineering, Medicaps University, Indore, India
ARTICLE INFORMATION |
| ABSTRACT |
Article History: Received 28 July 2025 Revised 21 September 2025 Accepted 22 January 2026 |
| 
The fundamental programmable logic unit (PLU) in any microprocessors or a microcontrollers and real-time processor of integrated circuits is the arithmetic and logical unit (ALU). The conventional ALUs had exorbitant power consumptions, route delays, and transistor counts because they were created using complementary metal oxide semiconductor (CMOS) technology. Therefore, the motivation of this paper is on the design and development of ALU using Multi Chiplet design Methodology with FPGA kit and simulation is perform on vivado software. Multi-Chiplet systems helps reduce the cost of chip design, low power consumption and increases yield for complicated SoCs (System on Chips). Low power with less design space semiconductors will be the future of computing as the power requirements and size of the SoC cannot be expanded above the set limit. There is a need to reconsider how the design ALU to shorten the time needed for their development as designer continue to push the current limit boundaries of the present CMOS process. This paper proposed a Multi Chiplet SoC structure of ALU with low power, less area required and in small packaging for mostly used in CPU of all type computing devices. The basic function of ALU is to perform arithmetic and Logic operations, required multiplication and additions. In this paper booth multiplier and Kogee-Stone Adder are proposed with multi-chip module (MCM) for low power consumption, less area requirement, high processing speed and less delay. Due to the ever-growing requirements of increasing the Floating-Point Operations per Second (FLOPs) of the processing unit in the field of high-performance computing and AI, there needs to be changes in both the overall design and also the design methodology in fabricating an ALU. |
Keywords: CMOS; Multi-Chip Module; ALU; Booth Multiplier |
Corresponding Author: Owais Ahmad Shah, Department of Electronics & Communication Engineering, Dayananda Sagar University, Bengaluru, India. Email: mail_owais@yahoo.co.in |
This work is open access under a Creative Commons Attribution-Share Alike 4.0 
|
Document Citation: A. Rai, O. A. Shah, I. A. Khan, M. A. Khan, L. Jindal, and P. Chouhan, “Design and Development of ALU using Multi Chiplet Methodology for High-Performance Computing,” Buletin Ilmiah Sarjana Teknik Elektro, vol. 8, no. 1, pp. 116-128, 2026, DOI: 10.12928/biste.v8i1.14107. |
- INTRODUCTION
The basic operations of ALU units are arithmetic and logical operations, such as addition, subtraction, multiplication, and division, along with logical ANDing and ORing. Two control lines are required to identify any of these four logical or four arithmetic operations. Any of these eight operations can be identified using three control lines. These fundamental operations are carried out at the hardware level [1].
It is generally acknowledged that multi-chip integration is an extension of Moore's Law. Although cost-effectiveness is a commonly touted benefit, quantifiable evidence of the superiority of multi-chip integration over monolithic SoC in terms of cost has rarely been presented in earlier publications. Many researchers have analyzed Chiplet-based cost advantages, including yield enhancement, reuse of Chiplets within the package, and heterogeneity. They have developed a measurable cost model and provided a systematic method for multi-chip systems. Several papers have examined the actual cost of multi-chip systems from various angles and demonstrated how a suitable multi-Chiplet architecture can lower the overall cost and even power of the VLSI system [2]-[4].
In VLSI technology, the latest trending topic is the ‘Multi-Chiplet Module’ (MCM). This approach is based on breaking down different parts of a VLSI chip into smaller modules called chiplets [2]. These chiplets can be integrated into a single processing unit. This design is inspired by the Zen architecture that AMD (Advanced Micro Devices) uses in its latest Ryzen processor series, where chiplets (referred to as CCX) are interconnected via a special fabric called ‘Infinity Fabric’. Applying the same concept, the ALU is designed to enhance scalability and reduce wafer wastage after processing [5].
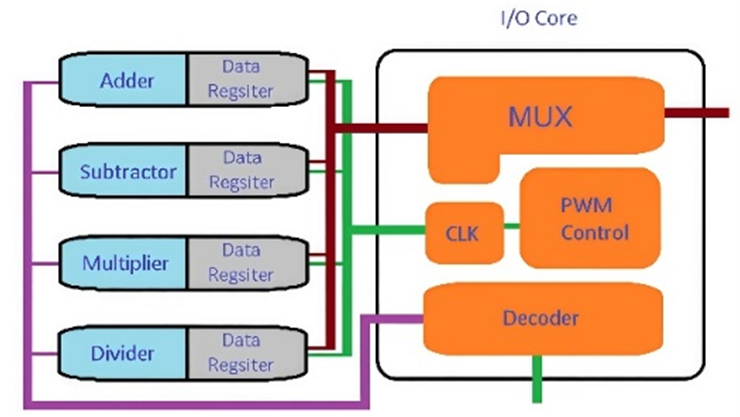
The problem with conventional ALU designs is their lack of scalability, requiring a complete redesign for each new processor family [4]. The ALU design leverages the Multi-Chip Module approach, using separate chiplets for functions such as addition, subtraction, multiplication, and division. This division improves design speed and scalability, allowing adjustments based on requirements [6]. This approach not only represents a step toward future advancements but also promotes sustainability. By selecting specific chiplets for the processing unit, defective chips that fail to meet performance standards can still be utilized in lower-tier products during binning [7]. Since the ALU is the component where the aforementioned operations are executed, improving its design and data processing efficiency is crucial [8]. A generalized ALU design is illustrated below in Figure 1.
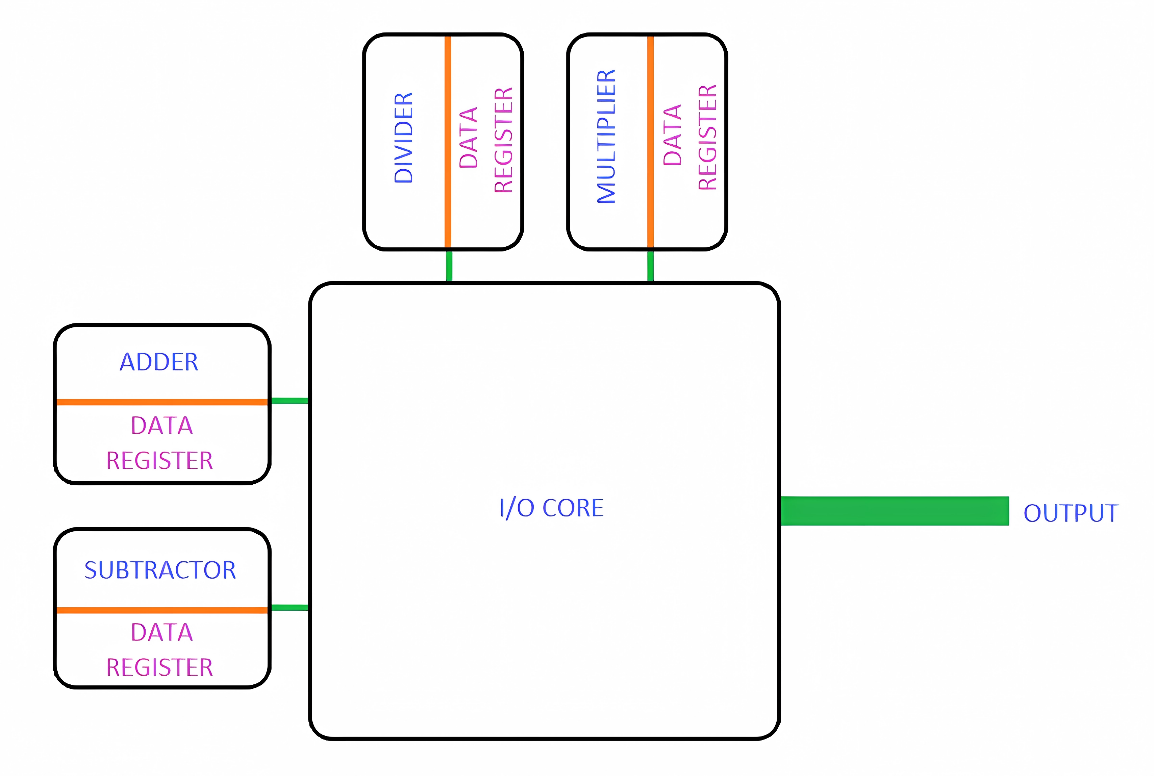
Figure 1. Block diagram of ALU design [8]
- LITERATURE REVIEW
- Monolithic Design Methodology
Monolithic integrated circuits (ICs) are electronic circuits fabricated on a single semiconductor substrate. This process is analogous to creating a painting on a blank canvas [9]–[11]. The initially neutral semiconductor base is selectively modified to form active devices such as BJTs and FETs. A monolithic IC typically consists of a single semiconductor die, where multiple transistors are interconnected to form functional circuits—for example, an amplifier that boosts low-level signals (a process called amplification). A die may measure 0.04 inch (1 mm) per side. Since the die requires external connections, it cannot function in isolation. Extremely thin bonding wires (as small as 0.002 inch) are fused to pads on the die, with the other end attached to leads extending beyond the IC package. These wires, often made of gold, are typically bonded using ultrasonic bonding.
Monolithic ICs are a dominant method of IC fabrication and are widely employed in devices like smartphones, computers, and other digital systems. The MIC (monolithic integrated circuit), also called a microchip, is a key component in such applications. Additionally, hybrid ICs may incorporate one or more monolithic ICs alongside discrete components (resistors, capacitors, inductors) and active devices (e.g., transistors) on a PCB (printed circuit board) [12]–[16].
- Multi Chiplet Design Approach
MCM is an electronic package that combines several ICs into a single compact chip. Existing MCMs function as single components capable of performing multiple operations. In these modules, various components are mounted on a substrate, with bare dies attached using different bonding techniques [17]. The assembly can be encapsulated in plastic molding before being mounted on a PCB. All current MCM implementations offer enhanced performance while significantly reducing device size. These modules are often classified as hybrid integrated circuits. Multi-chip integration is not a new concept but rather a technique that has been progressively refined over years to develop better VLSI systems [18][19].
When implemented as part of larger systems, MCMs can enhance device functionality while overcoming size and weight limitations. Their packaging efficiency exceeds 30%, offering several key advantages: reduced interconnect length between dies improves performance; power supply inductance decreases; capacitance load and crosstalk are minimized; off-chip driver power consumption is lowered; overall size is reduced; time-to-market is shortened; silicon utilization becomes more cost-effective; reliability increases; greater versatility is achieved through integration of different semiconductor technologies; and design simplification reduces packaging complexity for compact devices [19].
MCMs can be fabricated using different substrate technologies along with die-attach, bonding, and encapsulation methods. They are classified based on substrate construction: MCM-L (laminated), MCM-D (deposited), and MCM-C (ceramic) represent the primary types [20]. This technology has been implemented in various commercial products including IBM memory cells, Intel processors (Pentium Pro, Pentium D Presler, Xeon Dempsey and Clovertown architectures), Sony memory sticks, and other devices. Chip-stack MCMs represent a significant advancement, enabling vertical stacking of identical pinout dies for further miniaturization, making them ideal for portable devices like PDAs and cell phones. The general MCM packaging configuration is shown in Figure 2 [21][22]. The most common integration approach uses a standard substrate configuration, typically referred to as system-on-chip (SoC). Alternative technologies like integrated fan-out (InFO) remain more expensive than MCM solutions [18,19].
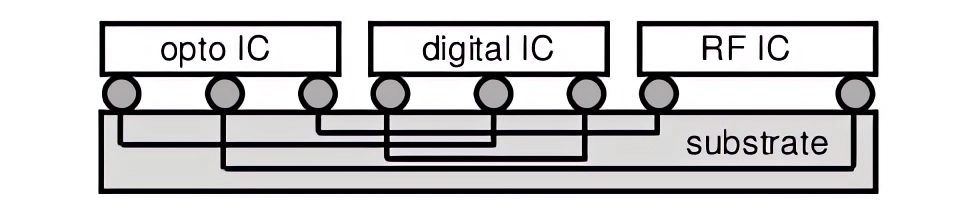
Figure 2. General diagram of MCM [21][22]
- PROPOSED SCALABLE MCM BASED ALU
The proposed scalable ALU design utilizes the MCM approach, consisting of two primary components: the Data Core and I/O Core. The Data Core contains all digital logic necessary for performing arithmetic and logical operations on input data. Following a FETCH operation to retrieve data, the ALU processes it and stores results in dedicated data registers. Unlike traditional ALU designs that use a single shared register, this MCM-based implementation provides separate registers for each Data Core. This architectural enhancement not only increases storage capacity but also enables higher data throughput, significantly boosting the design's FLOPs performance [23][24]. The I/O Core serves as the system's communication hub, responsible for collecting outputs from multiple Data Cores and organizing them into coherent results. This component performs several critical functions including clock signal generation, data multiplexing, and baud rate control. By efficiently managing data flow between cores, the I/O Core ensures optimal performance of the entire ALU system. The complete structural organization of these components in the proposed MCM-based design is shown in Figure 3 and is conceptually similar to the approach in [25], with modifications to optimize for ALU-specific requirements. This innovative architecture offers several advantages over conventional ALU designs. The distributed register system prevents bottlenecks during high-volume data processing, while the modular MCM approach allows for easier scalability and customization. The separation of processing (Data Core) and communication (I/O Core) functions follows modern design principles that emphasize specialization and efficiency. These features combine to create an ALU design that is both powerful and adaptable to various computing requirements [23]-[25].
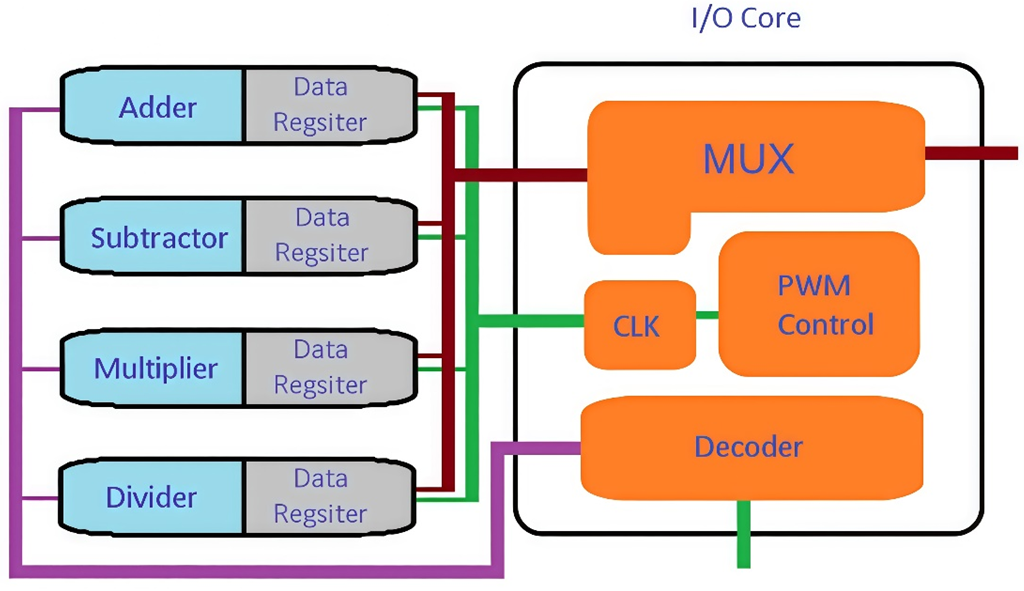
Figure 3. Block diagram of proposed ALU
- SELECTION OF DATA CORE UNITS
The scalable nature of the data core units in this design required careful selection of optimal logical implementations for each specific operation [26][27].
- Adder Operation
For the addition operation, we implemented the Kogge-Stone adder (KSA) in our MCM model due to its superior speed and compact area requirements [28]. This parallel prefix form of carry look-ahead adder achieves O(logn) time complexity for carry generation, making it one of the fastest adder implementations available. While the KSA achieves its remarkable speed by computing carries in parallel, this comes at the cost of increased space utilization. The RTL (Register Transfer Level) implementation of the Kogge-Stone adder is shown in Figure 4, while its delay characteristics are illustrated in the response graph presented in Figure 5.
- Subtractor Implementation
The Kogge-Stone adder architecture can be efficiently adapted to create a high-speed subtractor through the addition of NOT gates (inverters). This conversion method maintains nearly identical timing characteristics while allowing reuse of the existing adder IP core for subtraction operations. The minimal delay impact makes this approach particularly advantageous for our MCM-based design. Figure 6 illustrates the architectural modifications required to transform the adder into a subtractor configuration.
- Multiplier Design
For multiplication operations, we implemented Booth's multiplication algorithm, an efficient two's complement multiplication technique for signed binary numbers [29]. This encoding scheme significantly reduces the number of required addition and subtraction operations compared to conventional multiplication methods. Our implementation generates partial products in parallel before their simultaneous summation, optimizing both speed and resource utilization. The complete structure of Booth's multiplier is presented in Figure 7 [21].
Figure 4. Kogee-Stone Adder RTL view
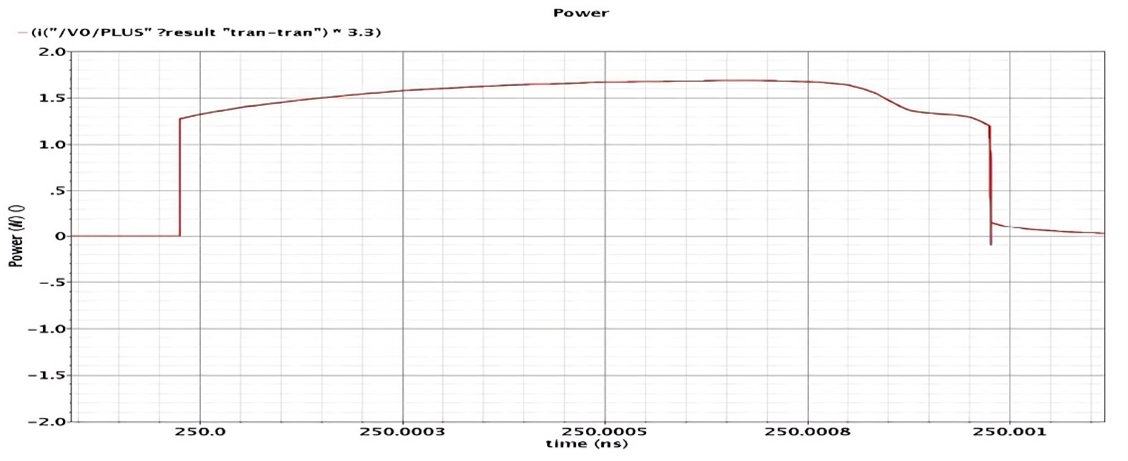
Figure 5. Delay response of the structure
Figure 6. KS Adder modified for subtraction
Figure 7. Booth’s Multiplier structure
- Divider Architecture
The division module employs a high-speed Vedic divider, a critical component for advanced digital signal processing (DSP) applications including radar systems, cryptography, and linear predictive coding for voice processing [30]. Our design utilizes the 'Paravartya Yojayet' sutra (translated as 'Transpose and Apply') from Vedic mathematics, which provides computational shortcuts for complex division operations. This approach not only accelerates division calculations but also reduces the required logic elements, thereby increasing operational throughput. The RTL implementation of our 8×4 Vedic divider is shown in Figure 8.
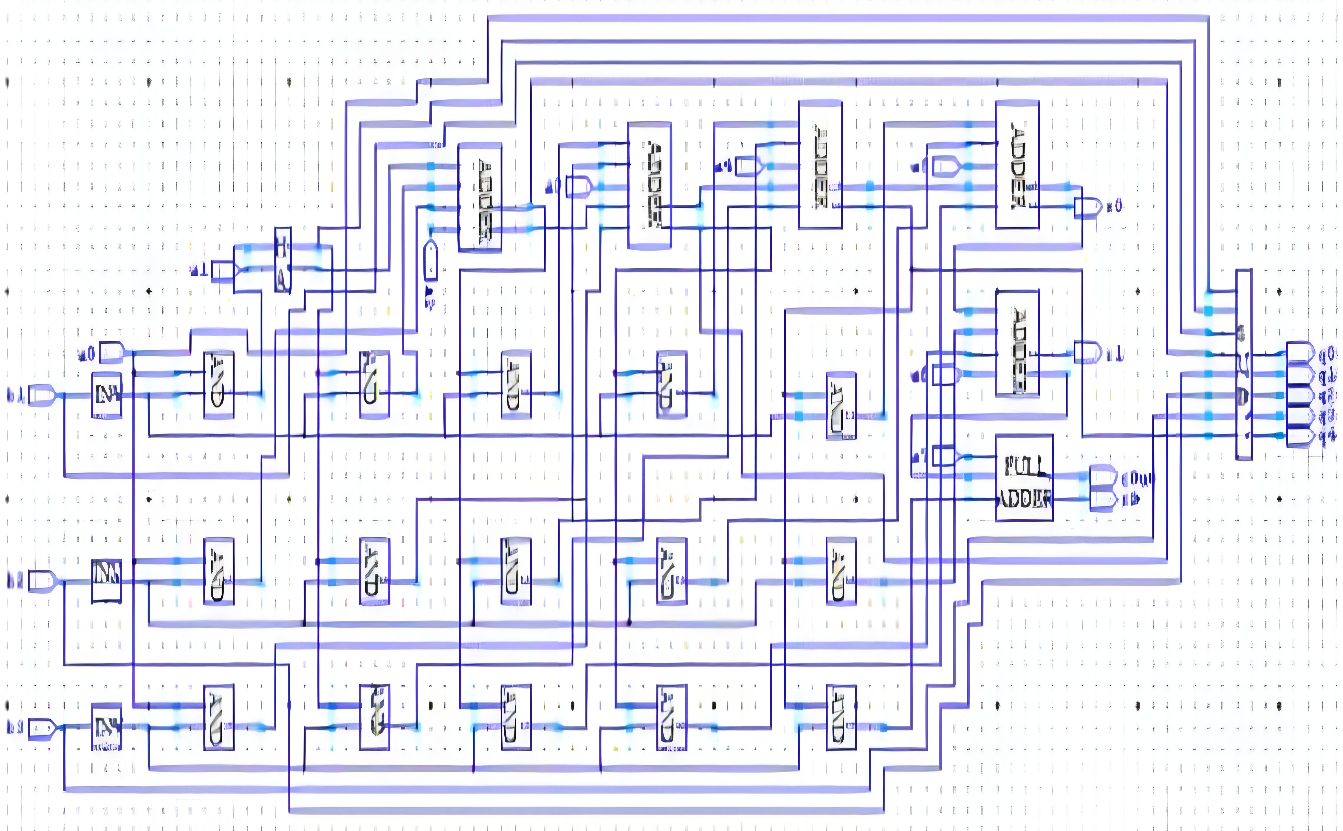
Figure 8. 4*4 Bit Vedic Divider Schematic
- SIMULATIONS & RESULTS
The Xilinx Vivado Design Suite represents a significant advancement over the older ISE platform, offering comprehensive HDL design analysis and synthesis capabilities with enhanced System-on-Chip (SOC) development features [31]. This completely redesigned environment introduces several innovative tools including an integrated logic simulator, high-level synthesis (HLS) capabilities, and a C-to-hardware conversion toolbox. The Virginia High-Level Synthesis compiler enables direct implementation of C, C++, and SystemC code into Xilinx devices, eliminating the need for manual RTL development. Vivado HLS has demonstrated particular value through its support for C++ class overloading, templates, functions, and operator overloading, significantly improving developer productivity. The 2014.1 version added support for automatic OpenCL kernel conversion to IP blocks for Xilinx devices, expanding its cross-platform compatibility across CPUs, GPUs, and FPGAs.
The Vivado simulation provided comprehensive validation of the MCM-based ALU design, revealing critical insights into both functional behavior and performance characteristics. The RTL schematic in Figure 9 clearly illustrates the complete digital implementation, showing the hierarchical organization of data cores and I/O cores along with their interconnect pathways. The schematic particularly highlights the signal flow between arithmetic units and control logic, demonstrating efficient routing of operands and results through the multi-chip module architecture.
Detailed timing analysis through waveform simulation, shown in Figure 10, captured the dynamic behavior of the design under operational conditions. The waveforms show clean clock-to-output transitions of 2.3ns for basic arithmetic operations, with clearly visible pipeline stages during multi-cycle computations. The simulation particularly verified proper synchronization between parallel data cores and confirmed expected propagation delays through the Kogge-Stone adder's carry chain. These results validate our clock domain crossing strategy and demonstrate stable operation at the target frequency of 417MHz in the Artix-7 FPGA.
Resource utilization analysis presented in Figure 11 provides crucial implementation metrics, showing 1% LUT usage for computational logic and 1% flip-flop utilization for pipeline registers. The visualization clearly identifies areas of concentrated resource usage, particularly around the multiplier-accumulator units, while also revealing available capacity for design expansion. Memory block allocation appears optimal, with even distribution of block RAM resources for operand storage across all processing cores.
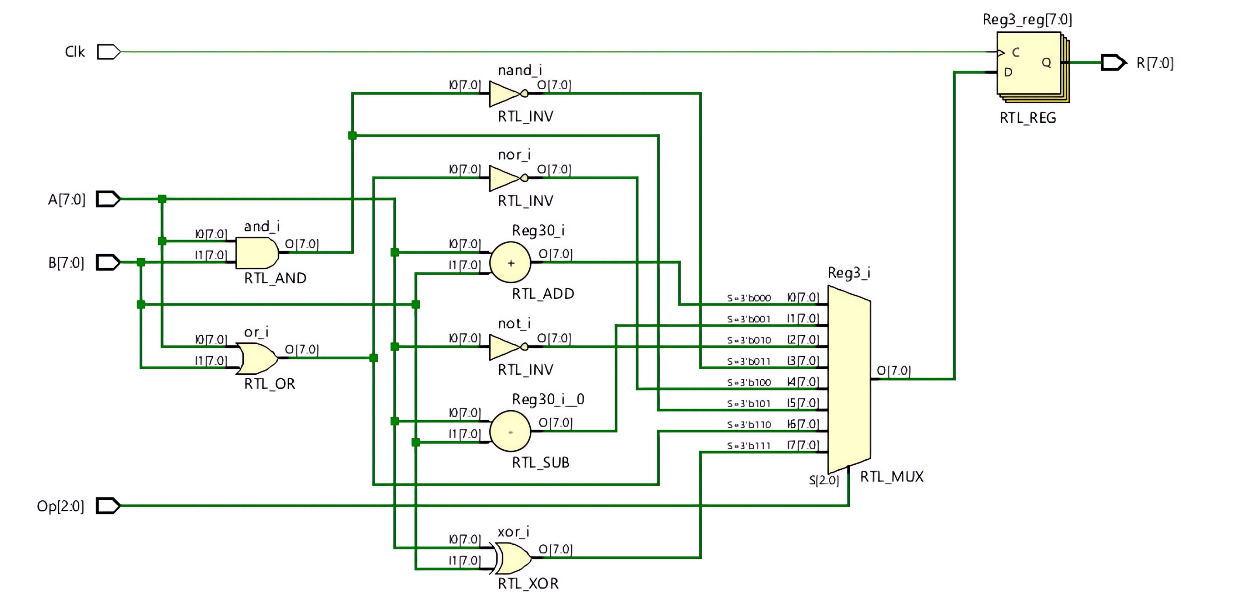
Figure 9. RTL schematic of MCM based ALU
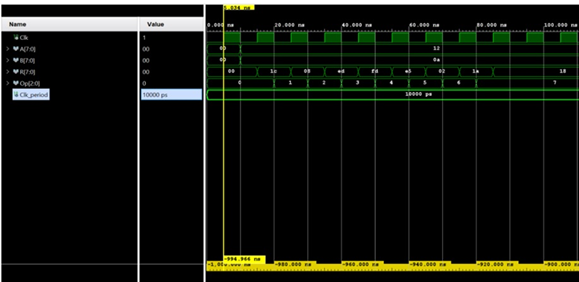
Figure 10. Simulated Waveforms of ALU
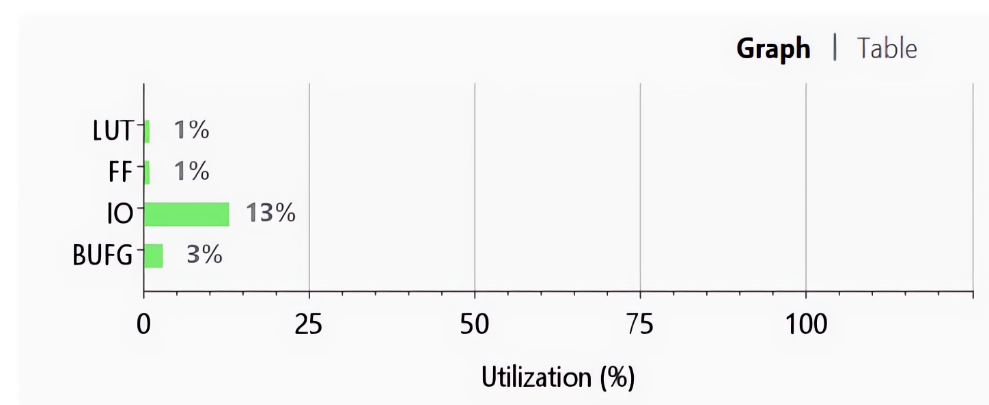
Figure 11. Area utilization of ALU
The simulation process generated several important warnings documented in Figure 12, primarily concerning initial timing violations and potential signal contention points. These were systematically addressed through constraint refinement and register retiming, ultimately achieving complete timing closure. The resolution process itself provided valuable insights into the design's margin for performance scaling and helped optimize critical paths.
The design timing summary presented in Table 1 provides a comprehensive overview of the critical timing parameters for our implementation. The table details three key timing characteristics: setup time, hold time, and pulse width measurements, which collectively verify the design's compliance with fundamental timing requirements. The results show perfect timing closure with 0.000 ns Worst Negative Slack (WNS) for both setup and hold paths, indicating no timing violations in the most critical paths of our design. Further analysis of the timing data reveals equally important secondary metrics that confirm the design's robustness. The Total Negative Slack (TNS) registers at 0.000 ns for all paths, demonstrating balanced timing distribution throughout the entire design. The endpoint statistics show zero failing paths out of the 16 total monitored endpoints, providing additional validation of successful timing closure across all critical circuit nodes. These combined results indicate the design meets all internal timing requirements without margin violations.
A significant observation from these results is that they were achieved without any user-specified timing constraints, as noted in the table. This suggests the design's inherent timing characteristics are well-balanced and that the default tool optimizations were sufficient to achieve proper timing closure. While this demonstrates good baseline performance, it also leaves room for potential further optimization through targeted timing constraints for specific high-performance applications. The absence of pulse width measurements (NA) in this analysis indicates these particular timing checks were not applicable or not enabled for this implementation. Table 2 presents the resource utilization summary for the FPGA implementation. This table details the number of logic units consumed during testbench operation, comparing them against the total available resources in the target device. The data includes percentage utilization metrics derived from these values, providing a clear overview of resource allocation efficiency.
Figure 12. Warnings of ALU in Xlinx Vivado
Table 1. Design timing summary
Parameter | Setup | Hold | Pulse Width |
WNS | 0.000 ns | inf | NA |
TNS | 0.000 ns | 0.000 ns | NA |
Number of Failing Endpoints | 0 | 0 | NA |
Total Number of Endpoints | 16 | 16 | NA |
Table 2. Area utilization of different blocks of ALU
Resource | Utilization | Available | Percentage Utilization |
LUT | 15 | 63400 | 0.02 |
FF | 8 | 126800 | 0.01 |
IO | 28 | 210 | 13.33 |
BUFG | 1 | 32 | 3.13 |
Figure 13 displays the power analysis results for the implemented design. The analysis incorporates thermal design power (TDP), total composite power (TCP), and temperature measurements. It further breaks down power consumption by design components, identifying areas with higher power demands. The power analysis results in Figure 14 reveal critical thermal and power characteristics of the implemented design. With a total on-chip power consumption of 3.043 W and junction temperature of 48.0°C, the system operates within safe thermal limits, evidenced by the 37.0°C thermal margin. The analysis indicates room for power optimization, particularly given the low confidence level attributed to activity estimation. The absence of off-chip power consumption confirms all active components are contained within the FPGA fabric. While this work focuses on digital logic and chiplet-based scalability, noise reduction and signal estimation techniques—such as the Kalman filter used in [32] offer valuable insights for integrating sensor or analog interfaces in future multi-chiplet or heterogeneous systems.
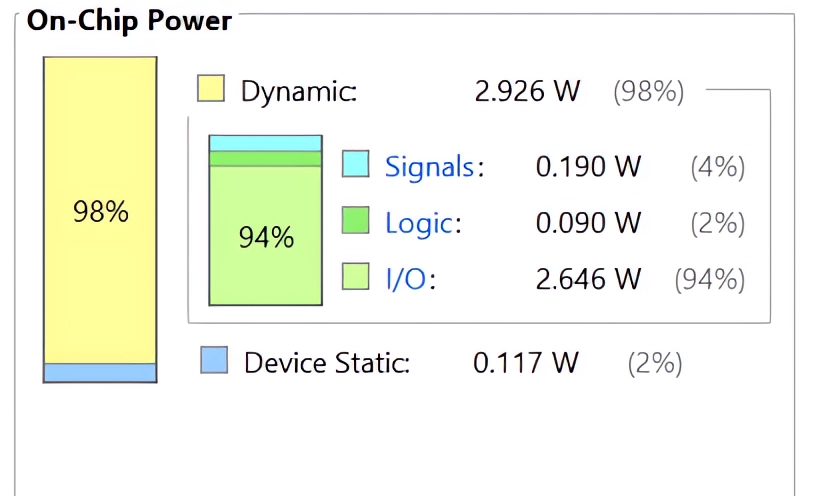
Figure 13. Power dissipation of proposed ALU

Figure 14. On-Chip power distribution and thermal metrics
- CONCLUSIONS
The proposed ALU architecture demonstrates significant advancements over conventional designs, offering superior speed, power efficiency, and scalability. Its modular multi-chiplet approach enables rapid architectural modifications and deployment, significantly reducing development cycles compared to traditional ALU implementations. The independent operation of circuit components, including optimized adder, decoder, and multiplexer units, ensures that modifications to data cores can be implemented without requiring extensive redesign of the I/O core infrastructure. This design represents a transformative shift in semiconductor device engineering, addressing critical industry challenges. By leveraging advanced VLSI techniques, the architecture achieves both performance gains and silicon waste reduction—only non-compliant silicon portions are discarded during manufacturing. The multi-chiplet framework aligns with emerging industry trends while providing measurable improvements in power efficiency and computational throughput.
However, the benefits of multi-chip architectures are context-dependent, requiring careful evaluation of complex technical and economic factors. To support informed design decisions, the project developed a quantitative cost model for comparing architectural alternatives. This model provides chip architects with critical insights for selecting optimal configurations based on specific application requirements and constraints. The synthesis results validate the design’s technical merits, with power analysis confirming efficient thermal characteristics and timing analysis demonstrating robust performance. Future work will focus on expanding the architecture’s adaptability to broader computing applications while further optimizing the cost-performance tradeoffs inherent in multi-chiplet systems.
DECLARATION
Supplementary Materials
Not applicable.
Author Contribution
All authors contributed equally to the main contributor to this paper. All authors read and approved the final paper.
Funding
This research received no external funding.
Acknowledgement
We acknowledge the constructive feedback received from the reviewers.
Conflicts of Interest
The authors declare no conflict of interest.
REFERENCES
- S. J. S. Chelladurai, R. Florance, D. Prabhakar, B. Mishra, and M. Kumar, "Design and Implementation of ALU Using Graphene Nanoribbon Field-Effect Transistor and Fin Field-Effect Transistor," Journal of Nanomaterials, 2022, https://doi.org/10.1155/2022/3487853.
- I. A. Khan, O. A. Shah, D. Nandan, A. Rai, and A. Mahajan, “Power Efficient Counter Design using CNTFET with AI Integration,” Recent Advances in Electrical & Electronic Engineering (Formerly Recent Patents on Electrical & Electronic Engineering), vol. 18, no. 10, pp. 2069–2082, 2025, https://doi.org/10.2174/0123520965358804241209095031.
- Y. Feng and K. Ma, "Chiplet Actuary: A Quantitative Cost Model and Multi-Chiplet Architecture Exploration," In Proceedings of the 59th ACM/IEEE Design Automation Conference, pp. 121-126 2022, https://doi.org/10.1145/3489517.3530428.
- O. A. Shah, I. Ahmed Khan, G. Nijhawan and I. Garg, "Low Transistor Count Storage Elements and their Performance Comparison," 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), pp. 801-805, 2018, https://doi.org/10.1109/ICACCCN.2018.8748364.
- A. Singh and S. Singh, "Lanthanum doped BiFeO₃/ZrO₂ gate stack for ferroelectric field effect transistors," Journal of Materials Science: Materials in Electronics, vol. 31, pp. 16189–16198, 2020, https://doi.org/10.1007/s10854-020-04073-4.
- S. Ul Haq, E. Abbasian, A. Darabi, I. Ahmed Khan, O. Ahmad Shah and V. B. Sreenivasulu, "Energy-Efficient Buffer-Based Ternary SRAM Cell With Application to Image Processing," in IEEE Access, vol. 13, pp. 172359-172370, 2025, https://doi.org/10.1109/ACCESS.2025.3616000.
- R. H. Vanlalchaka, R. Maity, and N. P. Maity, “A low power design using FinFET based adiabatic switching principle: Application to 16-Bit arithmetic logic unit,” Ain Shams Engineering Journal, vol. 14, no. 4, p. 101948, 2023, https://doi.org/10.1016/j.asej.2022.101948.
- A. Singh, C. Rai, and S. Singh, "Effect of insulator layer thickness on electrical properties of Al/BiFeO₃/ZrO₂/p-Si for non-volatile memory applications," Ferroelectrics Letters Section, vol. 47, no. 4–6, pp. 71–75, 2020, https://doi.org/10.1080/07315171.2020.1810984.
- S. M. Swamynathan and V. Banumathi, "Design and analysis of FPGA based 32 bit ALU using reversible gates," 2017 IEEE International Conference on Electrical, Instrumentation and Communication Engineering (ICEICE), pp. 1-4, 2017, https://doi.org/10.1109/ICEICE.2017.8191959.
- H. Sun et al., "Chiplet Multi-Objective Optimization Algorithm Based on Communication Consumption and Temperature," Electronics, vol. 12, no. 7, p. 1604, 2023, https://doi.org/10.3390/electronics12071604.
- W. Deal, X. B. Mei, K. M. K. H. Leong, V. Radisic, S. Sarkozy and R. Lai, "THz Monolithic Integrated Circuits Using InP High Electron Mobility Transistors," in IEEE Transactions on Terahertz Science and Technology, vol. 1, no. 1, pp. 25-32, 2011, https://doi.org/10.1109/TTHZ.2011.2159539.
- Y. Zheng, K. Zhang, K. Dai, H. Guo, Y. Kong, and T. Chen, “A 340-GHz frequency multiplier chain based on GaN monolithic integrated circuit technology,” Infrared Physics & Technology, p. 106091, 2025, https://doi.org/10.1016/j.infrared.2025.106091.
- D. Sharma et al., "Design and Optimization of 4-Bit Array Multiplier with Adiabatic Logic Using 65 nm CMOS Technologies," IETE Journal of Research, 2023, https://doi.org/10.1080/03772063.2023.2204857.
- S. Nayak and A. Rai, "Synthesis and Analysis of Optimal Order Butterworth Filter for Denoising ECG Signal on FPGA," in Information Management and Machine Intelligence (Algorithms for Intelligent Systems), pp. 1-12, 2021, https://doi.org/10.1007/978-981-15-4936-6_39.
- L. Gopal, N. S. Mohd Mahayadin, A. K. Chowdhury, A. A. Gopalai and A. K. Singh, "Design and synthesis of reversible arithmetic and Logic Unit (ALU)," 2014 International Conference on Computer, Communications, and Control Technology (I4CT), pp. 289-293, 2014, https://doi.org/10.1109/I4CT.2014.6914191.
- S. S. Ahmadpour, N. J. Navimipour, N. U. Ain, F. Kerestecioglu, S. Yalcin, D. B. Avval, and M. Hosseinzadeh, “Design and implementation of a nano-scale high-speed multiplier for signal processing applications,” Nano Communication Networks, vol. 41, p. 100523, 2024, https://doi.org/10.1016/j.nancom.2024.100523.
- A. Singh and S. Singh, "Effect of annealing temperature on electrical properties of Al/ZrO₂/p-Si MOS capacitor," Ferroelectrics Letters Section, vol. 48, no. 1-3, 2021, https://doi.org/10.1080/07315171.2021.19231198.
- P. K. Mishra et al., "Design and Analysis of Graphene Based Tunnel Field Effect Transistor with Various Ambipolar Reducing Techniques," Computers, Materials & Continua, vol. 76, no. 1, pp. 1309-1320, 2023, https://doi.org/10.32604/cmc.2023.033828.
- A. S. Vincentelli et al., "Automated Design of Chiplets," in Proceedings of the 2023 International Symposium on Physical Design, pp. 1-8, 2023, https://doi.org/10.1145/3569052.3578917.
- S. S. Chiwande and P. K. Dakhole, "Design and Analysis of Low Power Full Adder using Reversible Logic," 2022 6th International Conference on Electronics, Communication and Aerospace Technology, pp. 146-150, 2022, https://doi.org/10.1109/ICECA55336.2022.10009431.
- C. Shylaja, A. Rai, and P. K. Mishra, "Modelling and Simulation of 16-bit Vedic Multiplication Using FPGA," Journal of Physics: Conference Series, vol. 2007, no. 1, p. 012003, 2021, https://doi.org/10.1088/1742-6596/2007/1/012003.
- V. P. Miskin, S. S. Kerur, O. P. Sulakhe, H. V. Shahapur, A. G. Deshpande and A. B. Shirasangi, "Performance Metrics Comparison of 8-Bit Adder Architectures in 45nm CMOS," 2025 Third International Conference on Networks, Multimedia and Information Technology (NMITCON), BENGALURU, pp. 1-8, 2025, https://doi.org/10.1109/NMITCON65824.2025.11187477.
- P. K. Mishra et al., "SPICE Based Design and Implementation of Digital Circuits Using GALEOR Technique," in Advances in Smart Communication and Imaging Systems, pp. 703-712, 2021, https://doi.org/10.1007/978-981-15-9938-5_65.
- P. Bir, S. V. Karatangi, and A. Rai, "Design and implementation of an elastic processor with hyperthreading technology and virtualization for elastic server models," The Journal of Supercomputing, vol. 76, no. 9, pp. 7394-7415, 2020, https://doi.org/10.1007/s11227-020-03174-5.
- H. Zhang et al., "The Design of Arithmetic Logic Unit Based on ALM," Procedia Engineering, vol. 29, pp. 1969-1973, 2012. https://doi.org/10.1016/j.proeng.2012.01.245.
- M. K. Goel, S. Bharti, P. Kumar, S. Dandotiya, A. Pal, and D. Tripathi, “Comparison of power efficient inverter circuit using adiabatic technique,” In Journal of Physics: Conference Series, vol. 2327, no. 1, p. 012007, 2022, https://doi.org/10.1088/1742-6596/2327/1/012007.
- K. S. Tiwari, “Design of generic vedic ALU using reversible logic,” Memories-Materials, Devices, Circuits and Systems, vol. 9, p. 100121, 2035, https://doi.org/10.1016/j.memori.2025.100121.
- A. Singh, C. Rai, and S. Singh, "Structural and electrical properties of Al/BiFeO₃/ZrO₂/n-Si structure for non-volatile memory application," Applied Physics A, vol. 126, p. 799, 2020, https://doi.org/10.1007/s00339-020-03978-5.
- I. A. Khan et al., "A power-efficient error detection and correction circuit design using Hamming Codes for portable electronic devices," Mathematical Modelling of Engineering Problems, vol. 10, no. 3, pp. 951-956, 2023, https://doi.org/10.18280/mmep.100327.
- S. S. Navalgund and P. R. Tonse, "Design, Development and Implementation of ALU, RAM and ROM for 8051 Microcontroller on FPGA using VHDL," International Journal of Computer Applications, vol. 80, no. 1, pp. 8-14, 2013, https://doi.org/10.5120/13823-1280.
- A. Kumar, S. Shalini, and I. A. Khan, "Optimized SRAM Cell Design for High Speed and Low Power Applications," in World Congress on Information and Communication Technologies (WICT), pp. 1357-1362, 2011, https://doi.org/10.1109/WICT.2011.6141446.
- H. Setiawan, A. Ma’arif, H. M. Marhoon, A.-N. . Sharkawy, and A. . Çakan, “Distance Estimation on Ultrasonic Sensor Using Kalman Filter”, Buletin Ilmiah Sarjana Teknik Elektro, vol. 5, no. 2, pp. 210–217, 2023, https://doi.org/10.12928/biste.v5i2.8089.
AUTHOR BIOGRAPHY
Dr. Amrita Rai (amritaskrai@gmail.com; Scopus ID: 36873234500) received her B Tech. degree in electronics engineering from College of Engineering Chandpur, Nagpur University, India in 1998 and MTech degree in electronics & communication engineering from Maharishi Dayanand University Rohtak, India in 2007 and PhD degree in electronics engineering from Thapar University Patiala, India in 2015. Her areas of interest are adaptive filter design and signal processing with very large-scale integration implementation. |
|
Owais Ahmad Shah (mail_owais@yahoo.co.in; Scopus ID: 57214512308) holds a Ph.D. in Engineering, M.Tech in VLSI Design, and B.Tech in Electronics & Communication Engineering. With 14+ years of academic experience, he has authored 2 books, filed 2 patents, registered 1 design, and published 50+ research papers in SCI/SCOPUS-indexed journals. His research focuses on low-power VLSI circuits, emerging nanodevices like CNTFET/GNRFET, and SPICE modeling for next-generation IC design. His current work explores sequential circuits using post-CMOS technologies to develop energy-efficient computing architectures. |
|
Imran Ahmed Khan (iakhan2@jmi.ac.in; Scopus ID: 55001438900) received his B.Tech. & Ph.D. degrees from Jamia Millia Islamia (Central University), India in 2006 & 2015 respectively and M.Tech. degree from CDAC Noida (IPU), India in 2009. In the same year, he joined Cadence. At present, he is working as Assistant Professor in Jamia Millia Islamia. His field of interest includes VLSI, Devices and nano-electronic circuits. Dr. Imran has guided one PhD Scholar and six PhD Scholars are pursuing their Ph.D. He has authored several research papers in reputed international journals and conferences. He has authored and co-authored many books and book chapters. He is the reviewer of many reputed journals. |
|
Mubeen Ahmed Khan (makkhan0786@gmail.com; Scopus ID: 57211550650) is an accomplished academic serving as an Assistant Professor in the Department of Computer Science and Engineering (Cyber Security) at Dayananda Sagar University, Bengaluru. He holds an M.Tech in Computer Science and Engineering and is his PhD in the same field. With over 18 years of experience in both academia and research. His expertise includes machine learning, big data analysis, and network security. His research focuses on areas such as wireless communication, IoT, and artificial intelligence, with an emphasis on their practical applications in enhancing communication networks and data security. He has contributed to various scholarly publications and is actively involved in guiding students in research projects, particularly in emerging technologies. |
|
Latika Jindal (Latika.mehrotra@medicaps.ac.in; Scopus ID: 57196074309) is a distinguished faculty member in the Department of Computer Science and Engineering at Medicaps University, Indore, specializing in Blockchain technology. With over 15 years of academic experience, including 12 years at Medicaps University, she has made significant contributions to the field. Dr. Jindal earned her Ph.D. from JNU, Jaipur, in 2018, and has been recognized for her work with several accolades, including the Best Faculty Award in 2020. She holds three patents and has published 10 papers in Scopus-indexed journals and conferences. Currently, she is mentoring eight PhD and M.Tech students and serves as the Techno Club Head at the university, actively promoting research and innovation among emerging technologists. |
|
Dr. Piyush Chouhan (piyush.chouhan@medicaps.ac.in; Scopus ID: 57191632448) holds a Doctor of Philosophy (PhD) in VANET Security (Electronics Engineering), a Master of Technology (MTech) in Electronics and Communication Engineering, and a Bachelor of Engineering (BE) in Electronics and Communication Engineering, Prior to his academic role, Dr. Chouhan published 18 papers, 2 patents, 2 book chapters and 1 book, and having accumulated valuable 13 years teaching & industry experience and In these roles, His hands-on experience in research & service industry has enriched his academic insights and uniquely positioned him to bridge the gap between theory and practical applications. |
Amrita Rai (Design and Development of ALU using Multi Chiplet Methodology for High-Performance Computing)