Buletin Ilmiah Sarjana Teknik Elektro ISSN: 2685-9572
A Hybrid LSTM-CNN Approach Using Multilingual BERT for Sentiment Analysis of GERD Tweets
Atinkut Molla Mekonnen, Yirga Yayeh Munaye, Yenework Belayneh Chekol
Department of Information Technology, College of Engineering and Technology, Injibara University, Ethiopia
ARTICLE INFORMATION |
| ABSTRACT |
Article History: Received 18 April 2025 Revised 24 May 2025 Accepted 17 June 2025 |
| 
Analyzing public sentiment through platforms like Twitter is a common approach for understanding opinions on political matters. This study introduces a deep learning sentiment analysis model that integrates Long Short-Term Memory (LSTM) and Convolutional Neural Networks (CNN) to assess attitudes toward the Grand Ethiopian Renaissance Dam (GERD). LSTM is utilized to capture long-range dependencies in text, while CNN identifies significant local patterns. An initial dataset of 30,000 unlabeled tweets was collected in 2024 G.C., out of which 17,064 were labeled as positive, negative, or neutral. The labeled tweets were divided into 13,112 for training and the remaining for testing. The hybrid LSTM-CNN model demonstrated superior performance compared to the standalone models, delivering more accurate and balanced sentiment classification. A major feature of this study is the analysis of tweets written in Amharic, Arabic, and English. The model was trained over 35 epochs with a batch size of 46 and a learning rate of 0.001. Using multilingual BERT (mBERT) embeddings notably enhanced the model’s performance, with training and testing accuracies reaching 95.3% and 92%, respectively. The hybrid model also achieved a precision, recall, and F1-score of 90%. In a focused analysis of Arabic tweets, 3,710 were negative, 9,793 positive, and 4,814 neutral. These results emphasize the influence of linguistic diversity and class distribution on classification performance. While mBERT showed strong results, addressing class imbalance and expanding language-specific features remains crucial for further improvements. |
Keywords: Combined LSTM and CNN Approach; Tweets in Multiple Languages; GERD; Opinion Mining; Multilingual BERT Embeddings |
Corresponding Author: Atinkut Molla Mekonnen, Department of Information, Technology College of Engineering and Technology, Injibara University, Ethiopia. Email: Atinkut.Molla@inu.edu.et |
This work is licensed under a Creative Commons Attribution-Share Alike 4.0 
|
Document Citation: A. M. Mekonnen, Y. Y. Munaye, and Y. B. Chekol, “A Hybrid LSTM-CNN Approach Using Multilingual BERT for Sentiment Analysis of GERD Tweets,” Buletin Ilmiah Sarjana Teknik Elektro, vol. 7, no. 2, pp. 206-213, 2025, DOI: 10.12928/biste.v7i2.13281. |
INTRODUCTION
The Grand Ethiopian Renaissance Dam (GERD), officially named "ታላቁ የኢትዮጵያ ሕዳሴ ግድብ" in Amharic, represents a transformative hydroelectric project on Ethiopia's Blue Nile River. This study employs an innovative LSTM-CNN neural network architecture to perform sentiment classification of multilingual social media content (English, Amharic, and Arabic) concerning this controversial infrastructure development. Initiated in 2011 near Ethiopia's Sudanese border in Benishangul-Gumuz Region, GERD's 6.45GW capacity will position it as Africa's most powerful hydroelectric facility and among the world's top ten [1]-[2]. The project addresses Ethiopia's domestic energy demands while enabling regional power exports, though downstream nations Egypt and Sudan have raised concerns about hydrological impacts.The Blue Nile Basin, encompassing Lake Tana's Gilgel Abay tributary, exhibits particular climate vulnerability with projected shifts in rainfall and temperature regimes [3]-[5]. Our research applies NLP-based sentiment analysis to Twitter data, enabling systematic tracking of public opinion across linguistic groups. This computational approach automatically categorizes tweets as positive, negative or neutral through machine learning algorithms.
As the Nile Basin's nine hydrological zones [6]-[10] represent critical water management units, social media analytics provide real-time insights into transnational perspectives on GERD. The instantaneous nature of Twitter communications allows for monitoring evolving public sentiment, helping identify emerging concerns and misinformation patterns regarding the dam's socioeconomic consequences [7].This methodology combines:CNN networks for localized feature extraction from tweet text, LSTM layers to model sequential dependencies in multilingual content, Sentiment classification across three languages and Geopolitical context analysis of GERD-related discourse The hybrid architecture demonstrates particular effectiveness in handling Amharic's morphological complexity and Arabic's dialectal variations while maintaining strong performance on English tweets.
RELATED WORK
Pioneered sentiment analysis by focusing on sentiment polarity classification using Naive Bayes and Support Vector Machines (SVM). They worked with a dataset of 2000 movie reviews, classified into positive and negative categories. Their work explored the use of negation, word locations, and part-of-speech (POS) information but found that such strategies often reduced sentiment polarity accuracy. Their dataset, consisting of 1000 positive and 1000 negative reviews, became a standard for training and evaluating sentiment analysis models. Chetan Kaushik and Atul Mishra [11]-[17] advanced the field by employing a lexicon-based technique, using a domain-specific dictionary of sentiment-bearing words to classify tweets as positive, negative, or neutral. Their approach, implemented on Hadoop, achieved an impressive speed, analyzing 674,412 tweets in just 14.8 seconds, with an accuracy of 73.5%. However, the method was implemented on a single node, and its performance could be improved in a multi-node configuration. Proposed a combined approach for Arabic sentiment analysis, using a lexicon-based method, a maximum entropy model, and k-nearest neighbors (KNN) to classify documents. This multi-method approach achieved an accuracy of 80.29% after refining the results from earlier stages. Lei Zhang et al [18]. introduced a hybrid lexicon and learning-based method for Twitter sentiment analysis, using a lexicon-based approach to identify opinionated tweets and a classifier to assign sentiment polarities. Their unsupervised method showed significant improvements in recall and F-score compared to state-of-the-art techniques. Sentiment analysis techniques are broadly divided into machine learning-based and lexicon-based approaches. The machine learning method uses labeled datasets for supervised learning, while unsupervised methods are helpful when labeled data is scarce. The lexicon-based method relies on predefined sentiment lexicons to categorize text according to sentiment and includes both corpus-based and dictionary-based approaches. Deep learning techniques, such as CNNs and LSTM networks, have been successfully applied to sentiment analysis tasks in recent years [19]–[22]. These models often use word embeddings to represent text as sequences of vectors that can be processed by neural networks. CNNs, in particular, have shown effectiveness in feature extraction from text data due to their convolutional layers, which detect complex patterns. Unlike traditional neural networks, CNNs address the issue of vanishing gradients by using sparse connections and smaller filters. The architecture of CNNs includes layers for convolution, pooling, and full connectivity, with each layer modifying the input data in a way that enhances feature detection, making it ideal for NLP tasks like sentiment analysis [23]-[26]. Recent advances in sentiment analysis emphasize hybrid models that combine deep learning with transformer-based techniques. The proposed RoBERTa-BiLSTM, which captures both contextual and sequential information for improved classification [27]-[28]. Additionally developed an aspect-based framework for precise product recommendations, reflecting a trend toward context-aware, hybrid models [29]-[32].
METHODS
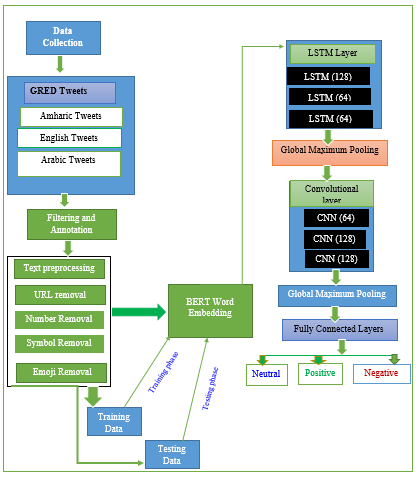
Sentiment analysis, a technique within natural language processing (NLP), is used to identify whether a piece of text expresses a positive, negative, or neutral opinion. It is commonly employed to assess public attitudes toward topics, products, and societal issues. This study examines public sentiment surrounding the Grand Ethiopian Renaissance Dam (GERD) by analyzing Twitter data through a structured process can be seen in Figure 1. The workflow starts with collecting tweets via the Tweepy library, focusing on posts in English, Amharic, and Arabic. Human annotators then categorize the tweets based on sentiment polarity: positive, negative, or neutral. The collected tweets undergo preprocessing, including tokenization, removal of stop words, and elimination of irrelevant elements such as URLs, numbers, hashtags, special characters, and emojis. Tweets in non-English languages are translated into English to standardize the dataset. Once cleaned, the dataset is divided into training and testing subsets. For sentiment prediction, the study uses the BERT model to create context-aware word embeddings. These embeddings are passed into a Long Short-Term Memory (LSTM) layer to capture the sequence of words and their relationships. A maximum pooling layer condenses the LSTM output into a fixed-size vector, which is then processed by a convolutional layer to detect local features in the text. A secondary pooling layer refines this output for final feature extraction. The resulting features are fed into a fully connected layer with a softmax function to classify the sentiment of each tweet.
The data collection (Figure 2) process involved gathering tweets from Twitter using specific keywords and hashtags related to the GERD. The selected keywords included #GERD, #Grand Ethiopian Renaissance Dam, #Renaissance Dam, #Ethiopian Dam, #السدالاستطلاعي, and #السدالاثيوبى. The Tweepy library, a Python tool for accessing the Twitter API, was used to collect around 26,000 tweets during the second filling of the GERD, capturing multilingual content. This approach aimed to analyze public sentiment or opinions regarding the dam during this period. The collected data was stored in JSON format for further analysis.
The dataset collected from Twitter on the GERD was filtered to include only English, Arabic, and Amharic tweets. Filtering was performed using Python, selecting tweets based on language codes ("en," "ar," "am"). After filtering, five annotators classified tweets into positive, negative, or neutral sentiments. Disagreements were resolved using majority voting. Preprocessing removed URLs, emojis, and special characters to improve model performance. Word embedding was applied using the multilingual BERT (mBERT) model to convert text into numerical vectors. The dataset was split into training (80 %) and testing (20 %) sets for deep learning model development. The LSTM-CNN hybrid model was chosen for sentiment classification, leveraging LSTM for sequential dependencies and CNN for feature extraction. Training included validation to prevent overfitting, using dropout and parameter tuning. Finally, model performance was evaluated on unseen data to ensure its effectiveness in classifying GERD-related sentiments.
Figure 1. Proposed System Architecture
Figure 2. Collected data
RESULT AND DISCUSSION
The dataset collected from Twitter on the GERD was filtered to include only English, Arabic, and Amharic tweets. Filtering was performed using Python, selecting tweets based on language codes ("en," "ar," "am"). After filtering, five annotators classified tweets into positive, negative, or neutral sentiments. Disagreements were resolved using majority voting. Preprocessing removed URLs, emojis, and special characters to improve model performance. Word embedding was applied using the multilingual BERT (mBERT) model to convert text into numerical vectors. The dataset was split into training (80%) and testing (20%) sets for deep learning model development. The LSTM-CNN hybrid model was chosen for sentiment classification, leveraging LSTM for sequential dependencies and CNN for feature extraction. Training included validation to prevent overfitting, using dropout and parameter tuning. Finally, model performance was evaluated on unseen data to ensure its effectiveness in classifying GERD-related sentiments.
Dataset Description
Sentiment analysis relies on user comments, opinions, and feelings regarding a specific topic. This article aims to analyze the sentiment of people, particularly those from downstream countries, regarding GERD and its construction. The dataset was collected from Twitter using the Twitter API, with over 30,000 tweets gathered based on relevant keywords and hashtags. The research team used the Tweepy library, a Python-based API, to scrape tweets. After collection, the dataset was filtered to include tweets in English, Arabic, and Amharic. Ultimately, 17,064 tweets were selected for annotation. Each tweet was manually labeled as positive, negative, or neutral. This dataset was then used to develop a multilingual sentiment analysis model.
Experimental Result
The dataset underwent preprocessing to eliminate irrelevant elements before being divided into training and testing sets, with 80 % allocated for training and 20 % for testing. The models were assessed using standard performance metrics such as accuracy, precision, recall, and loss. To analyze sentiment related to the Grand Ethiopian Renaissance Dam (GERD), three deep learning models were developed: a Convolutional Neural Network (CNN), a Long Short-Term Memory (LSTM) network, and a combined LSTM-CNN model. Training was conducted using a batch size of 46 and a learning rate of 0.001. As the task involves multi-class classification, categorical cross-entropy was used as the loss function, and the Adam optimizer was chosen for model optimization. The CNN architecture included an input layer followed by a BERT-based embedding layer. It then passed through three convolutional layers with 64, 128, and 256 filters, each using a kernel size of three. A pooling layer and dropout layer were added to reduce overfitting, and a final dense layer with a SoftMax activation function was used to output sentiment categories. This model achieved a training accuracy of 91.25% and a validation accuracy of 88.63%. The LSTM model utilized a two-layer architecture, drawing input from multilingual BERT (mBERT) embeddings. The first LSTM layer contained 128 units and generated a sequence of hidden states, while the second layer had 64 units. A dropout rate of 0.5 was applied. Trained on 11,252 tweets, the model achieved a training accuracy of 89.81% and a validation accuracy of 86.05%.
Model Evaluation Results
The model is evaluated on a test set comprising 2,814 tweets. The confusion matrices for LSTM-CNN models are shown Figure 3. For Arabic tweets, the LSTM-CNN model predicted 2,817 tweets as Negative, 633 as Positive, and 444 as Neutral. The evaluation metrics showed an accuracy of 75.5%, a precision of 79.6%, a recall of 75.4%, and anF1-score of 80.9% can be seen in Figure 4.
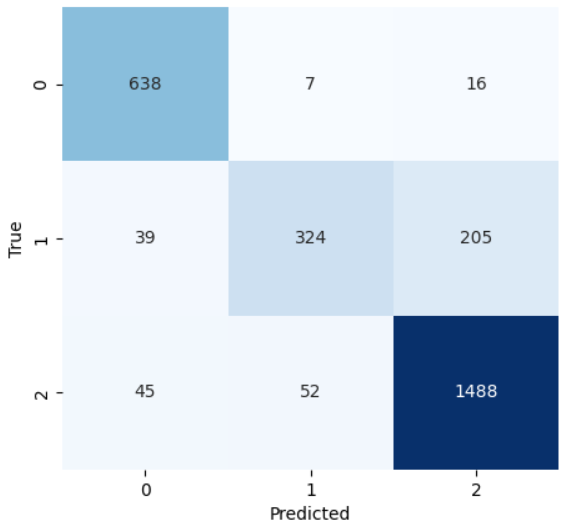
Figure 3. Confusion Matrix for LSTM-CNN
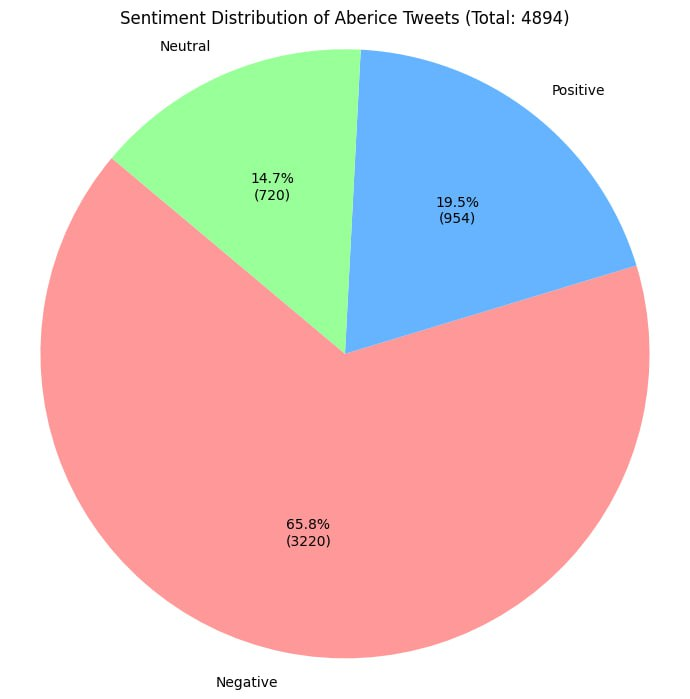
Figure 4. Evaluation of Arabic Tweets
Model Comparison
A comparison of training accuracy, test accuracy, precision, recall, and F1-score for the three models is provided Table 1 and Figure 5.
Table 1. Model Performance Comparison
Model | Training Accuracy | Validation Accuracy | Test Accuracy | Precision | Recall | F1-Score |
CNN | 92.25 | 89.31 | 89.89 | 89 | 89 | 89 |
LSTM | 90.81 | 90.94 | 87.40 | 88 | 88 | 88 |
CNN-LSTM | 96.28 | 91.99 | 92.09 | 87 | 87 | 86 |
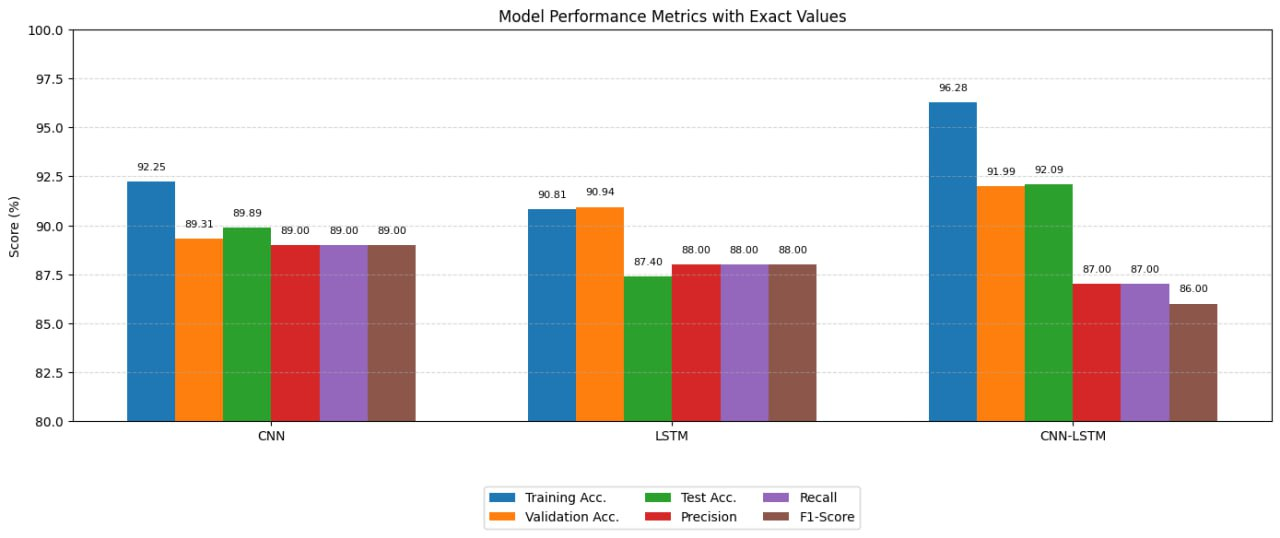
Figure 5. Model Performance Comparison
DISCUSSION
A dataset comprising 30,000 unlabeled tweets was gathered in 2024 G.C., from which 17,064 were categorized into positive, negative, or neutral sentiments. This study explores and compares three multilingual sentiment analysis models, CNN, LSTM, and a hybrid LSTM-CNN, applied to these labeled tweets in Amharic, Arabic, and English. The data was divided into 13,651 tweets for training and the remainder 3,413 for testing. The CNN model achieved 91.25% training accuracy and 89% testing accuracy. The LSTM model performed closely with training and testing accuracies of 89.81% and 88%, respectively. The hybrid LSTM-CNN model demonstrated the best performance, achieving 94.28% training accuracy and 91% testing accuracy. Despite its superior accuracy, the hybrid model exhibited slightly lower precision, recall, and F1-score compared to the individual CNN and LSTM models. Notably, it improved testing accuracy by 5.76% over the standalone models, thanks to its ability to combine local and sequential feature extraction. The study also highlights the effectiveness of multilingual BERT (mBERT) embeddings in handling sentiment analysis across languages. For instance, analysis of 4,894 Arabic tweets revealed 72% were negative, 16% positive, and 11% neutral, with an overall classification accuracy of 77.5%. In contrast, among 5,982 English tweets, 49.5% were positive, 41.3% neutral, and 9.2% negative. These findings suggest a predominantly negative sentiment in Arabic tweets about GERD, while English tweets were more balanced. Although the hybrid model proved effective, further research with larger and more diverse datasets is necessary to enhance accuracy and generalizability.
CONCLUSION
This study presents and evaluates three multilingual sentiment analysis models for assessing public opinion on the Grand Ethiopian Renaissance Dam (GERD), using a dataset of 17,064 tweets written in Amharic, Arabic, and English. From the total, 11,252 tweets were used for training, with the remainder reserved for testing. The Convolutional Neural Network (CNN) model achieved 91.25% training accuracy and 89% testing accuracy. The Long Short-Term Memory (LSTM) model followed closely with 89.81% training accuracy and 88% on the test set. The hybrid LSTM-CNN model, combining the strengths of both approaches, attained the highest training accuracy of 94.28% and a testing accuracy of 91%, though its precision, recall, and F1-score were slightly lower. The combined CNN-LSTM architecture enhanced testing accuracy by 4.76% compared to the standalone models due to improved feature extraction capabilities. Additionally, the study demonstrates the effectiveness of multilingual BERT (mBERT) embeddings for sentiment classification across languages. Analysis of 3,894 Arabic tweets showed that 72% were negative, 16% positive, and 11% neutral, with an overall accuracy of 77.5%. For 5,982 English tweets, 49.5% were positive, 41.3% neutral, and 9.2% negative. These results indicate that Arabic tweets tend to reflect more negative sentiment about GERD, whereas English tweets show a more balanced or positive tone. While the CNN-LSTM model shows promise, further research with larger and more diverse datasets is recommended to enhance performance and generalizability.
ACKNOWLEDGEMENT
We sincerely appreciate Injibara University for providing internet access.
REFERENCES
- S. Taruna and N. Bhartiya, “Parameter based Cluster Head Election in Wireless Sensor Network: A Fuzzy Approach,” International Journal of Computer Applications, vol. 106, no. 7, 2014, https://www.ijcaonline.org/archives/volume106/number7/18530-9733/.
- G. A. Endaylalu and Y. Arsano, “Grand Ethiopian Renaissance Dam Project Controversies: Understanding the role of worldviews and nexus,” African Anthropologist, vol. 22, no. 2, 2024, https://doi.org/10.4314/aa.v22i2.7.
- K. G. Wheeler, M. Jeuland, J. W. Hall, E. Zagona, and D. Whittington, “Understanding and managing new risks on the Nile with the Grand Ethiopian Renaissance Dam,” Nature communications, vol. 11, no. 1, p. 5222, 2020, https://doi.org/10.1038/s41467-020-19089-x.
- A. Pandey and D. K. Vishwakarma, "Progress, achievements, and challenges in multimodal sentiment analysis using deep learning: A survey," Applied Soft Computing, vol. 142, p. 111206, 2023, https://doi.org/10.1016/j.asoc.2023.111206.
- D. Mengistu, W. Bewket, A. Dosio, and H. J. Panitz, “Climate change impacts on water resources in the Upper Blue Nile (Abay) River Basin, Ethiopia,” J. Hydrol., vol. 592, p. 125614, 2021, https://doi.org/10.1016/j.jhydrol.2020.125614.
- T. Yeshitila, M. A. Moges, T. A. Dessalegn, and A. M. Melesse. Climate-induced flood inundation in Fogera-Dera Floodplain, Lake Tana basin, Ethiopia. Elsevier Inc. 2019. https://doi.org/10.1016/B978-0-12-815998-9.00032-4.
- M. P. McCartney and M. Menker Girma, “Evaluating the downstream implications of planned water resource development in the Ethiopian portion of the Blue Nile River,” Water Int., vol. 37, no. 4, pp. 362–379, 2012, https://doi.org/10.1080/02508060.2012.706384.
- M. El Bastawesy, S. Gabr, and I. Mohamed, “Assessment of hydrological changes in the Nile River due to the construction of Renaissance Dam in Ethiopia,” Egypt. J. Remote Sens. Sp. Sci., vol. 18, no. 1, pp. 65–75, 2015, https://doi.org/10.1016/j.ejrs.2014.11.001.
- O. Appel, F. Chiclana, J. Carter, and H. Fujita, “A hybrid approach to the sentiment analysis problem at the sentence level,” Knowledge-Based Systems, vol. 108, pp. 110-124, 2016, https://doi.org/10.1016/j.knosys.2016.05.040.
- A. T. S. To, “Department of Computer Science,” J. Comput. Appl. Math., vol. 34, no. 2, p. N14, 1991, https://doi.org/10.1016/S0377-0427(91)90073-S.
- H. Thakkar and D. Patel, “Approaches for Sentiment Analysis on Twitter: A State-of-Art study” arXiv preprint arXiv:1512.01043, 2022, https://doi.org/10.48550/arXiv.1512.01043.
- M. Heikal, M. Torki, and N. El-Makky, “Sentiment Analysis of Arabic Tweets using Deep Learning,” in Procedia Computer Science, vol. 142, pp. 114–122, 2018, https://doi.org/10.1016/j.procs.2018.10.466.
- T. Kishore and J. Praveenchandar, "An Effective Stock Market Prediction using an Advanced Machine Learning Algorithm and Emotional Analysis," 2024 3rd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), pp. 493-498, 2024, https://doi.org/10.1109/ICAAIC60222.2024.10575869.
- L. Zhang, S. Wang, and B. Liu, “Deep Learning for Sentiment Analysis: A Survey”, Wiley interdisciplinary reviews: data mining and knowledge discovery, vol. 8, no. 4, p. e1253, 2018, https://doi.org/10.1002/widm.1253.
- J. Khan, A. Alam and Y. Lee, "Intelligent Hybrid Feature Selection for Textual Sentiment Classification," in IEEE Access, vol. 9, pp. 140590-140608, 2021, https://doi.org/10.1109/ACCESS.2021.3118982.
- C. Kaushik and A. Mishra, “A Scalable, Lexicon Based Technique for Sentiment Analysis,” Int. J. Found. Comput. Sci. Technol., vol. 4, no. 5, pp. 35–56, 2014, https://doi.org/10.5121/ijfcst.2014.4504.
- D. S. Abdelminaam, N. Neggaz, I. A. E. Gomaa, F. H. Ismail and A. A. Elsawy, "ArabicDialects: An Efficient Framework for Arabic Dialects Opinion Mining on Twitter Using Optimized Deep Neural Networks," in IEEE Access, vol. 9, pp. 97079-97099, 2021, https://doi.org/10.1109/ACCESS.2021.3094173.
- M. E. Moussa, E. H. Mohamed, and M. H. Haggag, “A generic lexicon-based framework for sentiment analysis,” International Journal of Computers and Applications, vol. 42, no. 5, pp. 463-473, 2020, https://doi.org/10.1080/1206212X.2018.1483813.
- S. Gayed, S. Mallat, and M. Zrigui, “A systematic review of sentiment analysis in arabizi,” In International KES Conference on Intelligent Decision Technologies, pp. 128-133, 2023, https://doi.org/10.1007/978-981-99-2969-6_11.
- N. Khalifa and H. Kadhem, "A Development of a Sentiment Analysis Model for the Bahraini Dialects," 2024 Arab ICT Conference (AICTC), pp. 44-51, 2024, https://doi.org/10.1109/AICTC58357.2024.10735036.
- J. H. Yu, and D. Chauhan, “Trends in NLP for personalized learning: LDA and sentiment analysis insights,” Education and Information Technologies, vol. 30, no. 4, pp. 4307-4348, 2025, https://doi.org/10.1007/s10639-024-12988-2.
- M. G. Astarkie, B. Bala, G. J. Bharat Kumar, S. Gangone, & Y. Nagesh, “A novel approach for sentiment analysis and opinion mining on social media tweets,” In Proceedings of the International Conference on Cognitive and Intelligent Computing: ICCIC 2021, vol. 2, pp. 143-151, 2023, https://doi.org/10.1007/978-981-19-2358-6_15.
- K. Du, F. Xing, R. Mao, and E. Cambria, "Financial Sentiment Analysis: Techniques and Applications," ACM Computing Surveys, vol. 56, no. 9, pp. 1–42, 2024, https://doi.org/10.1145/3649451.
- J. R. Jim, M. A. R. Talukder, P. Malakar, M. M. Kabir, K. Nur, and M. F. Mridha, "Recent advancements and challenges of NLP-based sentiment analysis: A state-of-the-art review," Natural Language Processing Journal, vol. 4, p. 100059, 2024, https://doi.org/10.1016/j.nlp.2024.100059.
- Y. Mao, Q. Liu, and Y. Zhang, "Sentiment analysis methods, applications, and challenges: A systematic literature review," Journal of King Saud University - Computer and Information Sciences, vol. 36, p. 102048, 2024, https://doi.org/10.1016/j.jksuci.2024.102048.
- Y. Mao, Q. Liu, and Y. Zhang, "Sentiment analysis methods, applications, and challenges: A systematic literature review," Journal of King Saud University - Computer and Information Sciences, vol. 36, p. 102048. 2024, https://doi.org/10.1016/j.jksuci.2024.102048.
- M. M. Rahman, A. I. Shiplu, Y. Watanobe and M. A. Alam, "RoBERTa-BiLSTM: A Context-Aware Hybrid Model for Sentiment Analysis," in IEEE Transactions on Emerging Topics in Computational Intelligence, 2025, https://doi.org/10.1109/TETCI.2025.3572150.
- S. T. Eberhardt, J. Schaffrath, D. Moggia, B. Schwartz, M. Jaehde, and J. A. Rubel, “Decoding emotions: Exploring the validity of sentiment analysis in psychotherapy,” Psychotherapy Research, vol. 34, no. 2, pp. 174–189, 2024, https://doi.org/10.1080/10503307.2024.2322522.
- N. Darraz, I. Karabila, A. El-Ansari, N. Alami, and M. El Mallahi, “Integrated sentiment analysis with BERT for enhanced hybrid recommendation systems,” Expert Syst. Appl., vol. 240, p. 125533, 2024, https://doi.org/10.1016/j.eswa.2024.125533.
- N. C. Hellwig, J. Fehle, and C. Wolff, “Exploring large language models for the generation of synthetic training samples for aspect-based sentiment analysis in low resource settings,” Expert Syst. Appl., vol. 244, p. 125871, 2024, https://doi.org/10.1016/j.eswa.2024.125871.
- R. K. Ray and A. Singh, “From online reviews to smartwatch recommendation: An integrated aspect-based sentiment analysis framework,” Expert Syst. Appl., vol. 243, p. 125809, 2024, https://doi.org/10.1016/j.eswa.2024.125809.
- Y. Li, X. Lan, H. Chen, K. Lu, and D. Jiang, “Multimodal PEAR chain-of-thought reasoning for multimodal sentiment analysis,” ACM Trans. Multimedia Comput. Commun. Appl., vol. 20, no. 9, pp. 1–23, 2024, https://doi.org/10.1145/3672398.
AUTHOR BIOGRAPHY

| Atinkut Molla Mekonnen obtained his Bachelor’s degree from Wollo University Kombolcha Institute of Technology (KIoT), Ethiopia in 2017, specializing in Information Technology. Later, he earned a Master’s degree from the same university in Computer Networks and Communications in 2019. Currently, he works as a lecturer and researcher in the Department of Information Technology at the College of Engineering and Technology, Injibara University, Injibara, Ethiopia. His fields of research include Computer Networks, IoT, AI, as well as Machine learning and Deep learning. His email: Atinkut.Molla@inu.edu.et |
|
|

| Yirga Yayeh Munaye (PhD) received a B.Sc. degree in information technology from Bahir Dar University, Bahir Dar, Ethiopia 2009, M.Sc. degree in information science from Addis Ababa University, Ethiopia, in 2014, and a Ph.D. degree from the Department of Electrical Engineering and Computer Science, National Taipei University of Technology, Taipei, Taiwan, in 2021. Since 2021, an Assistant Professor and Chair unit leader for Network and Internet in the Faculty of Computing, Bahir Dar Institute of Technology, Bahir Dar University. Moreover, since December 2022, date have been an Assistant professor and postgraduate, research, and community service coordinator at Injibara University, Ethiopia. He can be contacted at email: Yirga.Yayeh@inu.edu.et |
|
|

| Yenework Belayneh Chekol received her BSc. in Information Technology from Debre Markos University, Ethiopia, and MSc. in Information Science at Addis Ababa University, Addis Ababa, Ethiopia. She is currently working as a. lecturer (Instructor and Researcher) at Injibara University, Ethiopia (Since November 2018 till now). Library Directorate Director, Injibara University (Since April 14, 2021 to date). Department head for computer science, Injibara university (From November 10, 2020, to December 07, 2021 ) Department head for Information Technology, Injibara university (From December 08, 2021, to February 13, 2021) Assistant lecturer II, Assosa University (Since August 08, 2014 to July 18, 2015 ).Assistant lecturer, Assosa University (From August 08, 2015 to October 09, 2015 )Lecturer, Assosa University ( July 2017 October 2018)Lecturer and Gender Affairs coordinator at Faculty of Engineering and Technology, Assosa University, Ethiopia. (July 2017—October 2018) Instructor and Gender Affairs coordinator, Faculty of Informatics at Assosa University (July 2014- September 2015). She can be contacted at email: Yenework.Belayneh@inu.edu.et |
Buletin Ilmiah Sarjana Teknik Elektro, Vol. 7, No. 2, June 2025, pp. 206-213