
Clustering Indonesian provinces based on welfare level using several validity indices
DOI:
https://doi.org/10.12928/bamme.v6i1.15817Keywords:
clustering, Fuzzy C-Means , K-Means, level of welfare, validityAbstract
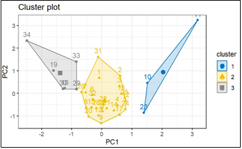
One of the national development goals is to increase the level of community welfare. There are several aspects that influence the level of welfare, namely population, health, education, housing, social, employment, consumption, and poverty. This research aims to group provinces in Indonesia based on their level of welfare so that the government can determine appropriate policies in the context of economic recovery and improving the welfare of the Indonesian people. The data used are indicators of provincial welfare levels in Indonesia in 2022 from the Central Statistics Agency. Data is grouped into 3 clusters based on welfare level, namely high (C1), medium (C2), and low (C3) using the K-Means and Fuzzy C-Means methods. Based on the results of the validity test, it is known that ththe best method is the K-Means method with Euclidean distance using the parameter k = 3, the resulting DBI value is 0.989 and the C-Index is 0.076, where this value is better than those of the Fuzzy C-Means method. It is hoped that the results can provide information regarding the characteristics of provinces in Indonesia based on welfare level indicators and become a reference for the government in improving welfare in Indonesia.
References
Alfarera, M. A. (2024). Analysis of Malang University student achievement grouping using the K-Means clustering method. Journal of Electrical Engineering and Computer Sciences, 9(2), 159-172.
Cunningham, P. (2008). Unsupervised learning and clustering. In D. Greene, P. Cunningham, & R. Mayer, Machine Learning Techniques for Multimedia (pp. 51-90). Springer.
Dahnial. (2023). Implementation of K-Means clustering method to lecturers based on publications af national journals and accredited sinta. Journal of Electrical Engineering and Computer Sciences, 8(1), 27-40.
Febrianto, N. I., & Palasara, N. (2019). Analisis clustering K-Means pada data informasi kemiskinan di Jawa Barat Tahun 2018. Jurnal Sisfokom, 8(2), 130-140.
Fitriani, D., Padilah, T. N., & Sari, B. N. (2021). Penerapan algoritma K-Means dalam pengelompokan kesejahteraan rakyat berdasarkan kecamatan di Kabupaten Karawang. Progresif: Jurnal Ilmu Komputer, 17(2).
Garini, F. C., Anbiya, W., & Purwandari, P. (2022). Optimalisasi pengelompokan provinsi di indonesia berdasarkan indikator kesejahteraan rakyat. Seminar Nasional Statistika Aktuaria I (pp. 1-10). Departemen Statistika FMIPA Universitas Padjadjaran.
Ikotun, A. M., Habyarimana, F., & Ezugwu, A. E. (2025). Benchmarking validity indices for evolutionary K-means clustering performance. Nature Portfolio.
Indah, Y. M., & Octaviana, S. (2025). Analisis perbandingan metode klaster hierarki dan non-hierarki terhadap tingkat pengangguran di pulau Jawa Tahun 2023. BIAStatistics: Journal Of Statistics Theory and Aplications, 19(1), 92-104.
Kembaren, R. C., Sitompul, O. S., & Sawaluddin. (2022). Analysis clustering using normalized cross correlation in Fuzzy C-Means clustering algorithm. Sinkron :Jurnal dan Penelitian Teknik Informatika, 6(4), 2262-2271.
Malikhatin, H., Rusgiyono, A., & Maruddani, D. A. (2021). Penerapan K-Modes clustering dengan validasi dunn index pada pengelompokan karakteristik calon TKI Menggunakan R-GUI. Jurnal Gaussian, 10(3), 359-366.
Mustakim, Aini, D. N., Batubara, A. U., Erkamim, M., & Legito. (2023). Fuzzy clustering-based grouping for mapping the distribution of student success data. MALCOM: Indonesian Journal of Machine Learning and Computer Science, 3(2), 366-372.
Nishom, M. (2019). Perbandingan akurasi euclidean distance, minkowski distance, dan manhattan distance pada algoritma K-Means clustering berbasis Chi-Square. Jurnal Informatika: Jurnal Pengembangan IT (JPIT), 4(1), 20-24.
Nugraha, A., Asnawi, M., & Purwandari, T. (2021). Analisis klaster hirarki untuk mengelompokkan provinsi di indonesia berdasarkan indikator kesejahteraan rakyat. Seminar Nasional Statistika X. Dept. Statistika FMIPA Universitas Padjadjaran.
Prihandoko, Jollyta, D., Gusrianty, Siddik, M., & Johan. (2024). Cluster validity for optimizing classification model: davies bouldin index – random forest algorithm. Matrik: Jurnal Manajemen, Teknik Informatika, dan Rekayasa Komputer, 24(1), 61-72.
Saidah, D. A., Santoso, R., & Widiharih, T. (2022). Pengelompokan provinsi di indonesia berdasarkan indikator kesehatan lingkungan menggunakan metode partitioning around medoids dengan validasi indeks internal. Journal Gaussian, 11(2), 302-312.
Sary, R. A., Satyahadewi, N., & Andani, W. (2024). Application of K-Means++ with dunn index validation of grouping West Kalimantan region based on crime vulnerability. BAREKENG: Journal of Mathematics and Its Applications, 18(4), 2283–2292.
Suraya, G., & Wijayanto, A. W. (2022). Comparison of hierarchical clustering, K-Means, K-Medoids, and Fuzzy C-Means Methods in grouping provinces in indonesia according to the special index for handling stunting. Indonesian Journal of Statistics and Its Applications, 6(2), 180-201.
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Yudi Setyawan, Maria Kristina Yolanda Hawa, Kris Suryowati

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under Creative Commons Attribution License that allows others to share the work with an acknowledgement of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgement of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See The Effect of Open Access).


