
Optimization of feature selection on semi-supervised data
DOI:
https://doi.org/10.12928/bamme.v4i1.11104Keywords:
classification, feature selection, particle swarm optimization, semi-supervised dataAbstract
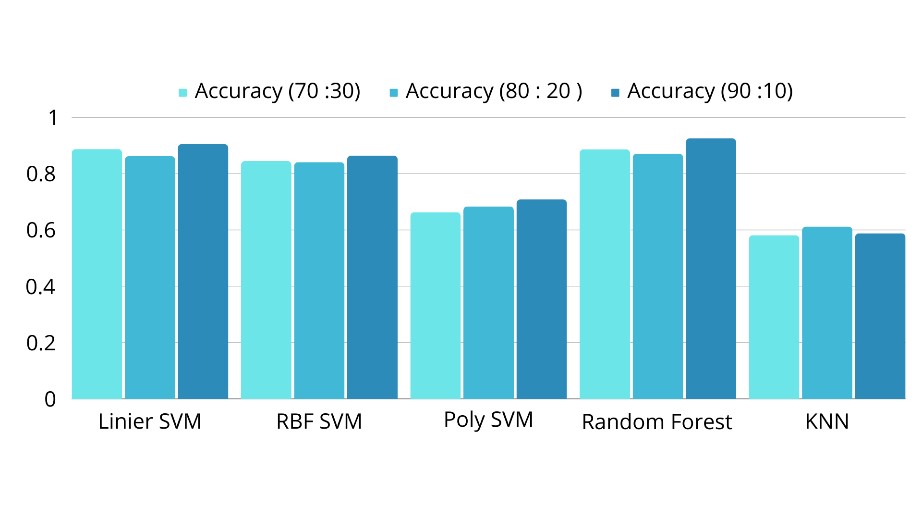
This research explores feature selection optimization in semi-supervised text data by utilizing the technique of dividing data into training and testing sets and implementing pseudo-labeling. Proportions of data division, namely 70:30, 80:20, and 90:10, were used as experiments, employing TF-IDF weighting and PSO feature selection. Pseudo-labeling was applied by assigning positive, negative, and neutral labels to the training data to enrich information in the classification model during the testing phase. The research results indicate that the linear SVM model achieved the highest accuracy with a 90:10 data division proportion with a value of 0.9051, followed by Random Forest, which had an accuracy of 0.9254. Although RBF SVM and Poly SVM yielded good results, KNN showed lower performance. These findings emphasize the importance of feature selection strategies and the use of pseudo-labeling to enhance the performance of classification models in semi-supervised text data, offering potential applications across various domains that rely on semi-supervised text analysis.
References
Abdi, A., Shamsuddin, S. M., Hasan, S., & Piran, J. (2019). Deep learning-based sentiment classification of evaluative text based on multi-feature fusion. Information Processing & Management, 56(4), 1245-1259.
Abualigah, L. M., Khader, A. T., & Hanandeh, E. S. (2018). A new feature selection method to improve the document clustering using particle swarm optimization algorithm. Journal of Computational Science, 25, 456-466.
Adnan, K., & Akbar, R. (2019). An analytical study of information extraction from unstructured and multidimensional big data. Journal of Big Data, 6(1), 1-38.
Addiga, A., & Bagui, S. (2022). Sentiment analysis on Twitter data using term frequency- inverse document frequency. Journal of Computer and Communications, 10(8), 117-128.
Ahmed, Z., Mohamed, K., Zeeshan, S., & Dong, X. (2020). Artificial intelligence with multi- functional machine learning platform development for better healthcare and precision medicine. Database, 2020, baaa010.
Ahuja, R., Chug, A., Kohli, S., Gupta, S., & Ahuja, P. (2019). The impact of features extraction on the sentiment analysis. Procedia Computer Science, 152, 341-348.
Anuradha, T., Tigadi, A., Ravikumar, M., Nalajala, P., Hemavathi, S., & Dash, M. (2022). Feature extraction and representation learning via deep neural network. In Computer Networks, Big Data and IoT: Proceedings of ICCBI 2021 (pp. 551-564). Springer Nature Singapore.
Asri, A. M., Ahmad, S. R., & Yusop, N. M. M. (2023). Feature selection using particle swarm optimization for sentiment analysis of drug reviews. International Journal of Advanced Computer Science and Applications, 14(5).
Birjali, M., Kasri, M., & Beni-Hssane, A. (2021). A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowledge-Based Systems, 226, 107134.
Calma, A., Reitmaier, T., & Sick, B. (2018). Semi-supervised active learning for support vector machines: A novel approach that exploits structure information in data. Information Sciences, 456, 13-33.
Chai, C. P. (2023). Comparison of text preprocessing methods. Natural Language Engineering, 29(3), 509-553.
Ghani, N. A., Hamid, S., Hashem, I. A. T., & Ahmed, E. (2019). Social media big data analytics: A survey. Computers in Human Behavior, 101, 417-428.
Jan, B., Farman, H., Khan, M., Imran, M., Islam, I. U., Ahmad, A. & Jeon, G. (2019). Deep learning in big data analytics: A comparative study. Computers & Electrical Engineering, 75, 275- 287.
Lee, V. L. S., Gan, K. H., Tan, T. P., & Abdullah, R. (2019). Semi-supervised learning for sentiment classification using small number of labeled data. Procedia Computer Science, 161, 577- 584.
Liu, Y., Xu, Z., & Li, C. (2018). Online semi-supervised support vector machine. Information Sciences, 439, 125-141.
Mo, Y., Zhao, D., Du, J., Syal, M., Aziz, A., & Li, H. (2020). Automated staff assignment for building maintenance using natural language processing. Automation in Construction, 113, 103150.
Nahid, A. A., Sikder, N., Abid, M. H., Toma, R. N., Talin, I. A., & Lasker, E. A. (2022). Home occupancy classification using machine learning techniques along with feature selection. International Journal of Engineering and Manufacturing, 12(3), 38.
Ning, C., & You, F. (2019). Optimization under uncertainty in the era of big data and deep learning: When machine learning meets mathematical programming. Computers & Chemical Engineering, 125, 434-448.
Ouali, Y., Hudelot, C., & Tami, M. (2020). An overview of deep semi-supervised learning. arXiv preprint. arXiv:2006.05278.
Sengupta, S., Basak, S., & Peters, R. A. (2018). Particle Swarm Optimization: A survey of historical and recent developments with hybridization perspectives. Machine Learning and Knowledge Extraction, 1(1), 157-191.
Sriram, S. (2020). An evaluation of text representation techniques for fake news detection using: TF-IDF, word embeddings, sentence embeddings with linear support vector machine. Dissertation. TU Dublin.
Van Engelen, J. E., & Hoos, H. H. (2020). A survey on semi-supervised learning. Machine Learning, 109(2), 373-440.
Wang, D., Su, J., & Yu, H. (2020). Feature extraction and analysis of natural language processing for deep learning English language. IEEE Access, 8, 46335-46345.
Zebari, R., Abdulazeez, A., Zeebaree, D., Zebari, D., & Saeed, J. (2020). A comprehensive review of dimensionality reduction technsiques for feature selection and feature extraction. Journal of Applied Science and Technology Trends, 1(2), 56-70.
Zepf, S., Hernandez, J., Schmitt, A., Minker, W., & Picard, R. W. (2020). Driver emotion recognition for intelligent vehicles: A survey. ACM Computing Surveys (CSUR), 53(3), 1-30.
Downloads
Published
Issue
Section
License
Copyright (c) 2024 Dian Eka Wijayanti, Sintia Afriyani, Sugiyarto Surono; Deshinta Arrova Dewi

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Authors who publish with this journal agree to the following terms:
- Authors retain copyright and grant the journal right of first publication with the work simultaneously licensed under Creative Commons Attribution License that allows others to share the work with an acknowledgement of the work's authorship and initial publication in this journal.
- Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the journal's published version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgement of its initial publication in this journal.
- Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See The Effect of Open Access).


